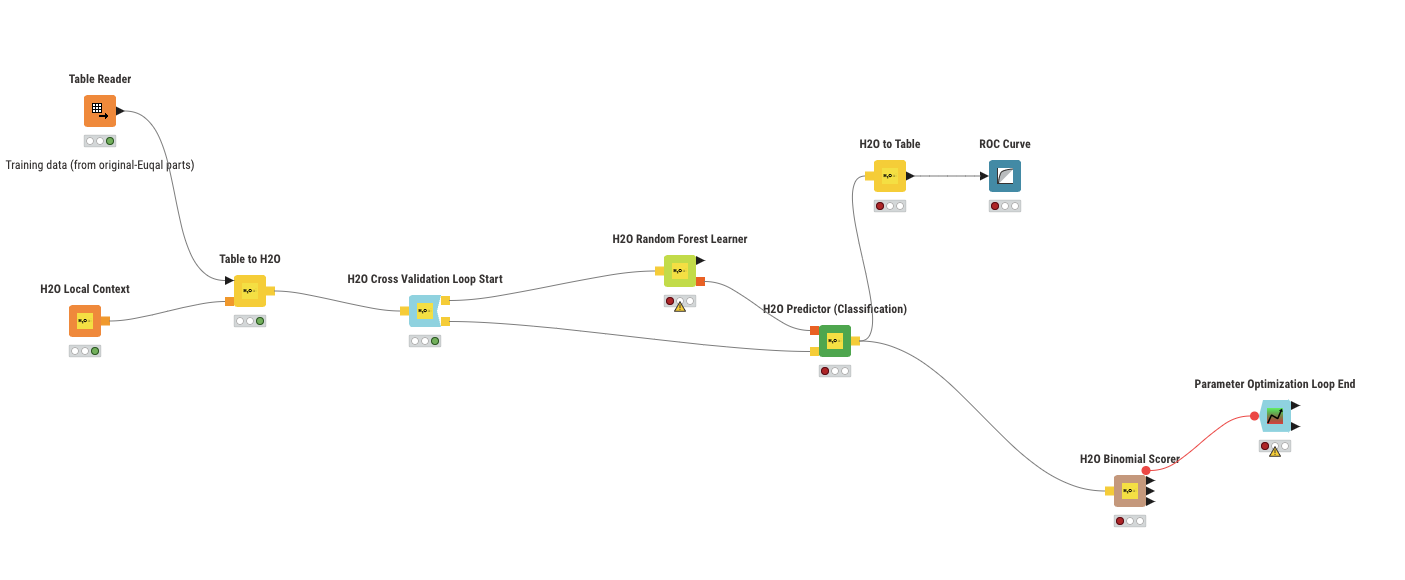
I am undertating a study which seeks to predict whether a granite instrusion is prospective for ore deposits on the basis of geochemical data. For this study, I am comparing random forest and Gradient boosting. What I aim to do is to combine cross-validation and parameter optimization together in the context of the H2O random forest and gradient boost nodes. Q: Is there a way to succesfully combine the H2O cross-validation loop with the parameter optimization loop without causing loop issues? The study, that I am attempting to replicate says: “Model tuning was accomplished using a grid search strategy with the fivefold cross-validation method.” For reference this is the current KNIME set-up.
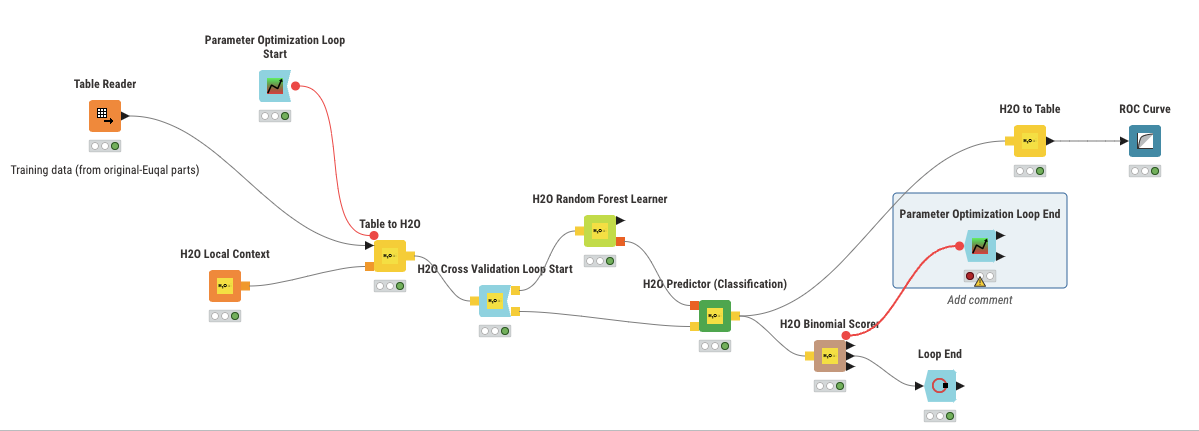
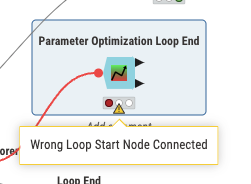
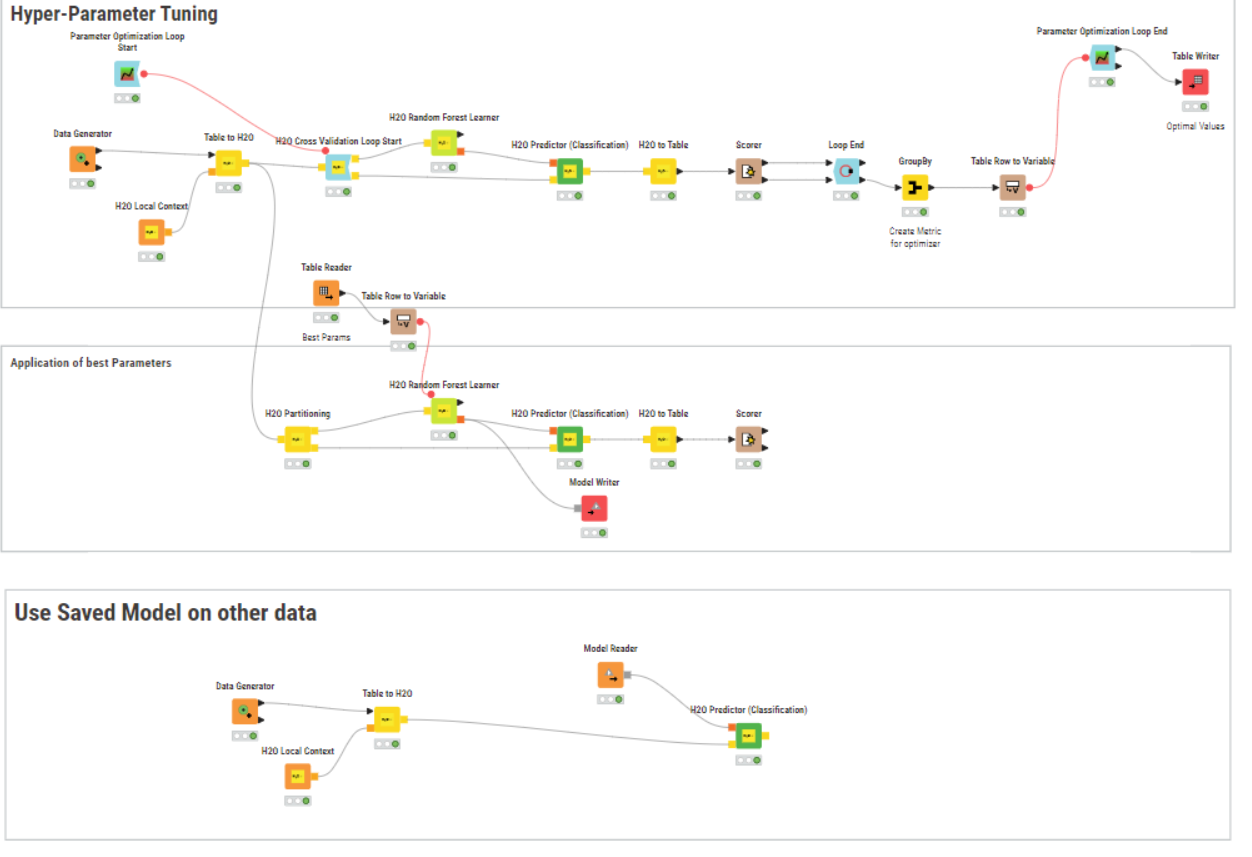
Here is an updated workflow configuration. . . along with an error message. . . essentially I am trying to get Parameter optimization loop and the H2O cross validation nodes to work by configuring the end nodes.
your approach is almost correct. First you have to close the inner loop for the Cross Validation Loop start. After this you can embedd this into the optimization loop.
I used the KNIME scorer. Of course the H2O one is working as well
Many thanks for the quick reply, I do appreciate it. I’ve amended my workflow following your blueprint and now the Lerner and classifier are both “doing their thing” flawlessly without any error message.
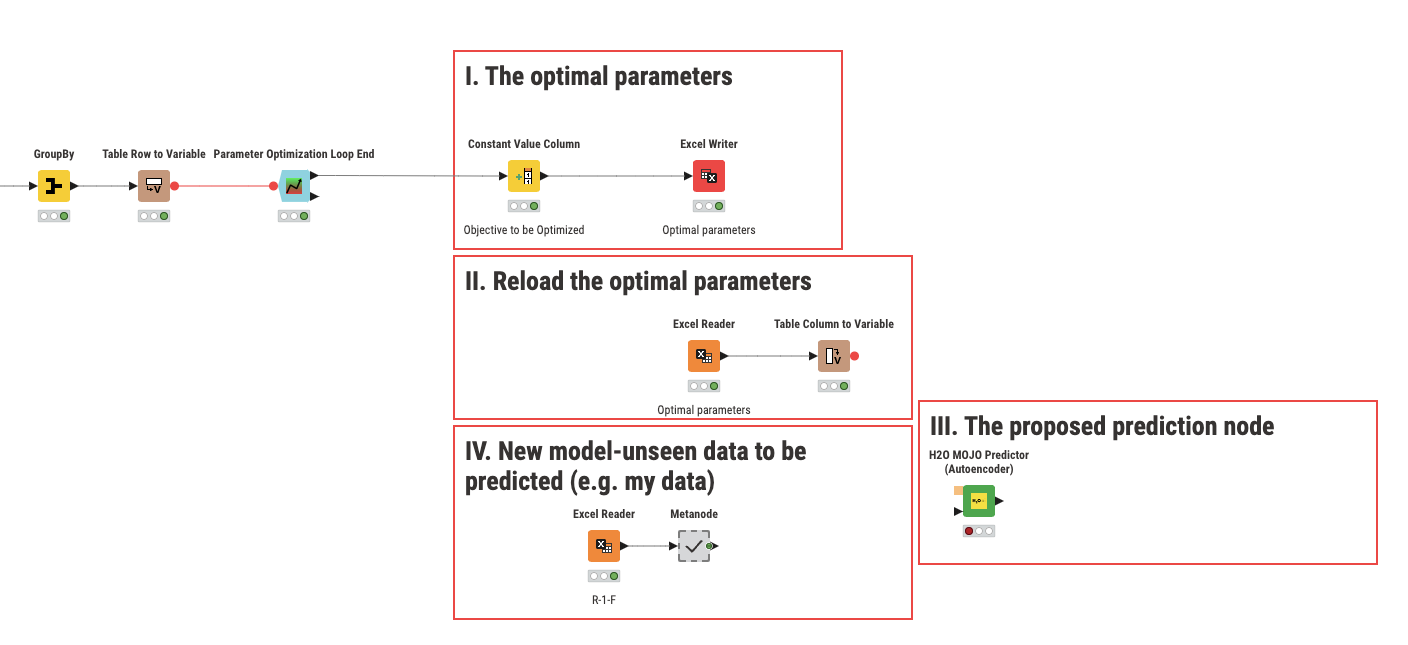
Thanks to your help in part 1 I now have a prefered model for my H2O random forest classification project. Can you please recommend a way or configuration that will permit me to save the preferred model based on my parameter optimization (rather than the last one which ran) based on your initial configuration you showed me previously?
the “Parameter Optimization Loop End” Description
provides the best parameters for the model. I would store this table as a file (e.g. excel, csv or knime table).
To apply the parameters to a new model just load the file, convert it to variables using “table column to variable” node description and pass the variables to the predictor
Thank you for your assistance! So here is the configuration based on my understanding of your guidance. I think I have the nodes okay. The main issue is how to connect these nodes together in a way that
Captures the approved model (step I)
Loads and then passes the approved model to the predictor (step II & III). This is a H2O Random Forest Model.
Passes my data tables (there are 15 separate tables in step IV with one shown for example) to the predictor (step III)
I guess I am having difficulty visualizing the correct configuration of these nodes. If you could please show me a mock-up of what a correct configuration might look like that would be so appreciated (im very much a visual learner) and the workflow you supplied earlier helped a great deal.
Many thanks for your help thus far. This is my first real data-science/machine learning project ever. So I am building the plane as I am flying it.
Many thanks for this clarification! I do appreciate this. Now I know what to do. Im forever grateful for your assistance as someone who is just starting out. I might post my results once I have data prepared at some point in the future.