Hi,
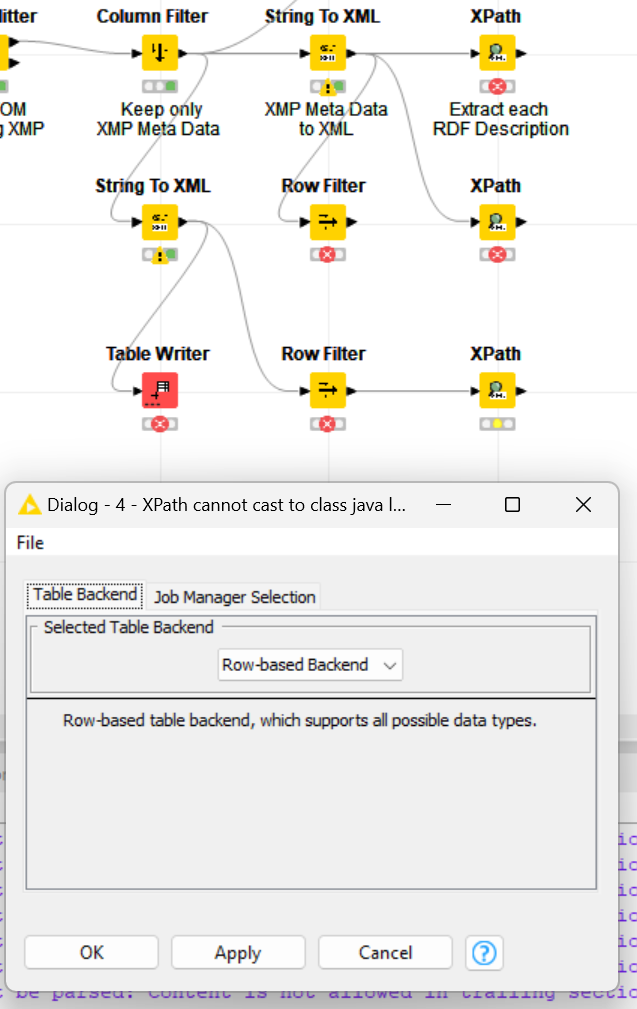
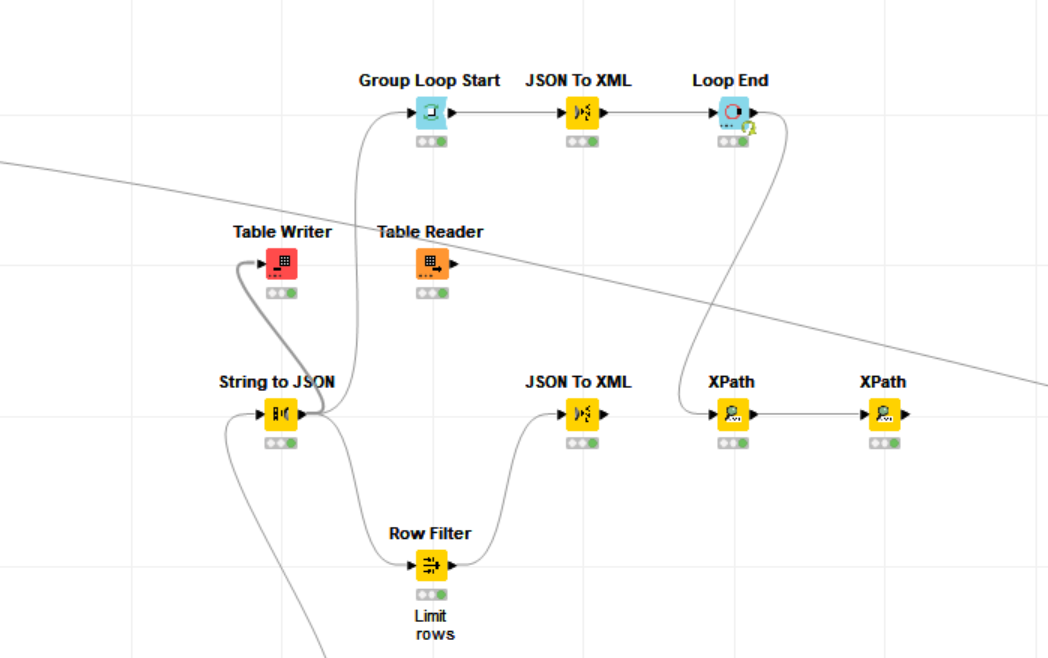
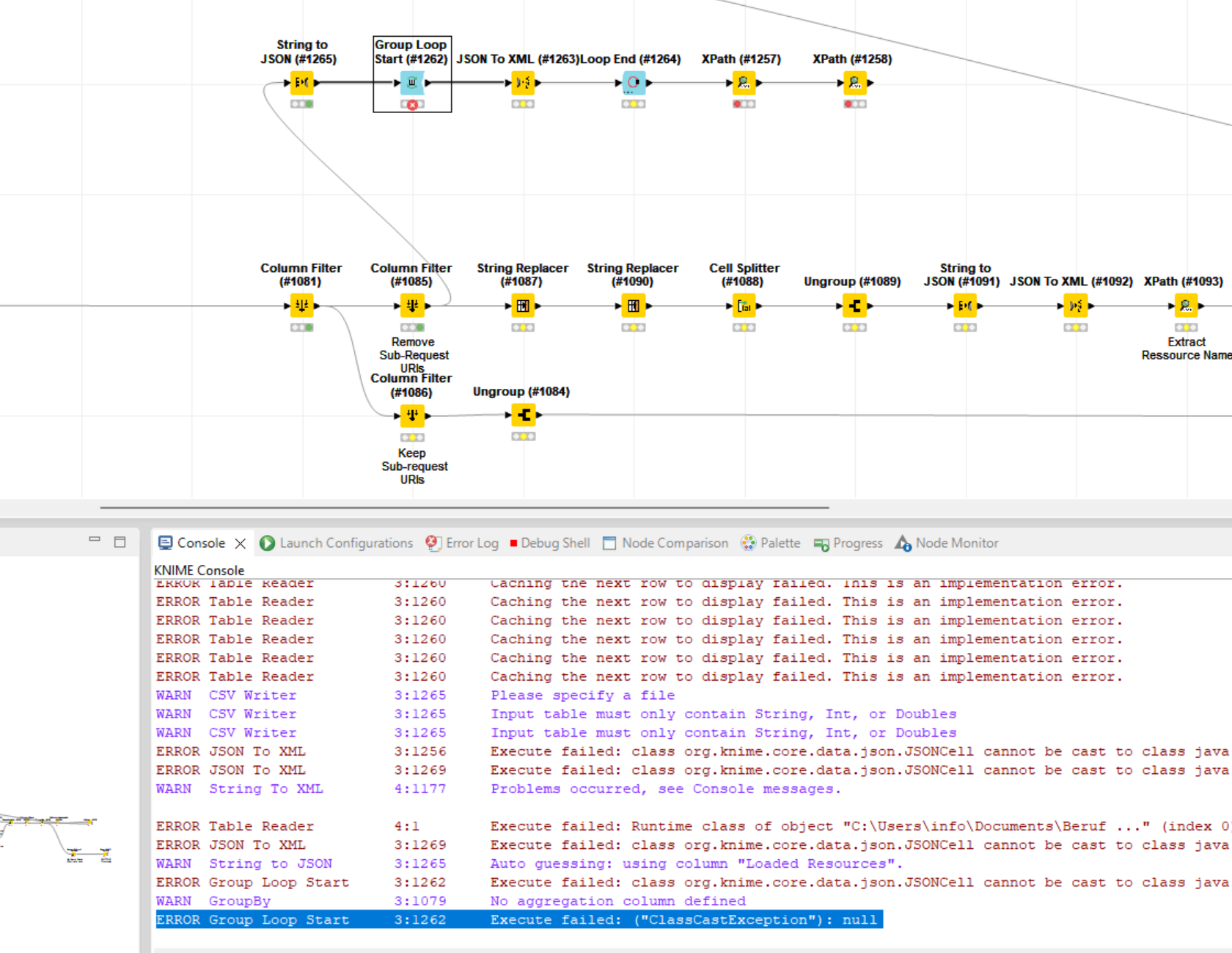
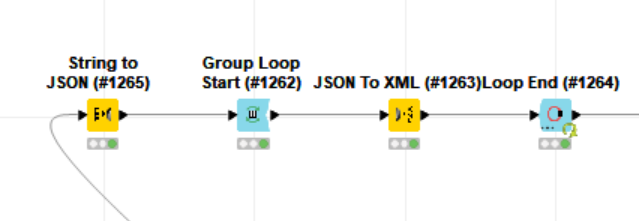
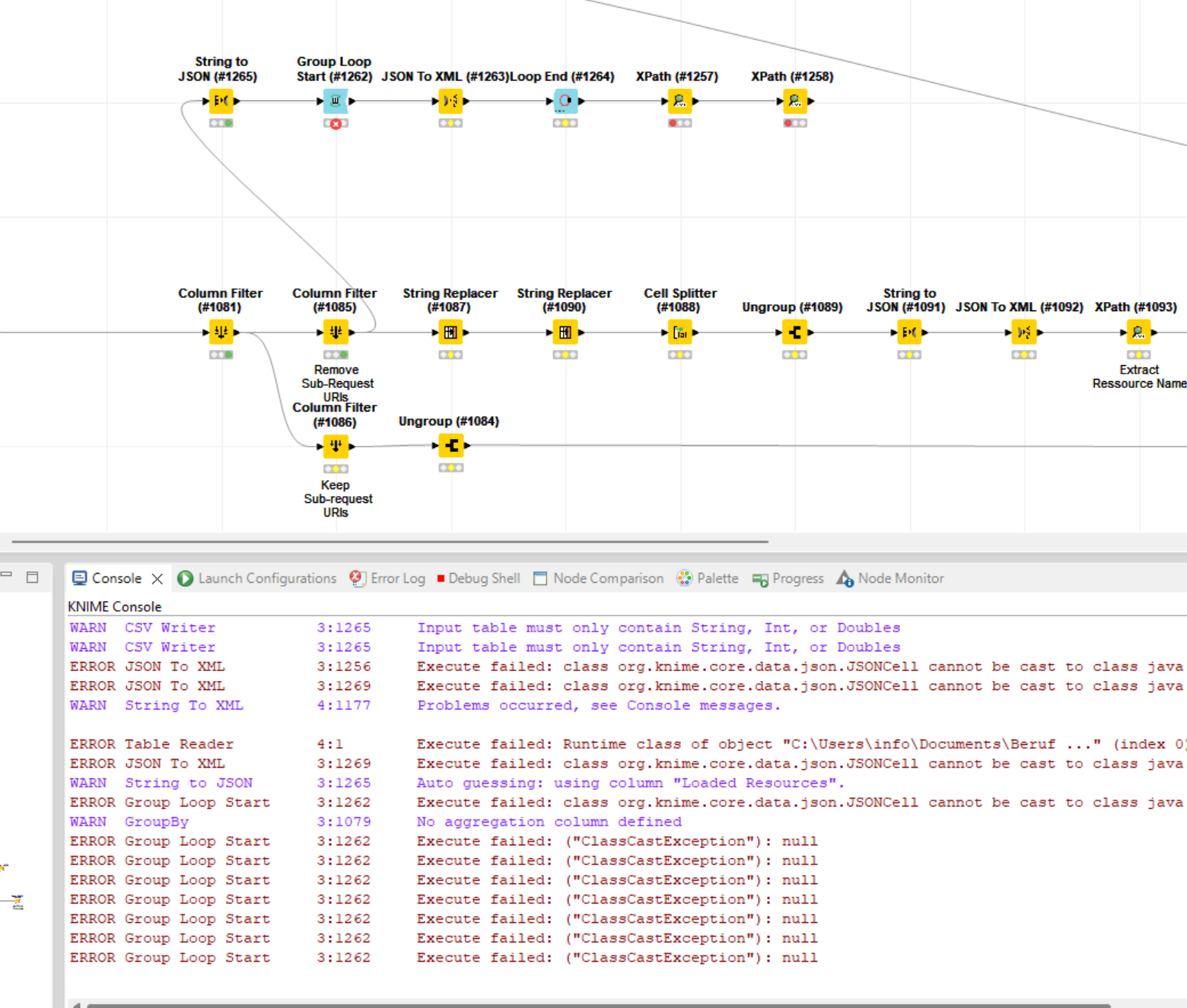
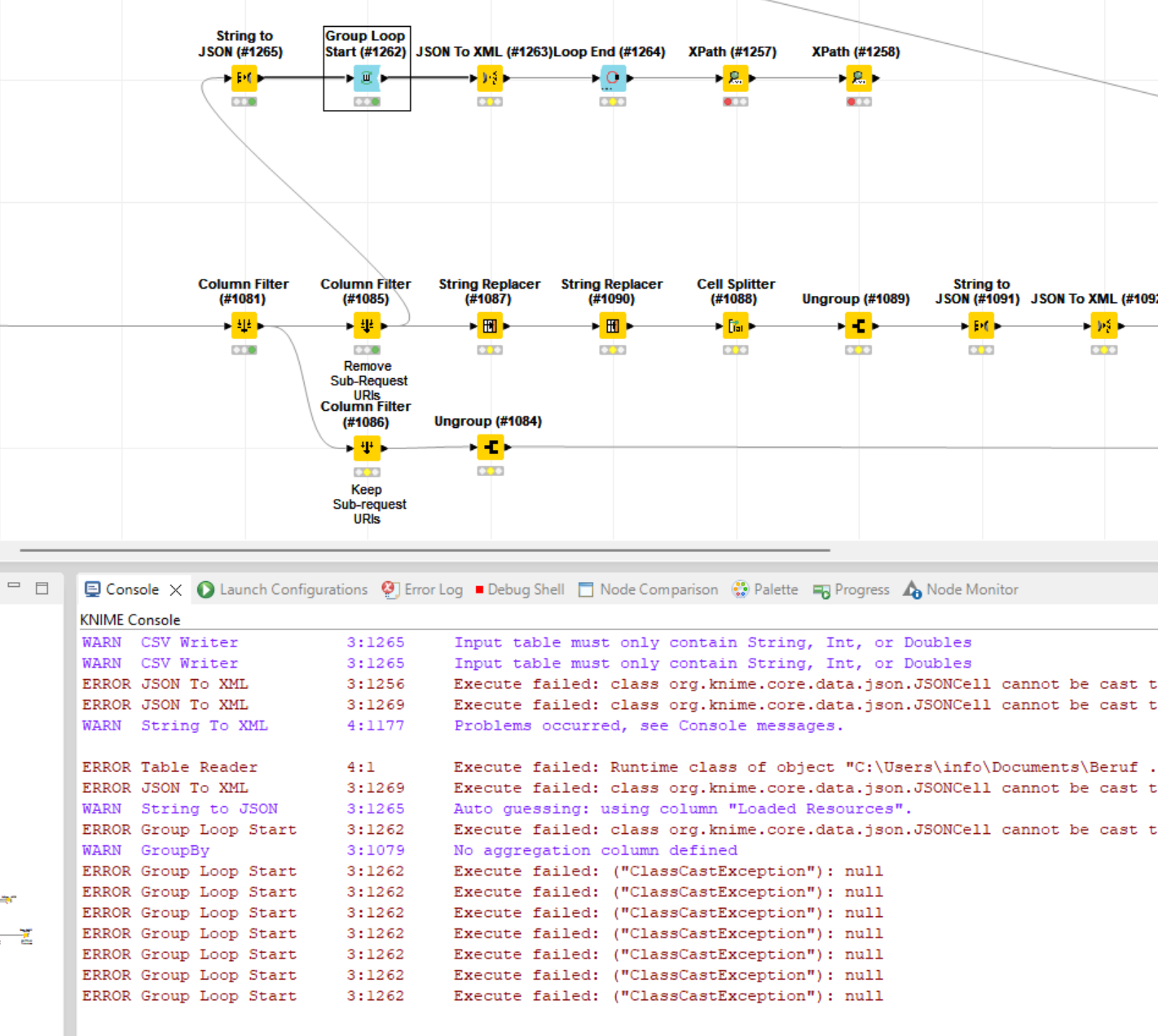
I stumbled across this error which did not appear using the default row based backend. There is another error thrown before which did make no sense to me as the XPath Config did not exported anything of the type int but only node cells, though. The Xpath also comes right after the node which did throw the error in question but I include it just for the greater picture.
ERROR XPath 3:1178 Execute failed: class org.knime.core.data.xml.XMLCell cannot be cast to class java.lang.Integer (org.knime.core.data.xml.XMLCell is in unnamed module of loader org.eclipse.osgi.internal.loader.EquinoxClassLoader @29532e91; java.lang.Integer is in module java.base of loader 'bootstrap')
ERROR XPath 3:1178 Execute failed: class org.knime.core.data.xml.XMLCell cannot be cast to class java.lang.Integer (org.knime.core.data.xml.XMLCell is in unnamed module of loader org.eclipse.osgi.internal.loader.EquinoxClassLoader @29532e91; java.lang.Integer is in module java.base of loader 'bootstrap')
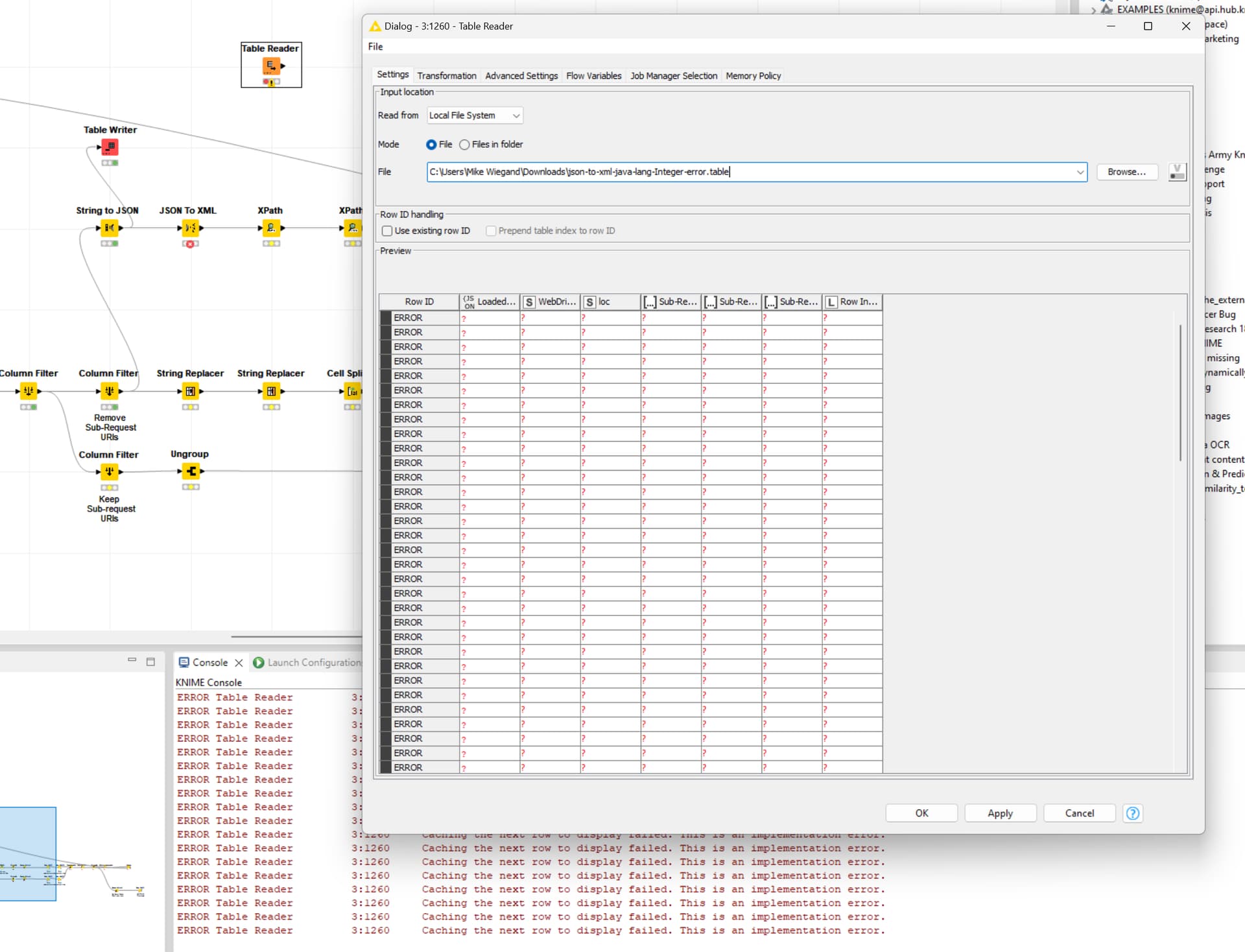
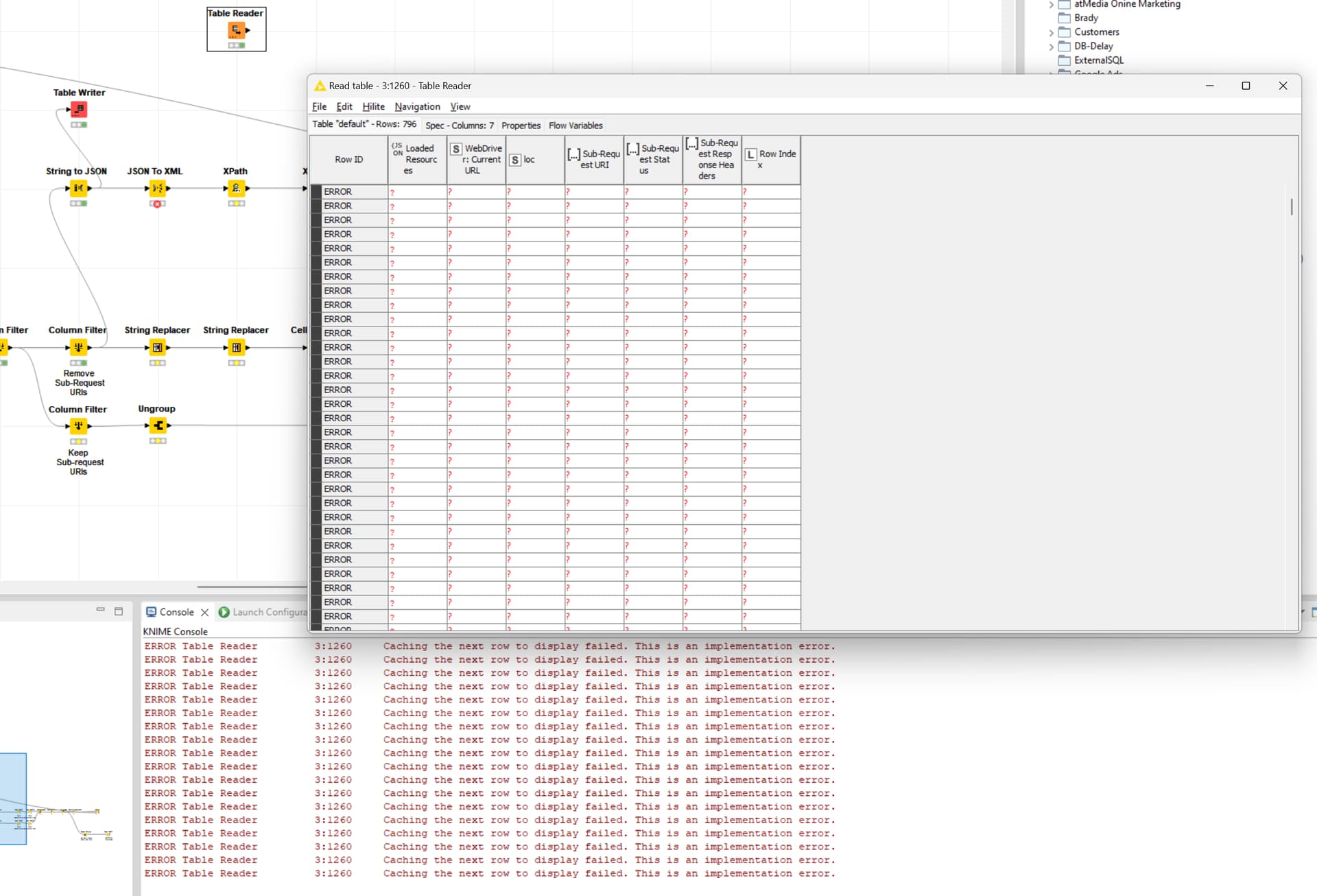
ERROR String To XML 3:1177 Caching the next row to display failed. This is an implementation error.
Error with table preview
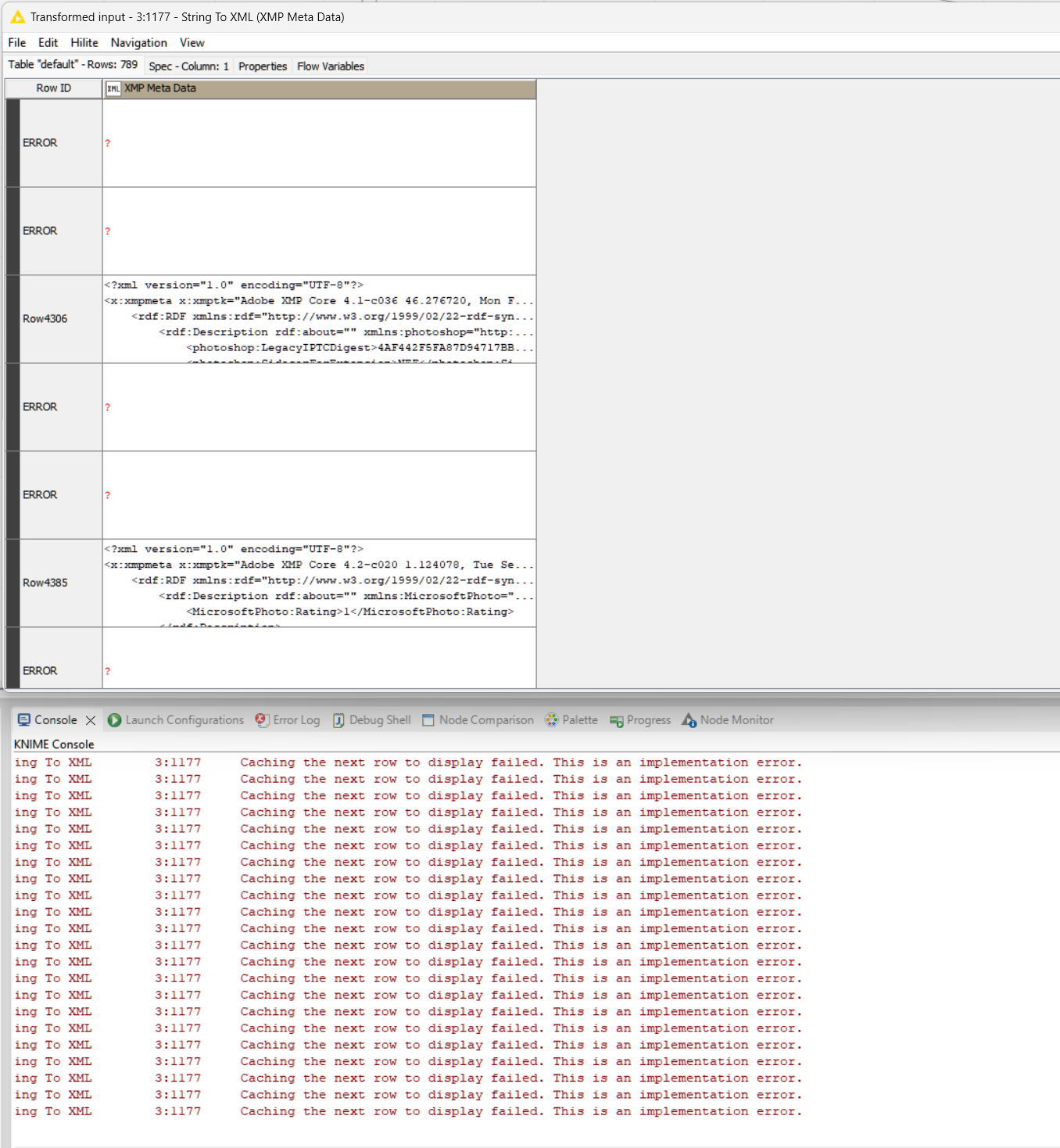
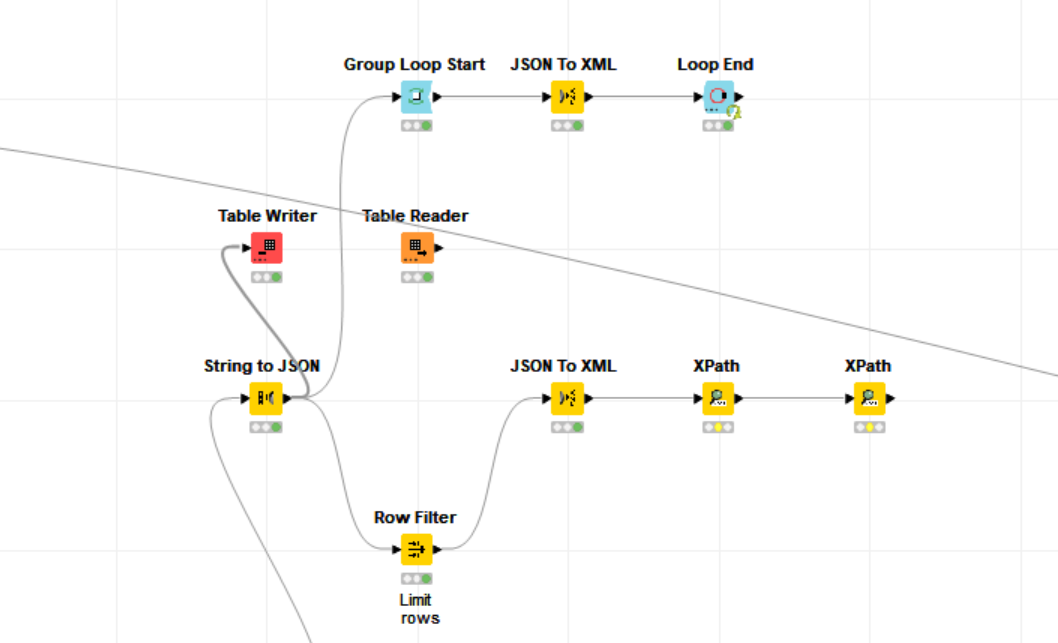
My attempts to reproduce the issue were not successful but maybe anyone of the Knime team can draw some conclusions.
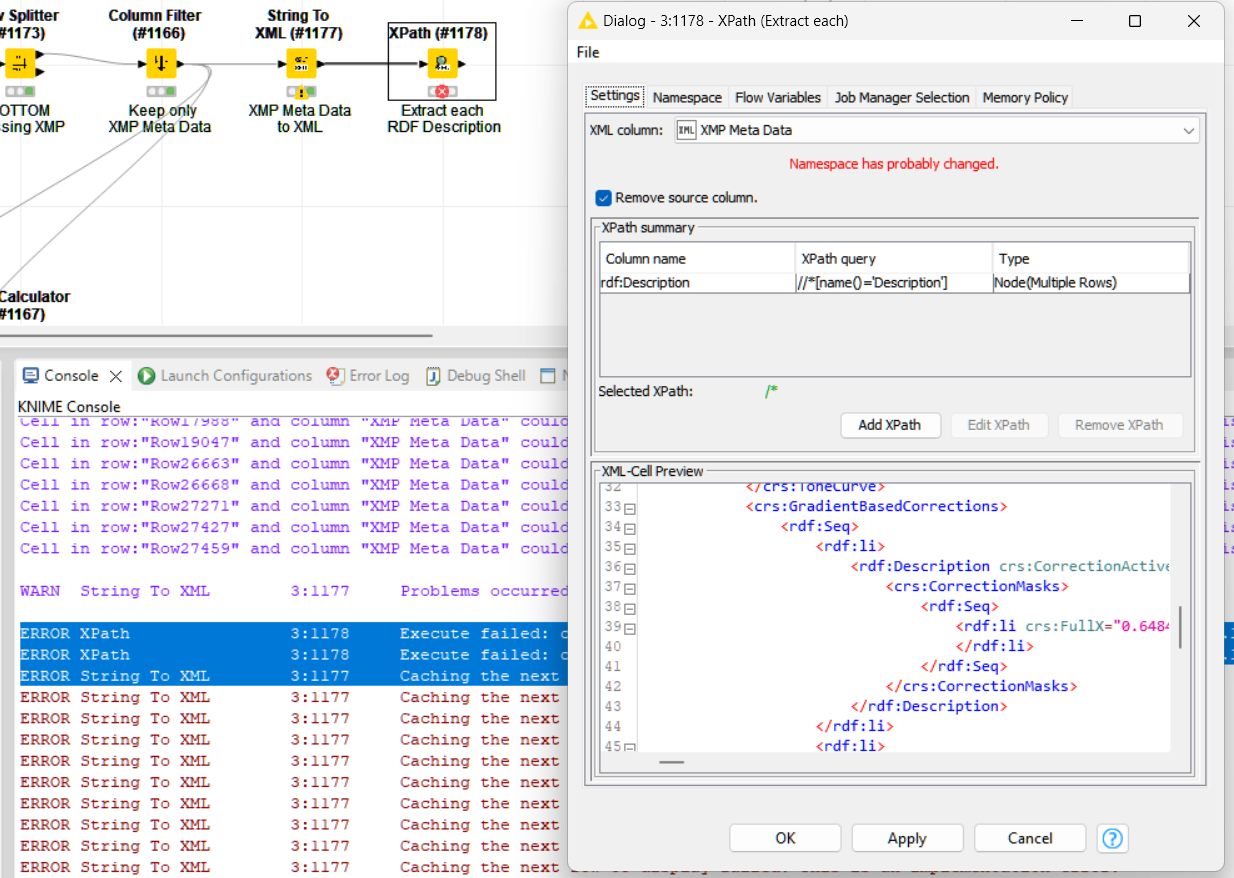
Likely unrelated XPath error just for completeness
Best
Mike