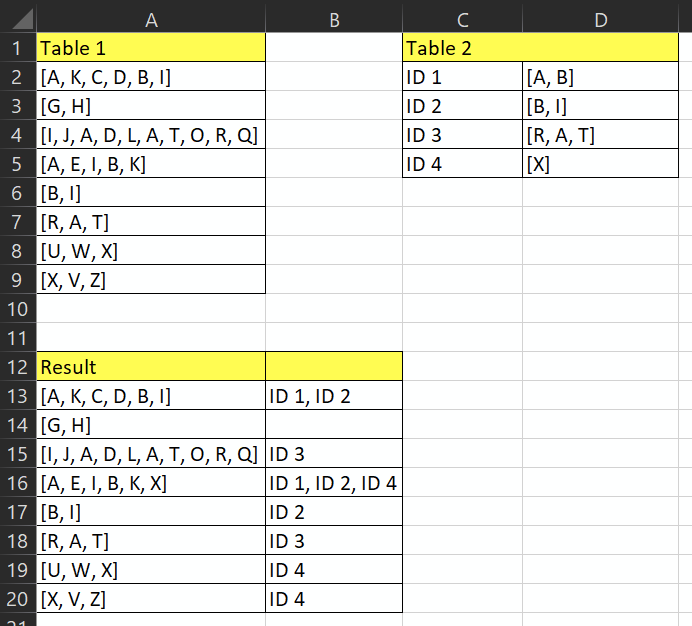
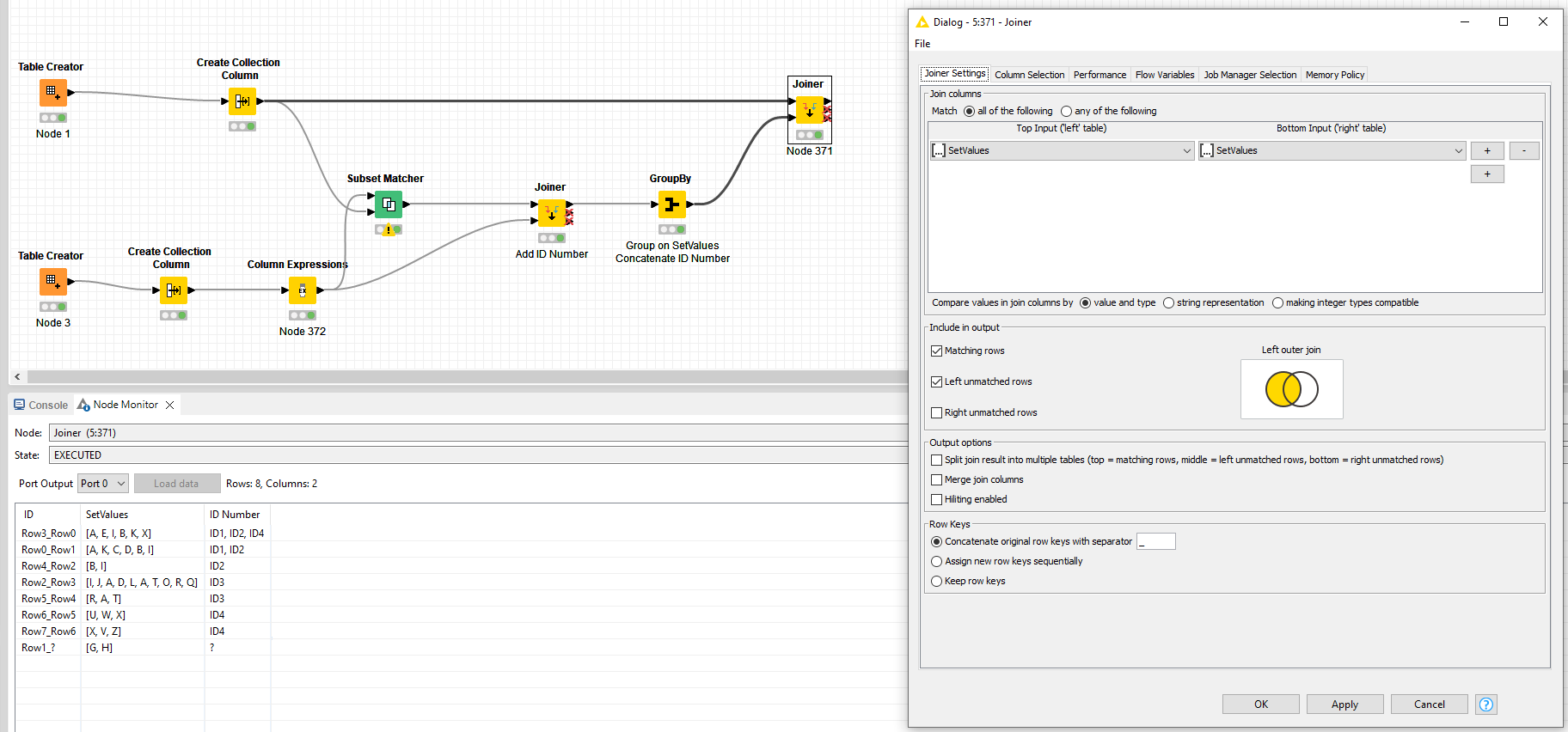
Both lists contain multiple strings (e.g. A, B and C).
I want to take each string in Table 2 and go to through Table 1. If a matching string is found (e.g. A) then I want to go to the next string in that table 2 (-> B) and go through that same row where the first string was found. If all of the strings were found, then I want to post the ID as a result next to Table 1 (see Result table).
I have been working for two days on this, but was not able to complete it, so I would really appreciate some help. Thanks in advance!
Welcome to the KNIME Community! Can you please elaborate on your logic?
I understand it as: if A if found, only then check for B. If B is found, assign the corresponding ID1. As a dependent sequence.
If that’s the case, can you then please verify your expected result because it seems slightly off.
Because Row 15 is linked to ID 3 but the chars do not appear in the required sequence: A, T, R vs R, A, T. I believe it should be blank then. Row 16 should not have ID 2 due to I, B vs B, I.
If you just want the check if any of the chars from Table 2 appear in Table, then Row13 should also have ID3 assigned due to the ‘A’ while Row 15 should have ID1 and 2 due to the ‘A’ and ‘B’.
Once you have clarified this I’m sure a solution will come out eventually
Hi @yanbeemwe , thank you for the additional explanation. Whilst the logic you have stated helps to give guidance on the requirement, it is probably worth noting that this is KNIME and so typical programming logic will often go out the window , so the solution you are given will probably not follow the steps you describe unless there really is no alternative but to hand write it using a script node.
One additional question though… What happens if a string is repeated in table 2?
If for example you had [ A, B, B ] in table 2, but table 1 contained [A, B, C, D, E]… According to the logic as described, this would be considered a match since all elements of the table 2 row are (when searched for individually) found in the table 1 row, but my suspicion is that you wouldn’t want to consider this a match because the table 1 row only contains a single B. Can you confirm. Thanks
Hi @takbb
Thank you for your reply, good to know, at the end of the day if the result is correct everything else does not matter
So if there is a repeated string in the list, it should just proceed as normal. But in my data, honestly there should not be any duplicates in these lists, so really this is not a problem.
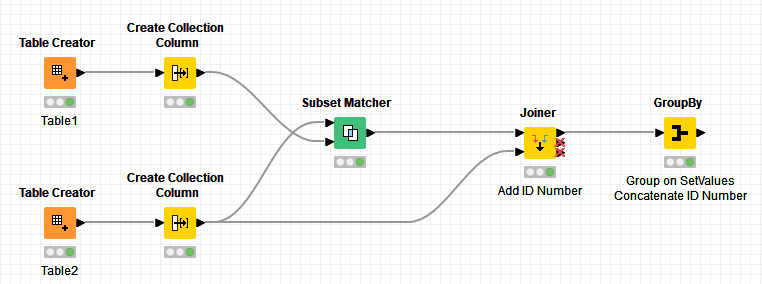
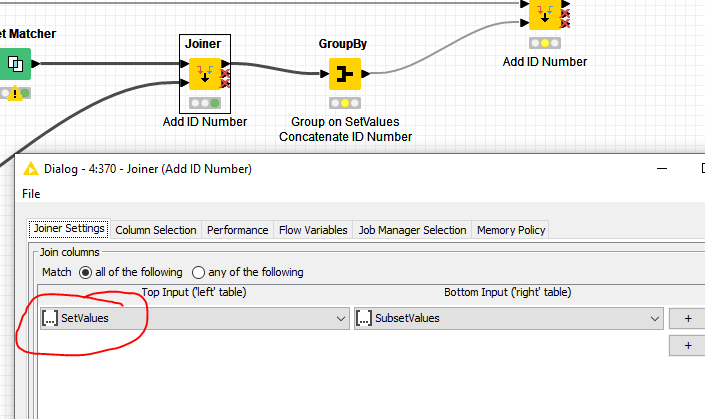
Great find @ipazin, was looking for something like that and went the coding route in the meantime While at it, I connected the full sample table to the node and it appears to do something undesired.
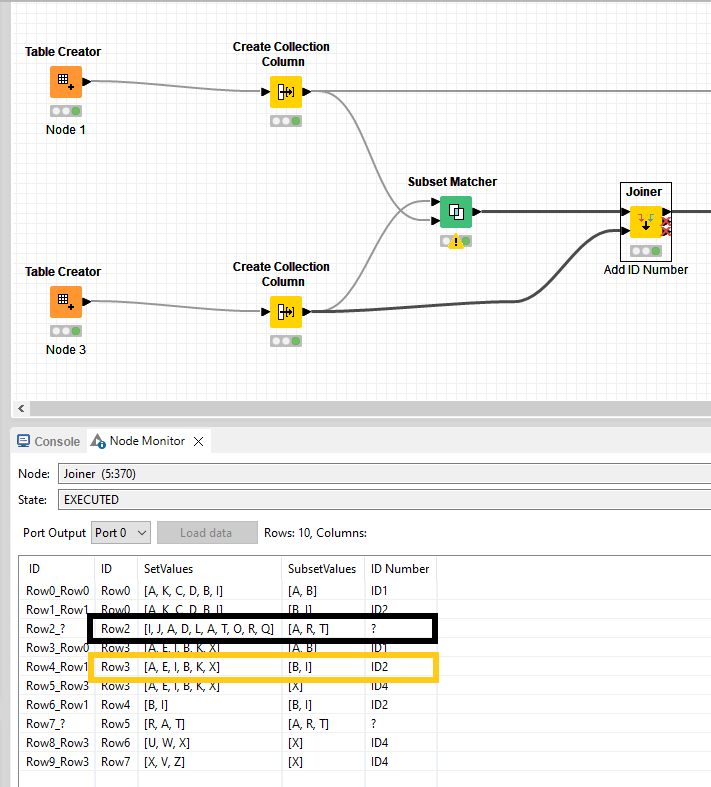
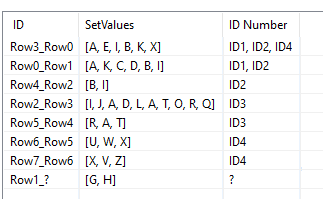
For row 2, the input from table2 is R, A, T while in the string A, T, R is present. The subset node somehow manages to change this to SubsetValues A, R, T. Since this is not present in table2, no match is found for ID3.
row5, which is an exact match also gets left behind because A, T, R is also used here as SubsetValues.
Noticeably for ID 2 (B, I), this issue does not appear. It finds B, I in its original sequence in row0 + row4 and in random order in row3.
This makes me believe that SubsetValues is sorted alphabetically automatically. @yanbeemwe Something to take into account when constructing your table2
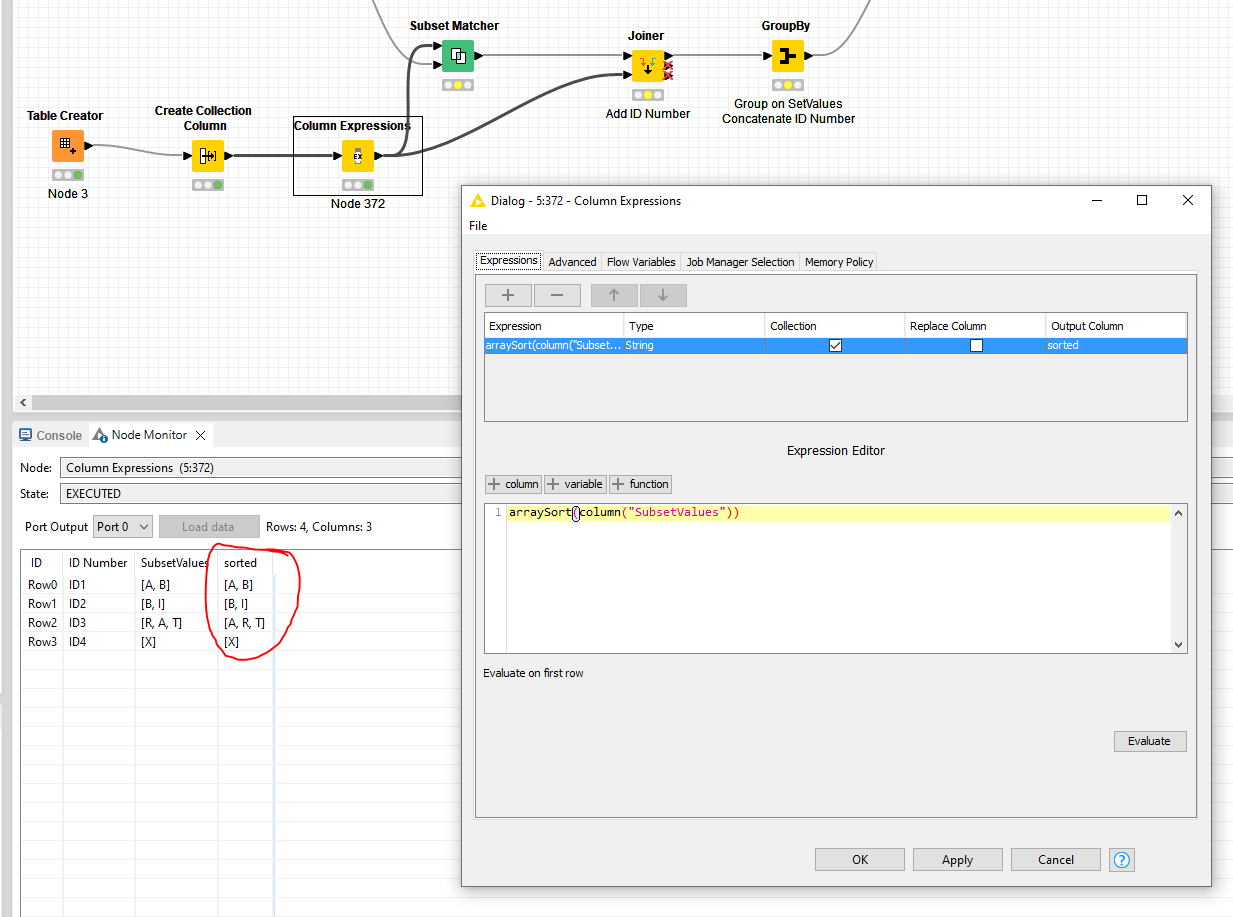
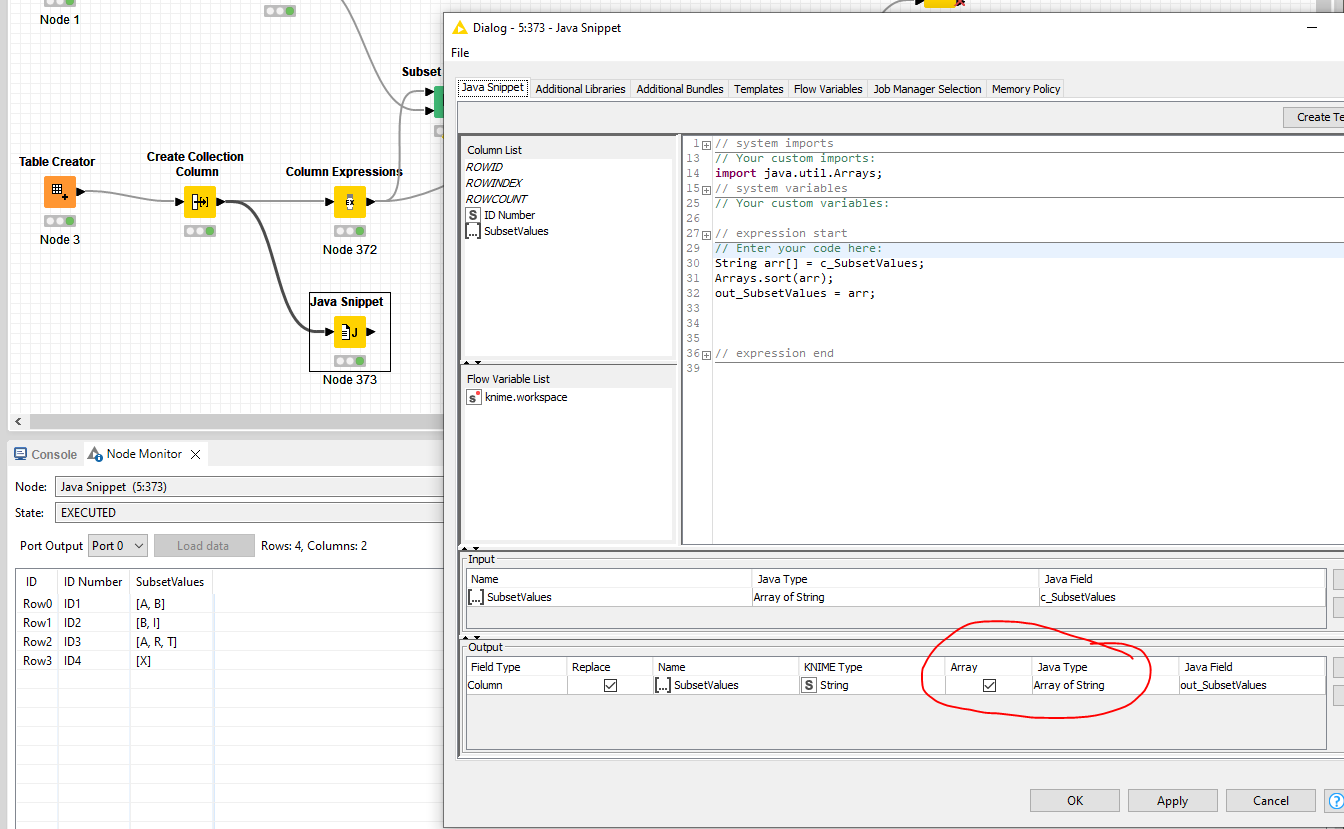
If you want to care of this automatically, use a Column Expression node and use the arraySort() function after creating the collections from table2.
first of all thank you for your input, by the looks of your screenshots it seems to be exactly what I needed, and it is way simpler than I thought!
However, is there a way to do it without the Column Expressions node? Or alternatively is there a way to install this node manually by download it as a .zip for example? I cant do it via drag&drop at my company PC unfortunately
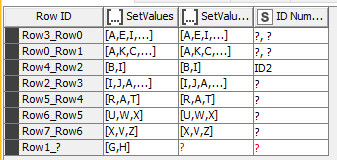
I tried your method because I thought it was simpler for others to understand whats happening. However, it seems to not be quiet right just yet, at least on my side. I tried to debug it but cant come to a conclusion as to why the result does not match the expectation. Here is a modified workflow with the example of my initial post. Is there something Im missing?