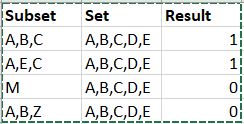
I am trying to achieve something which should be rather simple in Knime but unfortunately I couldn’t find a way yet.
I have one column (subset) with agreggated strings, and I have another column (set) with different aggregated strings. I just want to check whether the (subset) is a part of the (set) or not.
The order of the values inside the subset and the set doesn’t matter, I need to take every single value in the subset and check wether it exists in the set or not.
If all members from the subset exists then it is True otherwise it is false.
Can you please tell me how could I achieve that in Knime?
well once you got columns as sets you can use Subset Matcher. Unfortunately it does more than you need. Compares each row from subset column with each row with set column. To eliminate extra rows use Joiner (right or left outer join depending on how you connect nodes to Joiner) with ID as joining column from Subset Matcher and RowID as joining column from original table and apply Rule-based Row Filter. There you wanna leave all rows where subset column match (means row wise comparison and match) or any column from Subset Matcher column missing (covers rows where no match). Then you only need to add 0 or 1 based on missing from any of above mentioned column. With Rule Engine for example.
A bit tricky but should work. Give it a try and if any questions feel free to ask. Can share workflow example if necessary as well