I built a workflow with two approaches. One using @ScottF example and putting that into a loop, using BitVectors.
And one using the
This approach introduces an artificial artificial id (art_id) and joins every string with every other one and then calculates which string is the closest match.
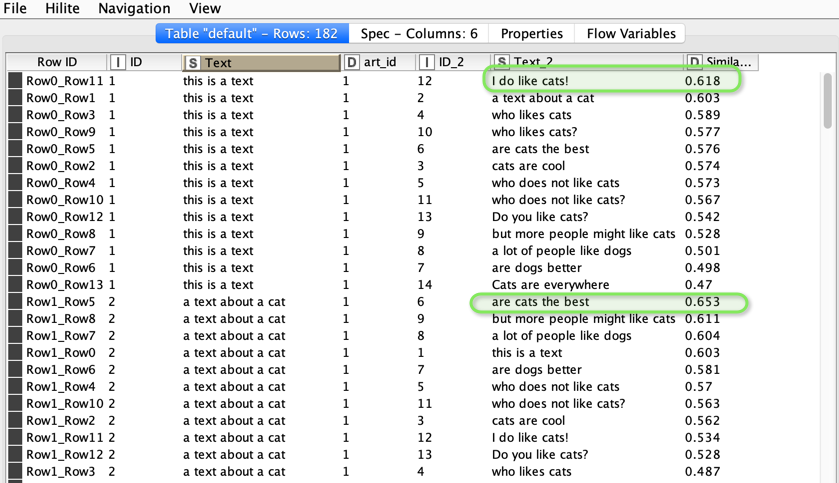
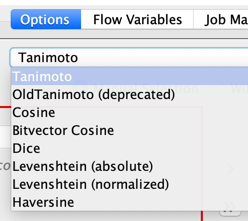
There are several possibilities how to calculate these similarities. You might want to read about them and decide which one is best for your task.
kn_example_similarity.knar (139.2 KB)