I’m having problems doing something which I hope is quite simple. Ideally I would like to solve this without the need for any scripting.
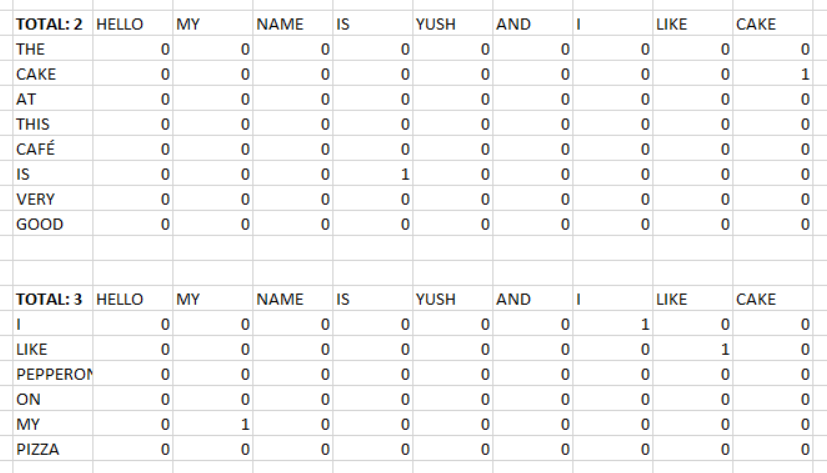
I’ve split a string up into a list of all the words that make that string (max 10). I then want to compare this list of words with those of another string using. I can do this in Excel easily - the first comparison yields a score of 2 and the second comparison yields a score of 3. In this instance I would choose the second comparison over the first one.
Could anyone advise on the nodes I would use for this (preferably a non-scripted solution as I am not fluent in any languages).
@izaychik63, i’m not sure I get your solution. My starting point in KNIME would be the 2 strings, which have been separated into their individual words. I eventually want to apply this to a few hundred examples hence the attempt in KNIME.
@ScottF, does this solution compare each word from 1 string to every word from the other? It looks like the bit vectors generated only compare 1st word to 1st word, then 2nd word to 2nd word and so on. Correct me if I am wrong.
The simplest solution I see for your task is based on Rule Engine (Dictionary). You’ll need to create a rules table based on your control phrase just 9 rules like:
$Test_Word$ = $Input_Word$ Second column - 1.
Organize input words in 2 columns:
Phrase_ID, Input_Word.
Rule Engine will return you the set of 3 columns Phrase_ID, Input_Word, IsMatch.
Now you need to use Group By node to count isMatch grouping by Phrase_Id.
In result table look for maximum by sorting the isMatch counts.
I have done a workflow sketch using Rule Engine node with multiple rules and flow variables. You have got two String Input nodes for your strings, Cell Splitter node to get only words and GroupBy at the end to get sum. This workflow is only to compare two strings. To compare multiple strings to one you would probably need to add a loop. Also to make it work without need to change Rule Engine each time number of words in a string is changed you need couple of more nodes. Take a look and if you will have any questions just ask
@yush - no, the workflow calculates a similarity value, which is basically the number of matching words between the two sentences divided by the total number of words in the set.
It’s fairly straightforward to calculate with only a few nodes, but it may not be exactly what you need either.
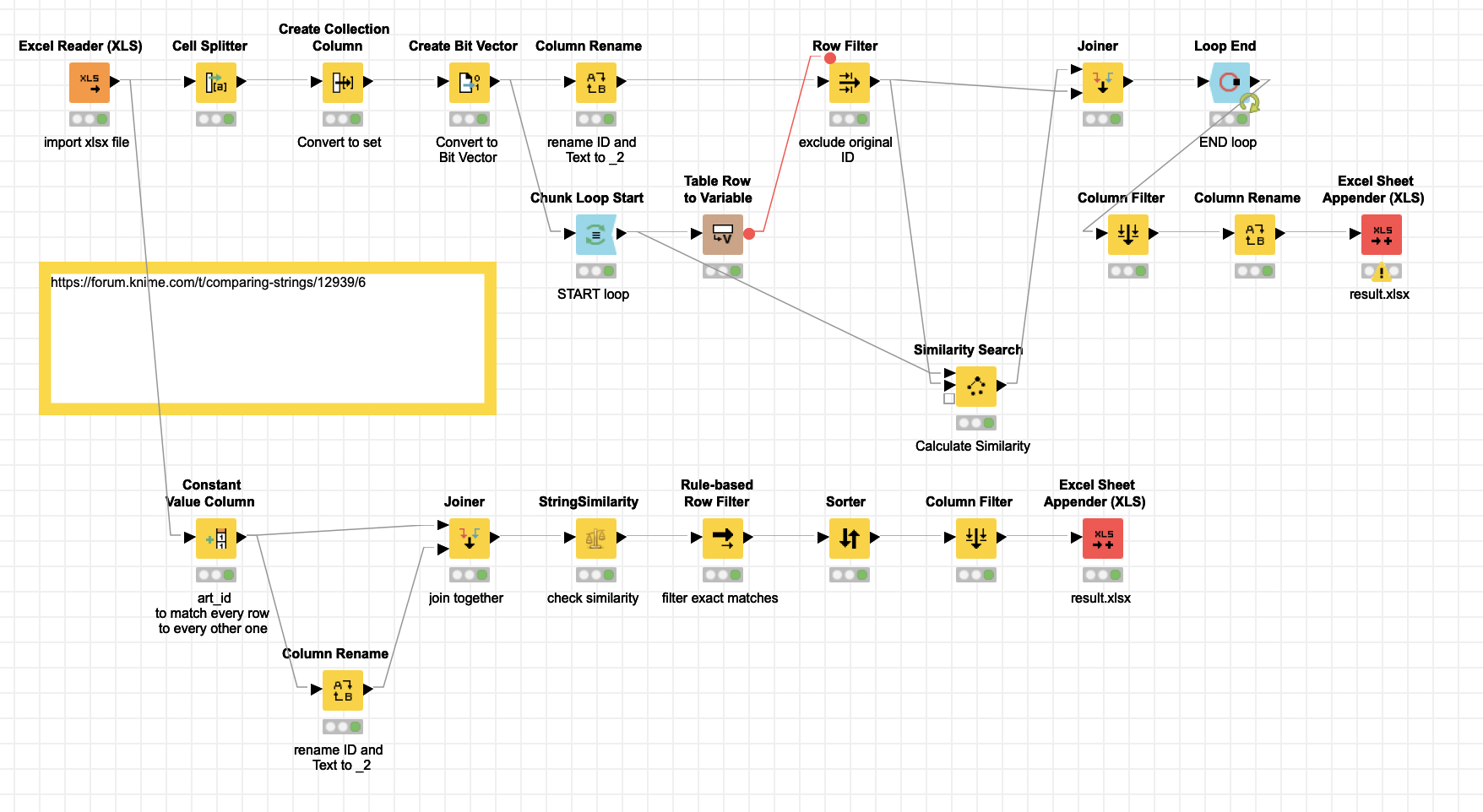
I built a workflow with two approaches. One using @ScottF example and putting that into a loop, using BitVectors.
And one using the
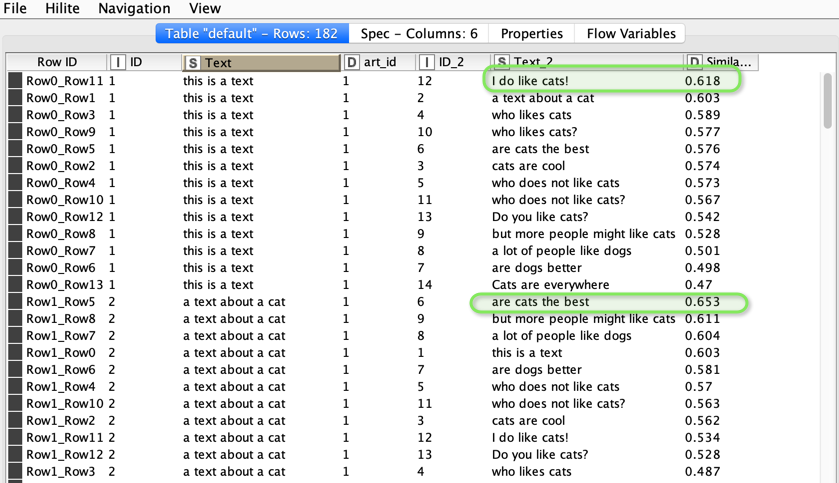
This approach introduces an artificial artificial id (art_id) and joins every string with every other one and then calculates which string is the closest match.
Many thanks to all of you who provided support, especially to those who went through the effort to create workflows. All of your solutions helped in my understanding to solve the problem.
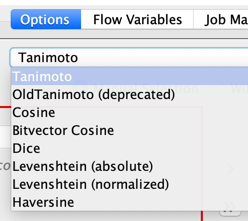
In the end, this is the workflow I used, with the first input containing 61 strings, and the second input with 307 strings. Using the StringSimilarity node, I was able to retrieve a sensible match for each of the 61 strings from the list of 307.