How do I get a list columns from a database table (eg psql) whose values don’t change at all?
Thanks!
How do I get a list columns from a database table (eg psql) whose values don’t change at all?
Thanks!
You really need to provide much details on your data structure and criteria when value on DB considered as not changed or changed.
Consider just a static snapshot. There could be columns that have a single value all through out.
Would it be possible to get a list of such columns? This may not be possible through a SQL query. KNIME would be a good vehicle.
I do not see SQL restrictions here. Just use
select count(distinct column_1), …, count(distinct column_N)
The columns with counts equal 1 are have only one value.
Sounds good, but I have 300+ columns. So, I am looking for a KNIME workflow automation
Hi @tims , Assuming that you are comparing the data in Knime tables, you can use the Table Difference Finder node.
It will tell you what the differences are between the 2 tables.
Note: Just make sure that the 2 tables are sorted the same way and their respective structures are the same.
@tims the DB group by node can do groups of variables also by type.maybe unique count.
If all values are numeric you can use logic below
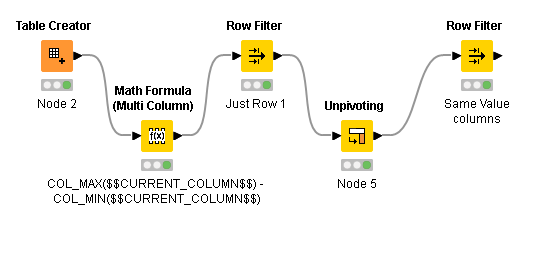
Columns with Same Values.knwf (23.3 KB)
Also, it seem Col_Min/Max function could be useful for String Manipulation Multi Columns node.
Good one for comparing two tables. I have only one table here. Were you hinting at comparing a table to itself by any chance for further manipulation?
Good one for numeric data. I added column3 and the unpivoting became a little wonky.
I wish there was a “distinct count” function in f(x) block. How would one go about adding custom functions?
I tried replacing “f(x)” with “Category to Number” ; but this block does not show any columns from Table Creator. Am I missing some link in between?
KNIME data table has lower bound, upper bound and some unique values.
It would be nice to have a “Unique Count” column for each column.
python pandas script connected to DB Reader seems to work… waiting for results
output_table_1 = input_table_1.copy().nunique()
Sorry @tims , I misunderstood what you were asking. I thought you were comparing a table to a snapshot to see if there were any changes.
For uniqueness check, the SELECT COUNT(DISTINCT ) and the GroupBy suggested by @izaychik63 and @mlauber71 are excellent suggestions.
If you have 300 columns, you could may be construct the SQL statement via Knime, and then execute the statement via the DB Query. I’m not sure how much impact the statement would have on the DB server - running 300 COUNT(DISTINCT) at once.
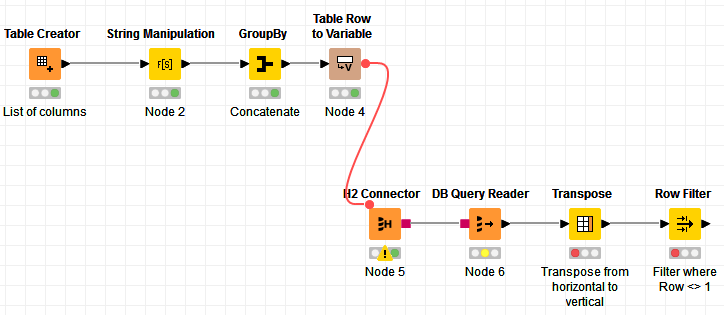
Hi @tims , I put something quickly together to illustrate what I meant, and it looks like this:
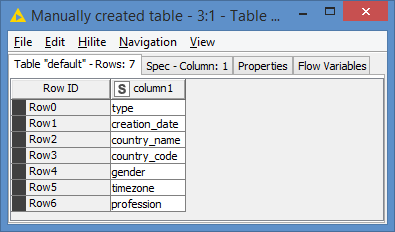
You need to retrieve the list of columns you want to evaluate (the 300 columns). For the sake of the demo, let’s assume we have these columns:
First step, I do a String Manipulation to add the syntax COUNT(DISTINCT xxx):
I use the GroupBy node to concatenate all the rows in the query columns:
I then convert this to a variable so I can use it in my query:
In the DB Query, you can just reference to the query variable like this:
SELECT $${Squery}$$
FROM table1
(I don’t have the proper table for this, so I can’t run the demo fully)
The results will come out as 1 row, but with multiple columns (1 column for each COUNT(DISTINCT...)). To make it easy to validate the result, I transpose the result so we can then filter on rows whose value is not equal to 1.
Here’s the workflow: Check DB columns with unique values.knwf (22.0 KB)
Some notes:
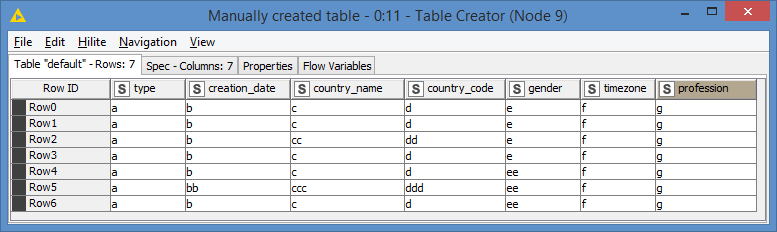
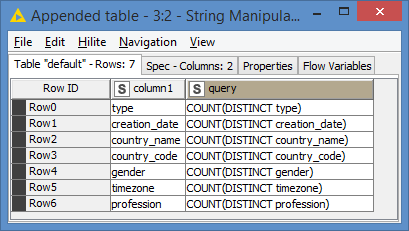
join("COUNT(DISTINCT ", $column1$, ") ", $column1$)SELECT COUNT(DISTINCT type) type, COUNT(DISTINCT creation_date) creation_date, etc…Hi @tims , I ended up generating some dummy data cause I wanted to see the demo run.
We can see that the columns creation_date, country_name, country_code and gender do not have unique values, so we expect to see them in the results.
A little note: Since I am using H2 as DB, it looks like by default it assumes column names are in uppercase, which is not my case, so when I ran the SELECT COUNT(DISTINCT xxx), it was converting the column names in the query to uppercase. In order for this to work in my case, I have to quote the table names so that they are parsed as is. So I modified my String Manipulation to add the quotes. You may not have to do this, depending on which DB you are using. I also added the aliases so that it’s nice looking in the final results. I had to quote the aliases too:
join("COUNT(DISTINCT \"", $column1$, "\") \"", $column1$, "\"")
After running the query and transposing, I get this:
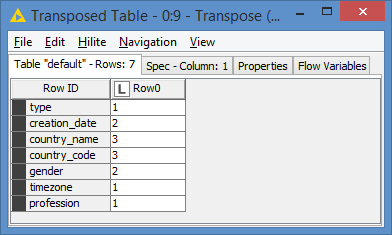
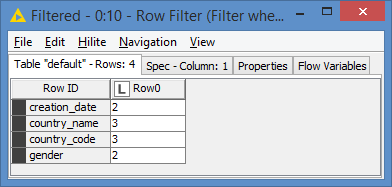
The columns appear in the Row ID because of the use of the aliases. We can see the 4 columns mentioned above do not have unique values from the results. Applying a Row Filter where value is not 1, we get:
Updated workflow with some dummy data looks like this:
Here’s the updated workflow: Check DB columns with unique values.knwf (29.5 KB)
@bruno29a … thank you for the detailed workflow. I’m still hanging onto nunique as it is an effortless single liner. However, it is quite slow for the size of the data. I will have to check yours too and adopt it if its faster.
Meanwhile, I am trying to remove the identified columns from dataset that have only a single/zero unique value.
-Get the list of such columns and convert “Row ID” into a flow variable.
-Use the flow variable in “Column Filter”'s excluded_names.
-However, I still see the columns to be excluded in the Column Filter output.
What’s wrong with my workflow?
Hi @tims , just so you understand the difference here. The solution I presented would run on the DB side, possibly using applicable indexes. With the Python script that you are using, you are doing the operation on Knime side, which will not use any index, and performance will depend on your Knime station. In addition, it will be very resource intensive. You need to first get all the data (bandwidth, memory and space), and then process the data in Python (CPU, memory and space).
There’s no real which one is better than the other. Both have pros and cons over the other. It depends on your situation. But just be aware of the difference.
Regarding your issue, it’s hard to say without seeing what you are doing in these nodes and what their respective results are.
EDIT: Regardless what you are doing for the Column Filter, a simpler approach would be to transpose the results of you counts and then apply Row Filter excluding rows with values of 0 and 1, and then re-transpose.
For example, let’s say your count unique comes out like this:
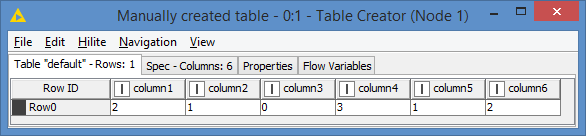
If I understood correctly, you want to remove the columns that have 1 or 0 unique count, in my example that would be column2, 3 and 5, meaning the result should keep column1, 4 and 6.
Here’s the result:
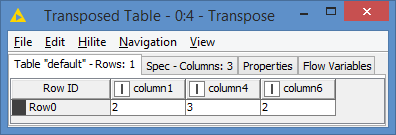
I got a similar count from “Row ID”. I would like to exclude these columns from the source data (DB Reader). So, there is a flow from DB Reader as well as “Table Row to Variable” created into “Column Filter”. The task of excluding these using Column Filter is not working out.
Hi @tims , let’s say you are able to filter the columns as needed, what do you want to see in the columns, the count or the data?
You way will give you the data, while the solution I proposed will give you the unique counts. I had assumed that you wanted the counts, not the data, but looking at your workflow (yes it’s not currently working, but I get what you are trying to do), the filtered columns would contain the data in your case.
Whether trying to fix your way or go with my way will depend on what you want to see in the columns.