In a workflow about identifying duplicated images which contains tables with images (about 800 MB to 1 GB), their corresponding binary object and the binary object as a string, I am unable to preview the data when I have the new columnar backend enabled.
The data preview actually never finished loading and the preview windows I was unable to close requiring me to force kill Knime. I am tryig to create a test workflow which I will upload, if sucessfull, later. But due to the nature of Knime being required to get force quit, this is rather “challenging”.
PS: The preview window suddenly closed. It seems my request to close it got registered and magically executed.
PPS: A presumably very positive change about the columnar backend is the roughly 100 % higher disc read throughput. Whilst neither a quantitative nor qualitative anylsis, I only managed to get about 800 MB throughput peak with the default row based backend. The columnar one manages to read >1.6 GB / sec.
However, displaying the table data seems to take considerably more time. After saving and restarting I did another test and it took about 5 Minutes to display the data. A test workflow indicated that it seems to correlate with the amount of the data which the table holds.
Whilist the images are online accessible, it would stress my bill a bit too much. I could however provide you an AWS S3 download link for testing purposes if you “pinky” promise to not … joke aside. Let me know how’d like to proceed.
Thanks again for all your reports and your patience, highly appreciated!
This is very interesting. I’ll send you a PM to get the workflow + data so we can investigate.
Update: I have to rectify my initial “complaint”. Whilst the issue seems to have been caused by the columnar backend - please note that I took utmost care by resetting, regenerating saving the workflow, closing and repoening - the issue was caused too while back testing again.
As follows the test workflow but w/o the sensitive customer data (shared via PM with the Knime team). Please note that I possibly tracked the issue down to lots of string data being present (1.3 GB) while investigating about a general Knime instability:
Sorry for the “spamming” but I got yet again a new symptom. Trying to open another workflow after switching back to the default row based backend, worth to note that I did not reset and calculated the data, loading the workflow does never finish.
I was on a walk for about 20 minutes with my little one and it seems hung. Little to no IO, constant CPU usage despite (presumably) nothing happening in the background.
As you have noticed yourself, the preview of the table is busy rendering very long strings.
Thanks @mwiegand for sending me your workflow. I could observe the behavior as well. When I tried @wiswedel’s fix in the current nightly the table preview loads much faster. It is still noticeable when scrolling that loading and displaying the long strings takes some time – which makes sense as it still needs to display a lot of data – but it does not get stuck.
For the time being, it would be best to filter out the string column that contains the binary representation of the image before looking at the table view. I’d argue that this column is not very human readable anyways…
Trying to open another workflow after switching back to the default row based backend, worth to note that I did not reset and calculated the data, loading the workflow does never finish.
I’m not sure whether I got this right. Is step 2 what you were saying?
you had workflow A open which used the columnar backend
you re-configure this workflow to use the row-based backend (this does reset all nodes)
you try to open workflow B, but this never finishes?
Changing Knime‘s backen from default row based to new columnar backend never reset any workflow for me. Not the open ones while changing the setting nor after saving, close and reopen the very same workflow and also not those I had not open for a while.
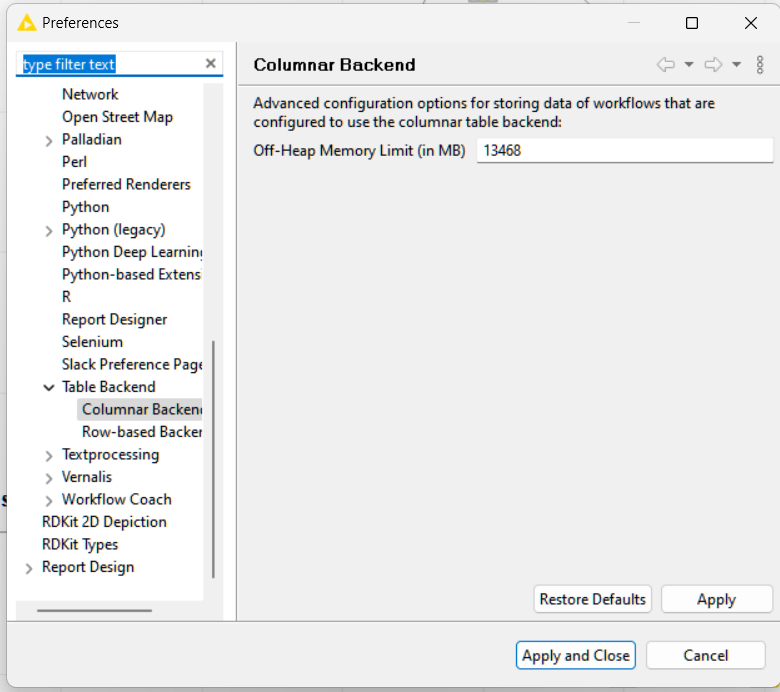
I was always required to manually reset, thought. The only discernible difference I believe to have recognized is a progress bar, left to the heap space indicator, which I believe indicates the amount of consumed memory for the columnar backend.
Worth to note that this barely increased regardless of the data and amount I was processing or inspecting via preview. Knime set the amount of allocated memory to about 13 GB which I never adjusted.
I will check the nighty build later today. Currently I am on a walk so my little son falls asleep.
I tried to try the nighty build but ran into another issue I reported being caused by prev. Knime versions but this time it also struck for the latest:
Changing Knime‘s backen from default row based to new columnar backend never reset any workflow for me. Not the open ones while changing the setting nor after saving, close and reopen the very same workflow and also not those I had not open for a while.
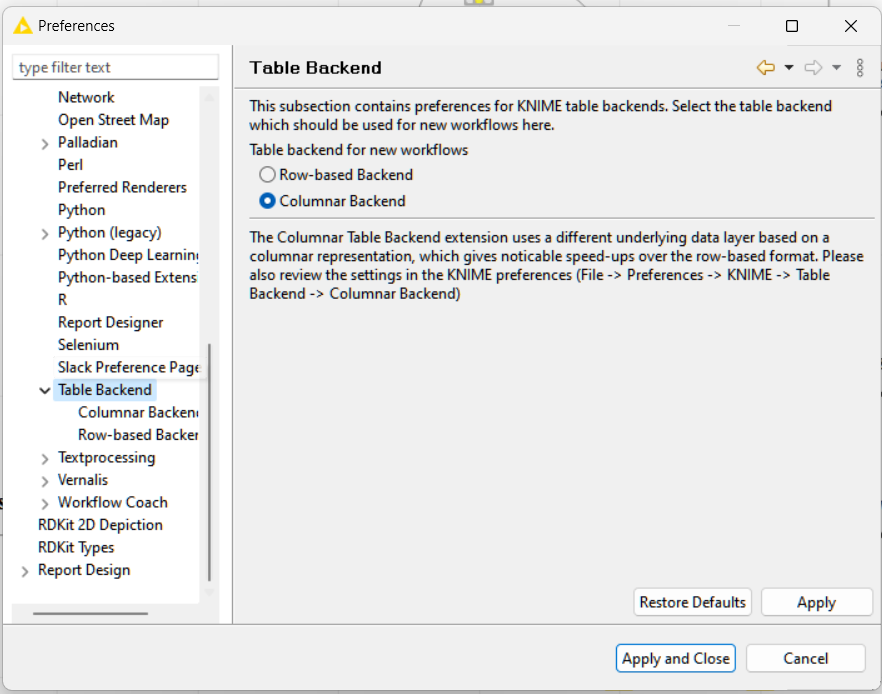
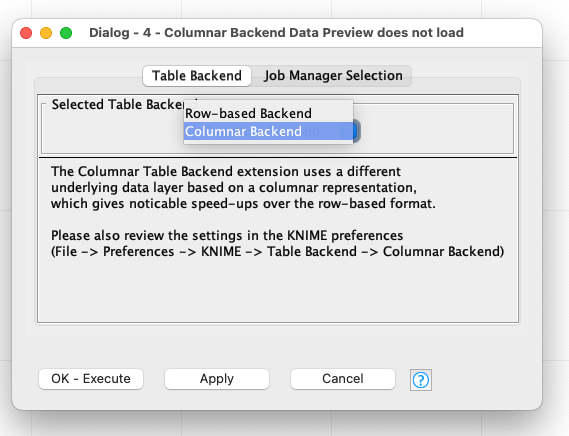
Oh! Now I see the confusion. There are two settings to switch the table backend: one per-workflow, and one in KNIME’s preferences which will apply to all workflows that will be created after changing the setting.
I was thinking of this dialog in the screenshot which configures the current workflow only. To get there you (currently in classic UI only) right click on the current workflow in the explorer → Configure → select the table backend. This should reset your workflow.
Changing the global preference setting will not impact any workflows that have been created before.
Thanks for pointing that misconfiguration out but it is rather confusing that the app settings are “locally” overwritten and there seems to be no indication / note in the preferences nor notification upon opening a workflow with contradicting, app vs. workflow, settings. I think it would be good idea to:
In order to profide greatest flexibility but make users aware of possible disjoints to
Add a hint in the application settings which instructs users to also change the workflow settings
Add a notification upon opening a workflow with settings that disjoint those of the app
Add an option in the app settings to force overwrite / apply the columnar or classic row based backend
Upon reprocessing the data it seems the Hash Calculator is facing a serious performance regression. It processed for +15 minutes and barely reached 80 %.
Anyways, focussing on the main challenge. Even after switching to the columnar backend, reprocessing and saving. It takes several minutes to display a table which contains the data of just ten images.
I alos removed the column with the string representation of the binary object and the preview still froze. Guess, albeit the binary object seems capped as well, it still impairs the UI responsiveness.
I have seen this issue before with lots of long strings. unlike some of the chemistry column types which can contain long strings and which use a factory to determined whether to use a Blob-based version of the cell or an in-memory version depending on the length of the string, String columns are always ‘in memory’ - maybe a factory class (I think there is one!) which could mimic the chemistry types (e.g. SdfValue implementations) is called for?
Adding to this I traced back another possible issue. Though, I am not quite certain to which degree it is related. What I did was improving my RegEx as it was not quite accurate.
There were still some remaining rows which could not be converted to XML. Attempting to look at just one cell was always impossible as the preview never rendered.
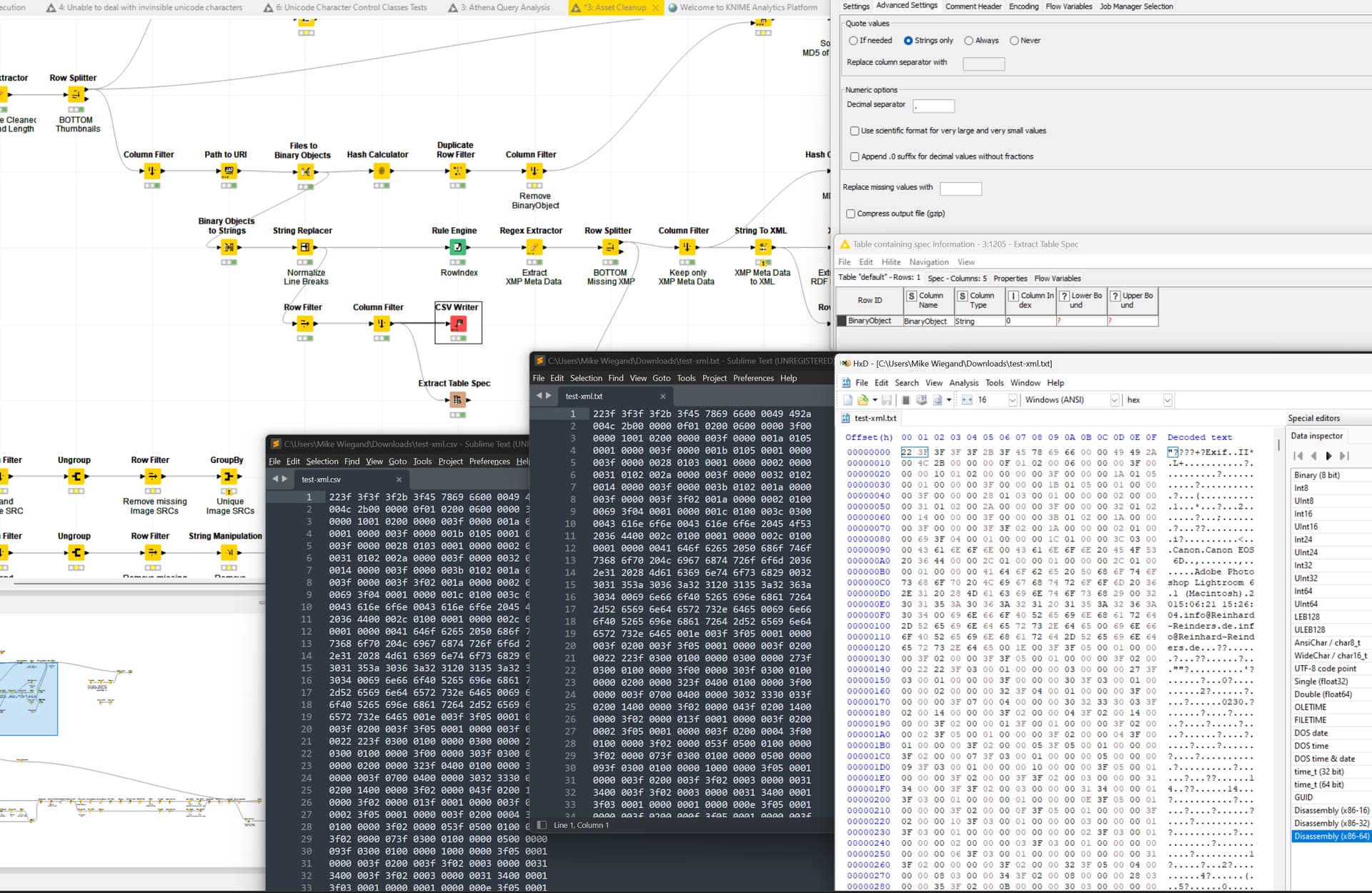
It then tried to save the extracted string as a file to actually be able to inspect the data. However, the presumably string seems to still be binary. The following screenshot can be understood as follows:
Files to Binary Object Node reads images
Binary Object is converted to a string with the purpose of extracting the XMP Meta Data
Line Breaks are removed which simplifies the RegEx
Filtering for just one file and one column
Saving as CSV or TXT (not gz compressed!)
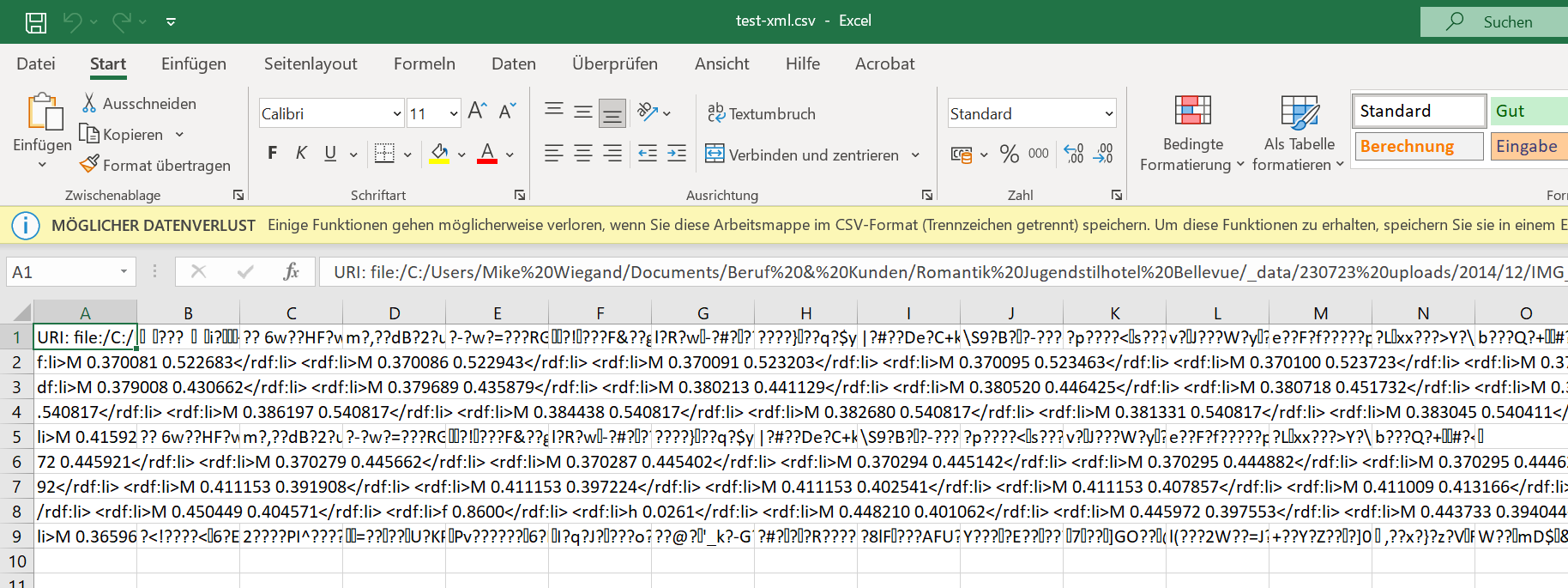
In Sublime both the CSV and TXT are not of the type text. However, the column spec of the Extract Table Spec node tells otherwise. Reading one of the saved files via a hex editor, seems to prove that the data, whilst it should be text, is not.
I can reliably reproduce the issue and have created a workflow. In order to execute it, you must download the image first as it’s of >6 MB in size. Some minor adjustments to the paths are required as well. I will upload the workflow soon (Knime is currently unresponsive).
The point is that this seems to cause Knime data preview, node configurations and sometimes Knime itself to snap, requiring a forced kill via task manager.
Edit: had to rebuild the workflow as Knime, well, crashed because of this issue. Here is the workflow:


{kind=link}