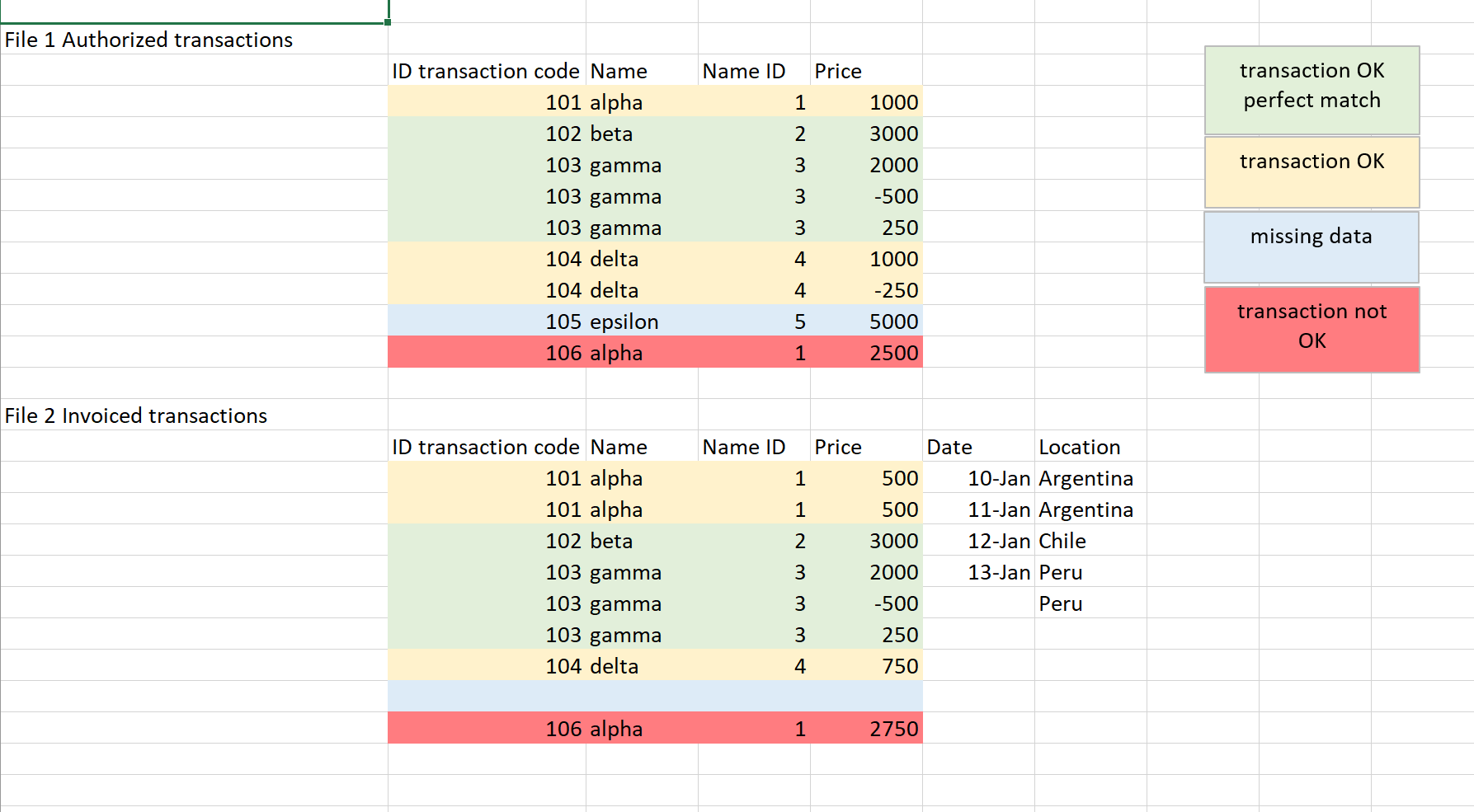
How can I easily improve the comparison between 2 xlsx files (or 1 xlsx with 1 csv) considering that it is a recurring task where data is updated everyday.
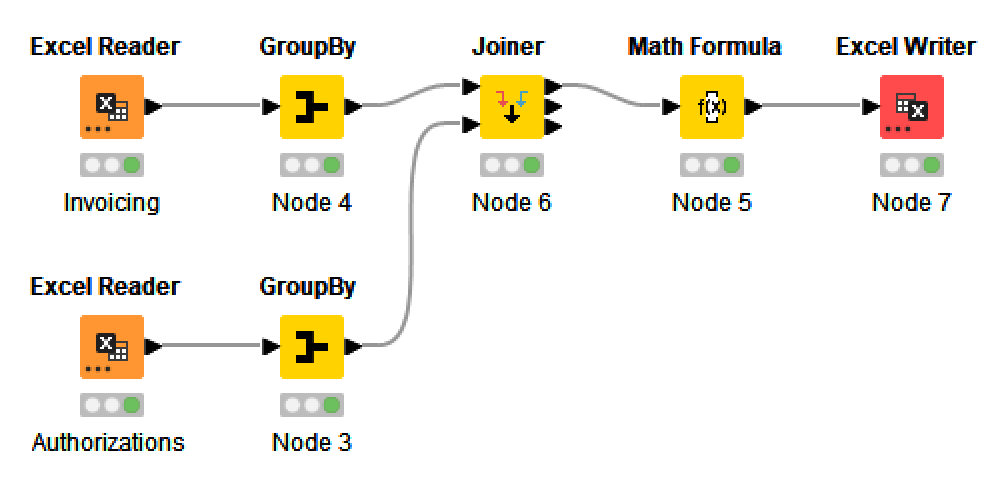
use a groupby node to sum up the prices and then join the data and check whether difference is 0 (e.g. math formula node)
if it is → works
if it is not → not OK
if there is no join mathc → missing
br
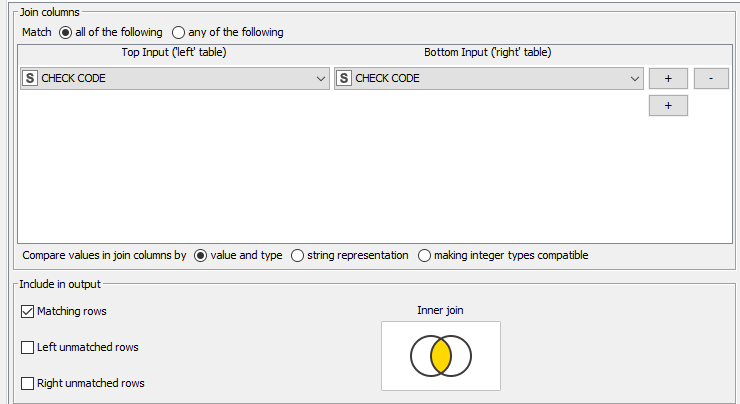
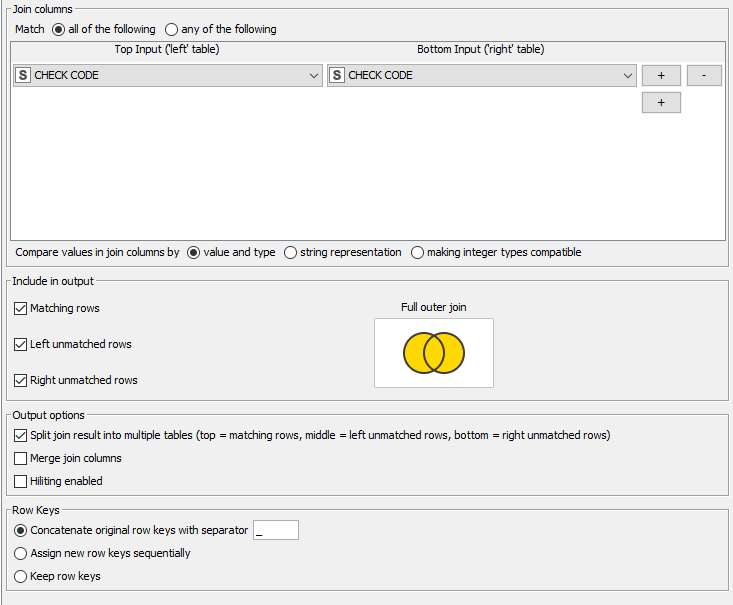
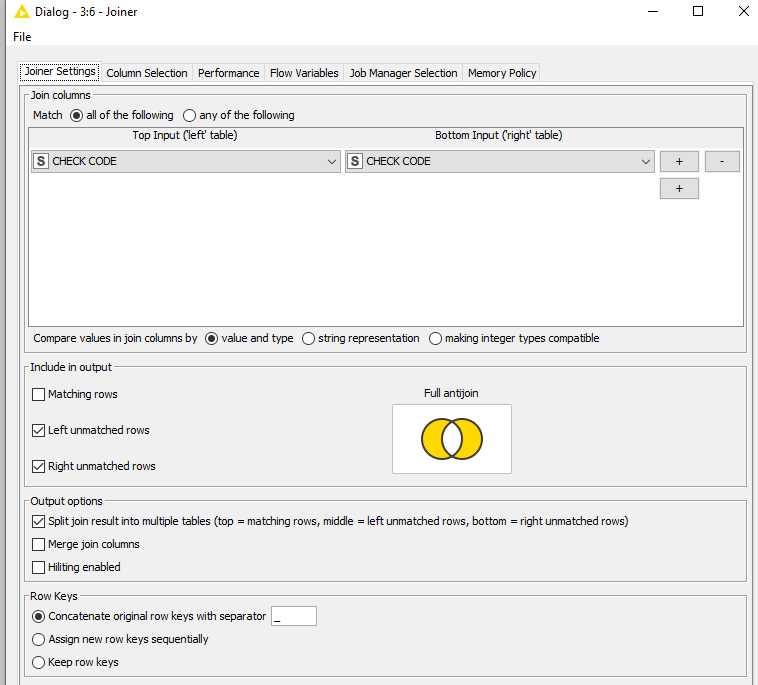
Thankas again for the tip. Solution seems to be promising but I am not sure that every single data is included in the results. For the time being I am under the impression that only full matching rows, and partial matching rows are identified properly.
The rows without match in both files are not identified. I am probably doing something wrong.
Considering the original number of entries in input files(1249 vs 781), even when grouped (631 vs 599), under joining type 1/ and 2/ I get only 541 entries of full matching or partial matching, It seems as I am losing unmatched rows at some point in my output file