I have come into a difficult situation that seems to require combining a chunk loop that joins with a recursive loop.
Here is the challenge. I need to match “restricted” donations for a non-profit up with expenses that match the donors restricted purposes. Once a donation amount is applied against an expense, it must no longer be available to apply against another donation.
My plan was to feed these donations from table 1 a single row at a time (hence the chunk loop), then use a complex H2 join to match up with corresponding expenses, then use a multi-row to calculate a reduction of those expenses 1 by 1 down to zero, then feed the expenses with any changes recursively back through for the next donation row. However, I am running into loop errors every way I try to organize the recursive and chunk loop combo…
I will try to share a workflow if I can come up with simple way to do so using dummy data.
I plan to try a 2 port recursion loop in the morning where I use an iterative filter approach to feed the donations though a reclusive loop port instead of using a second chunk loop…
Are donations and expenses matched by exact value or are you trying to find a “best fit” where a donation can cover more than one expense?
By the way how big is the data set? If not massive, an alternative to a recursive loop would be to use a file that you populate prior to the loop and then on each iteration you read in the file and then write the updates back to it (eg mark processed expenses as paid).
eg using Table Reader and Table Writer.
That way the file acts like the recursive loop table as it changes for each iteration. It’s an approach that can work if the performance hit is acceptable.
And yes the two port recursive loop could work maybe… Depending on the specific rules for matching donations with expenses. If on each pass you match as many donations with (previously unmatched) expenses that you can and then “keep” only the first match found for each, passing the updates to the next iteration I can in theory at least see that might work. You will need a termination condition for the recursive loop, such as a variable that gets set when no further matches were found/available. Might work…Possibly…
The dataset is not particularly “large”, but we are still talking about hundreds of donations that need to be reviewed and 50k - 100k rows of expenses per year.
Unfortunately donation and expense amounts will almost never match an individual expense amount 1 for 1. In fact a single large donation may cover hundreds of expenses, or it may take dozens of small donations to reduce a large expense to zero.
When you combine those together it makes the manual file approach pretty brutal, especially because it will likely require rounds of adjustments to ensure that certain expenses are earmarked during the process because they alone fulfill a more specific donor restriction.
I plan to take the manual user interaction based excel approach to handle the few hyper specific custom donor restrictions as well.
If I can get the recursive loop approach to work then I plan to just use the count of the restricted donations to control the maximum iterations by flow variable. There will be no need to do a second pass. That should avoid any endless looping issues.
Hi @iCFO , on the face of it this sounds very similar to the challenge of “allocating transactions to budgets”, from this forum post:
If we treat your donors as “budgets”, and your expenses as “transactions”, where budgets can cover many transactions, and transactions can be covered by many budgets, then it is very similar. In the link supplied, different budgets and transactions were assigned “Work Orders” which grouped budgets and transactions, but I think we can treat everything as having the same “Work Order” which is what I have done to make it work with the sample “donor” data. Previously it joined on Work Order, so I replaced that with a Cross Join and then added a constant Work Order to allow the rest of the workflow to continue working.
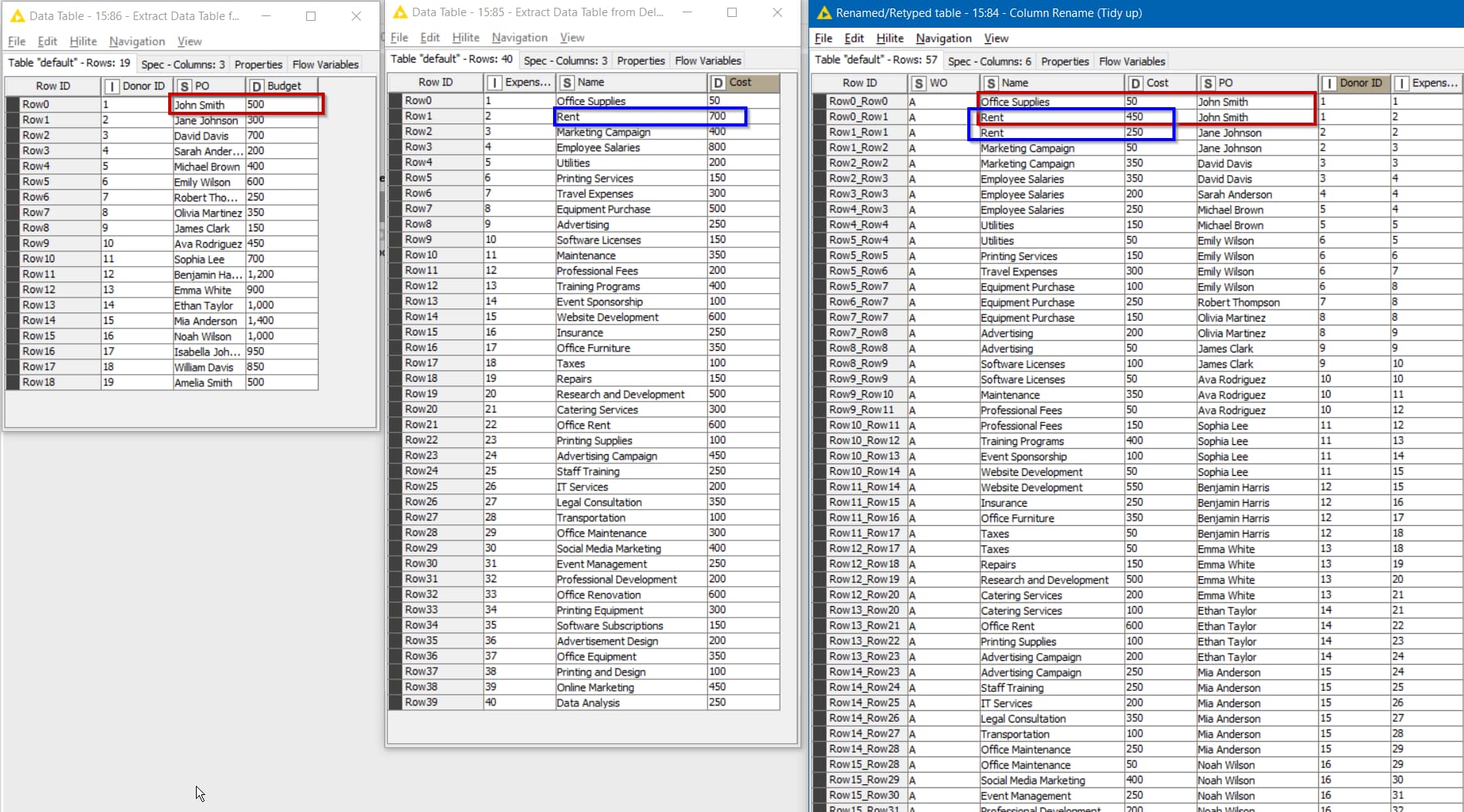
Attached is an adaptation of the above workflow with some sample data created by ChatGPT. It contains no loops because a java snippet does all the cumulative calculations in one pass.
You can see in this screenshot, that the Donations (PO/Budgets) do not match the Expenses (Transaction Name/Cost) but instead are allocated out in turn, so John Smith in red donates 500 which covers Office Supplies and some of the Rent, The remainder of the Rent is covered by the first 250 of Jane Johnson’s donation and then her next 50 goes to Marketing Campaign, and so on.
The workflow as supplied still contains terminology for Purchase Orders and Works Orders, so I just coerced it slightly from the original, but I wonder if this might be adaptable to your needs.
Interesting… I work with budget to actual reporting daily and this is a good bit less straightforward. A few concept questions before I dive down that path.
Budgets are typically “buckets” that only match 1 join criteria and can have overages, whereas 20 donations may overlap on certain donations but not match on all of them. There would need to be a way to reduce expense balances for the next donation so that they can be split between buckets. There would also need to be a way to cap each bucket so that there were no overages and the remainder of expenses were released for the next donation. Would this kind of multi-row balance reduction be possible?
Budgets attempt to mirror actual financials in time frame, accounts, types, etc. In this instance expenses can only be applied to a donation if they occur after the donation is recorded. This makes it a bit of a time series challenge, which led me to the iterative approach. Do you think that the JavaScript approach could handle this kind of date join variability?
I am fairly sure that I could get around all of the other complex join criteria variability with pre-processing, which I will now be doing either way to clean it up.
I think in principle the java approach could be adapted, and certainly from previous attempts at this type of money-allocation exercise, the java is vastly more performant and ultimately simpler (if you know java!) than building it as KNIME loops. Although it can end up as a combination of loops and java!
Obviously I don’t at this stage know the full rules about how donations should be matched to expenses, so any specific rules would need to be listed, so this is just throwing out a possible avenue to explore.
If you have some examples, or could maybe take the sample data I included in the workflow, and add in some date or other info that would make it closer to the type of data you have, and need to be taken into account, I could give a better idea of if it could be a good fit. Time/sequence/series constraints would probably amount to something similar to the original “work order” join that I removed from the original, although I realise would potentially be a little more “fuzzy”.
The approach of using a dual port recursive loop works perfectly and it only required a quick adjustment. In case someone is looking at this in the future, the trick was to use a row splitter on the table input instead of a chunk loop, then concatenate the processed rows back onto the bottom of the table to feed through the recursive loop. I also limited the recursive loop by the number of rows that I needed to loop through.
I have no doubt that your java snippet approach would be more efficient, but I think that I will stick with this approach for now as it comes with a really easy to customize multi output capability. I am simultaneously building a restricted donation impact table to build a General Journal entry, an expense impact table to use for processing in the next period, and a formatted report structure for the auditors / donors.
Also FYI @takbb - I am also passing through your new “Join Custom Condition - Indexed” component for all of the joins, so I get to simultaneously get to test it out by hitting it pretty hard. No issues so far, and it ran the first 10 iterations of a complex join in a few seconds!
Is it possible you could provide / show an example of your flow with dummy data? This is not because I have a better idea - I don’t. I would like to ‘play’ with it and learn about the techniques you are using.
Dummy data is tough for something like this. I will have to look around for a public dataset of detailed accounting records that has some contextual honesty. It would be brutal to try and comprehend this with gibberish in / gibberish out. I would also have to simplify this thing quite a bit. Right now it has a ton of pre-processing that is organization and situationally specific, and a 6 way case switch to handle all of the complex H2 join scenarios within a recursive loop…
I will see if I can get a basic example ready to share sometime next week.