Hi ,
I want to combine multiple rows into 1 based on some defined combinations.I have tried to explian the same with below sample data
cart1=test1,test2,test3,test4,test5,test6,test7,test8
cart2=test3,test4,test5,test6,test7,test8
cart3=test1,test5
cart4=test3
group by productid
test1,test2,test3,test4,test5,test6,test7,test8 are different rows for any productid and now I want to merge these rows into one row as per combinations defined.
eg 1)if for any product id only test1 and test5 are performed then these 2 rows should be merged into one row and column value becomes cart3(instead of test 1 and test5)
eg 2) if for any product id only test1,test2,test3,test4,test5,test6,test7,test8 are performed then these 8 rows should be merged into one row and column value becomes cart1
I thought of using groupby node but not sure how can I put different combinations since the values are repeating- like test1 is available in two combinations cart1 and cart3.
If anyone can help with the worklow, that would be a great help.
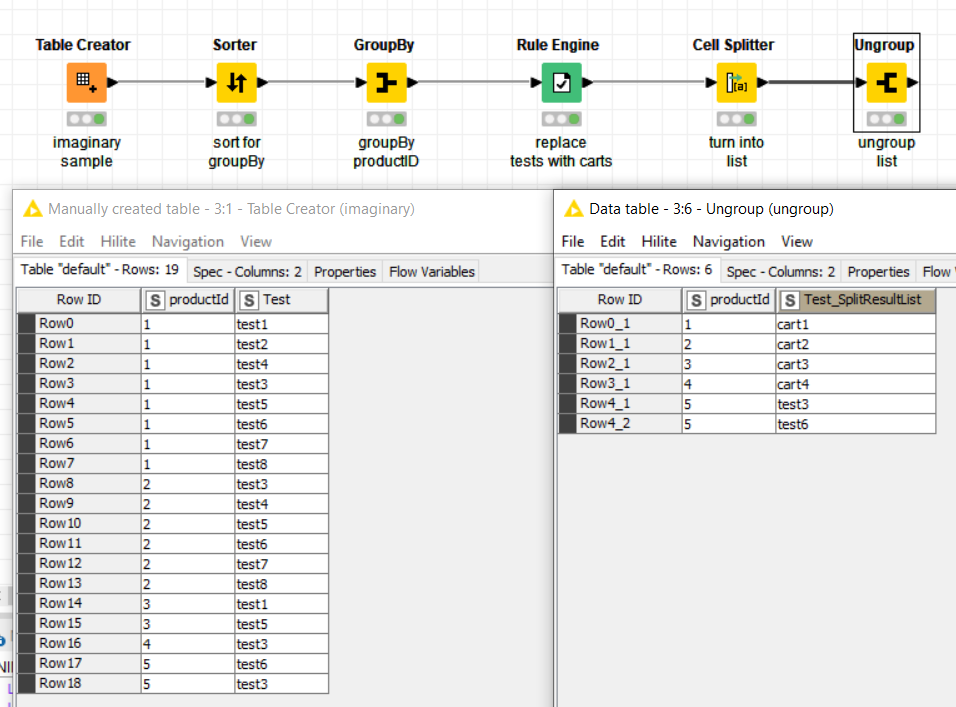

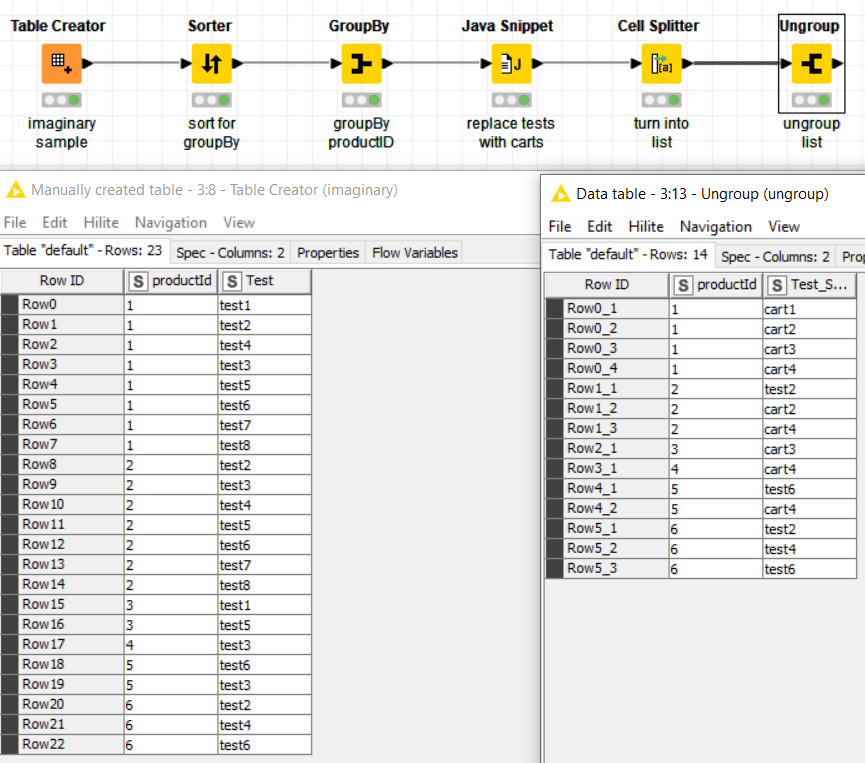
 The groups are again hardcoded. This is not optimal, they could instead be passed via a Flow Variable. Also I renamed the groups apple and berry to avoid confusion with the items of the same name.
The groups are again hardcoded. This is not optimal, they could instead be passed via a Flow Variable. Also I renamed the groups apple and berry to avoid confusion with the items of the same name.

