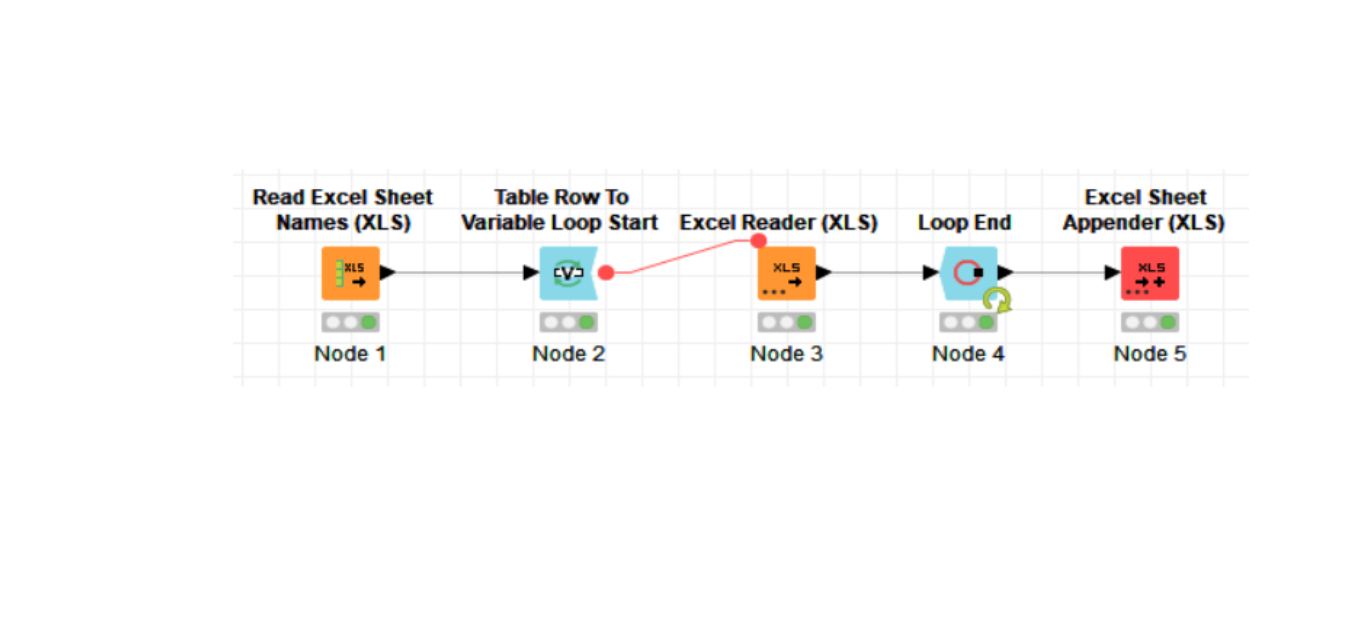
When I changed the workflow using the excel reader by Unchecking Read the entire the data sheet
then adding Reading columns A to J and Rows 1 through 5 to create a sample workflow.
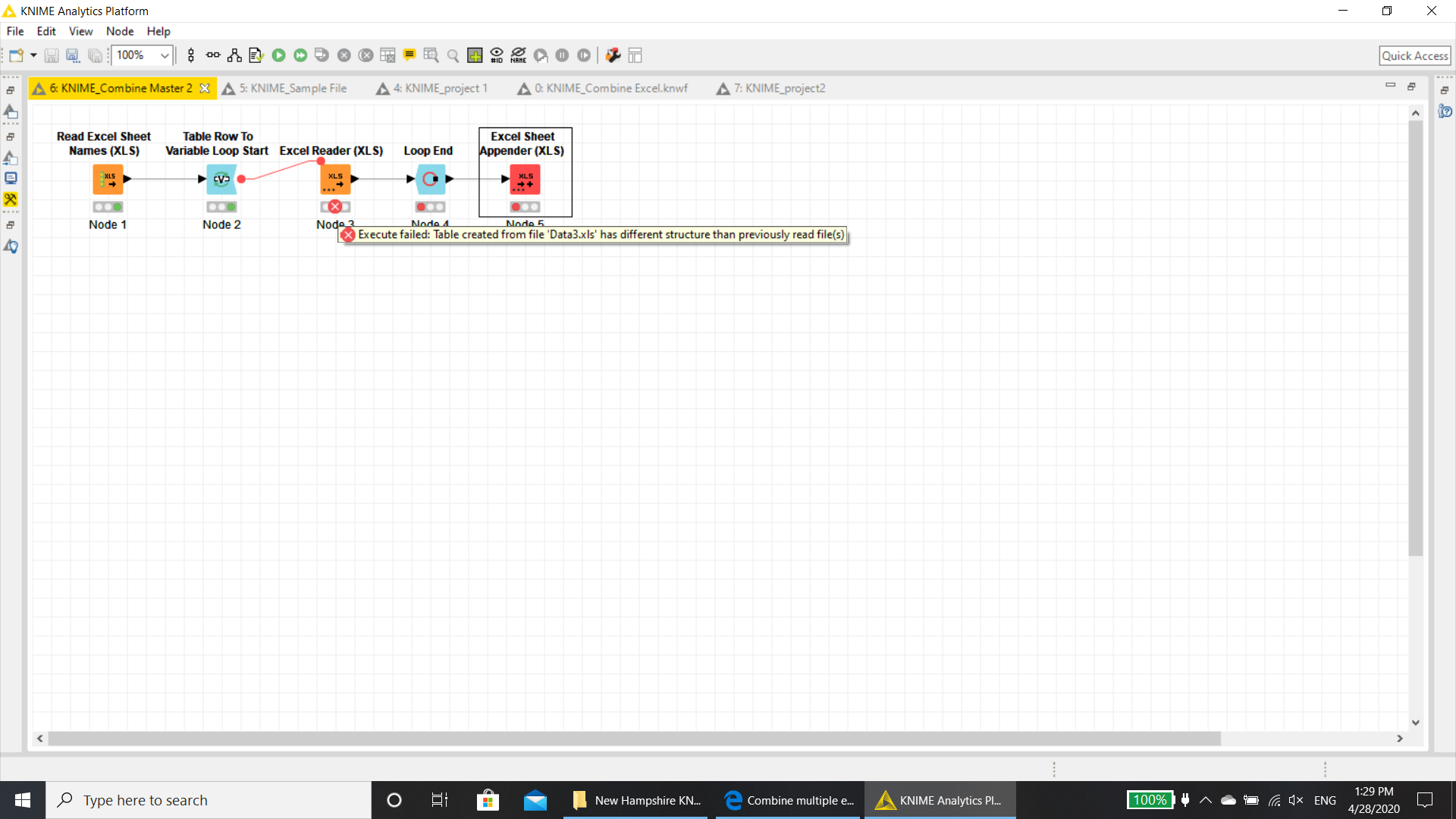
When I execute I get an error
Execute Table: Table created from the GoffstownOneStop.xls has different structure than the previous read files.
All 5 files have the exact same Column Headings so I don’t know what the issue is plus it worked when I was combing the whole xls file into one large xls file.
Hi,
The Excel Reader node tries to determine the data type of each column in the excel file.
It presumably does this by scanning a number of rows. If it finds integers in a given column, it will create a corresponding Integer column. If it finds floating point values it’ll create a Double column.
What Can Go Wrong:
Things can go wrong, especially if the number of rows scanned is small (as in your case).
For example, if one file contains floating point numbers (e.g. 5.2, 6.8, etc.) in a given column and in another file the values for the same column happen to be whole numbers (0, 1, etc.) it’ll create a Double column in the first instance and an Integer column in the second, and therefore the table structures will be different, and the Loop End node will complain.
Also if the Excel Reader can’t determine the type, it might create a String column. This might happen if there is a letter or spacing before or after a number in a given cell, for example. How to troubleshoot:
Step through the loop execution (right-click the Loop End node and select “Step Loop Execution”) and note the types of the columns in each iteration. When you spot a column that changes type between iterations then try to determine why the type was different by looking at the values in the column. How to fix:
You can try to convert the values of the columns automatically using the Table Validator node placed after the Excel Reader.
Hi,
I think it’s grayed out because the Excel Reader node just prior to the Loop End has an error, thus preventing the execution of the loop. If you hover the mouse over the red X under the Excel Reader node, it should give you a clue as to what the error is. Once you fix the error, you should be able to step loop again.
-Don
Hi Don,
I thought the Step Loop execution was so I can see where the error is. when it occurs. So I reset all the nodes then I thought I could select/configure the step loop execution then execute all the nodes and it would show me where exactly it is failing.
But now you are telling me I need to fix the error? I am confused.
Thanks for all your help,
Scott
Sorry… when you originally posted that you got an error it sounded to me as if the error was coming from the Loop End node:
In any case, assuming the first iteration of the loop doesn’t fail, you can step through the loop until it does fail (first reset the loop start node). Inspect the failing Excel file to try to determine why the Excel reader thinks the structure is different. Check for columns you thought were empty but perhaps have something entered in them, check data types of values in the cells, check for same number of columns, etc.
Another way to troubleshoot: you could try using separate Excel Reader nodes outside of the loop to read each file (use the same configuration settings) just to see how the Excel Reader node guesses the structure of each file.
What does the error say when you hover the mouse above the X under the Excel Reader node? Is it the same error you cited previously?
No problem,
Do you have any other suggestion.
If I do the whole file it works. If I select rows and columns it fails and gives me an error for one of the files.
Thanks I will make sure the preview is disabled. The thing that bother me is the structure of the files are the same with all the same column headings. Appreciate the feedback.
Turning off the preview didn’t help. Is there anything else I can do so I don’t get file structure errors. The files/excel files are exactly the same so I don’t know why these structure file errors. Is there any other nodes I should run before combining the files or any other information on how to setup R or python.
judging by your screenshots you don’t have 5 Excel files but one Excel files with multiple sheets which you combine. Am I right? Anyways I couldn’t reproduce your error. Do you mind sharing workflow example?
I have more than 5 spreadsheets but I will start with 5 for now. I have 5 excel spreadsheets with one sheet called sites in each excel spreadsheets. I will share the workflow and 5 of my excel spreedsheets files.Data1.xls (50.5 KB) Data2.xls (51 KB) Data3.xls (61 KB) Data4.xls (35.5 KB) Data5.xls (33 KB) KNIME_Combine Master 2.knwf (17.9 KB)
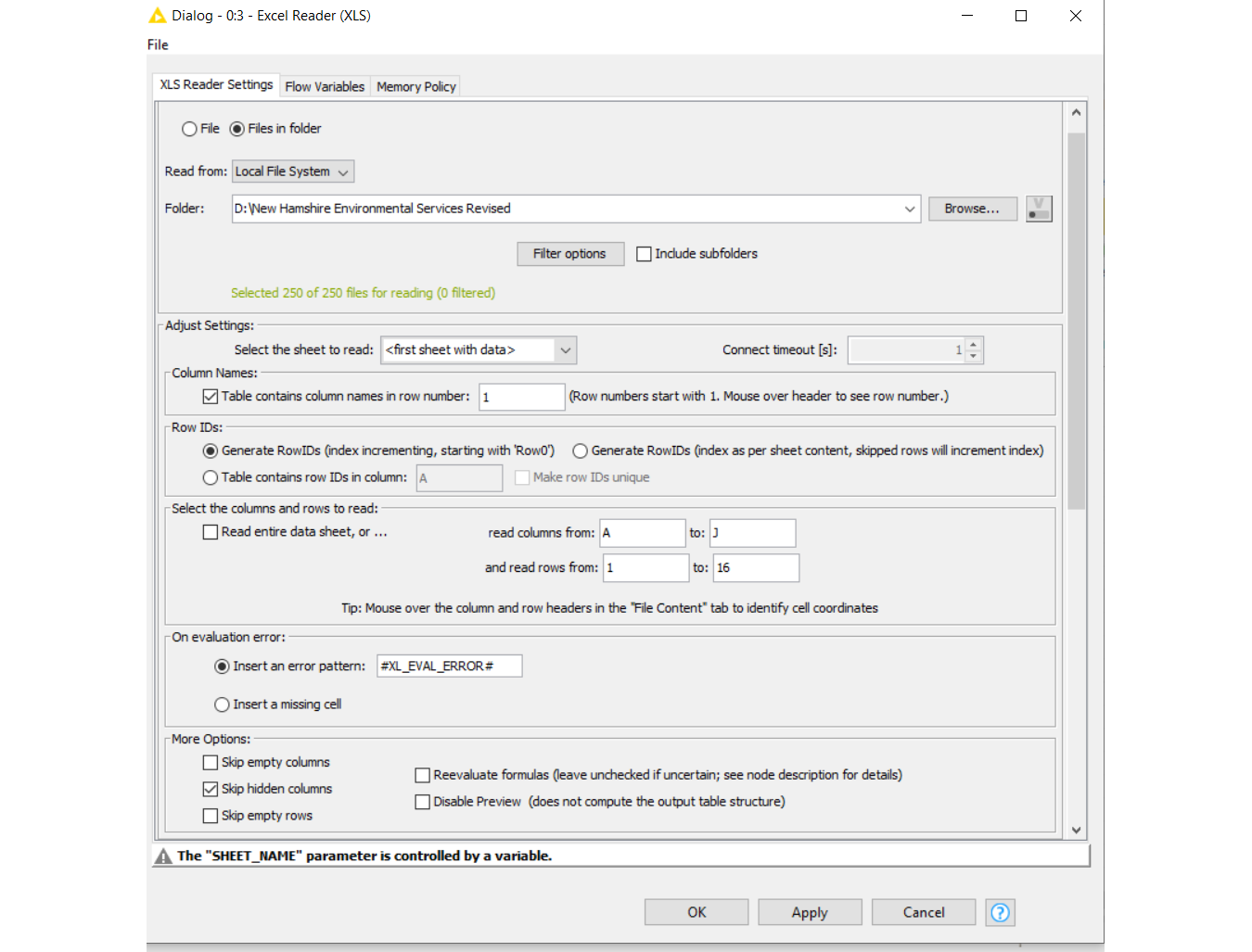
you have columns in one of your excel file which doesn’t have data within first 11 rows. Default Excel Reader node configuration is to skip such columns (perceived as empty although they have header name) and from there error comes. To solve it simply uncheck option Skip empty columns.