I would like to be able to make a comparison between two or more columns of two tables according to different criteria (equality, <,>, contains etc.) and then obtain a single table, is it feasible or do I have to go another way?
Can you elaborate on this a little bit more? This should be possible with a joiner/appender (depending on if they have a key in common) followed by Rule Engine/Java Snippet/Column Expression, etc.
But a dummy example of your current input and expected output would help a lot here so that users do not have to guess what your final expected outcome is.
ok suppose we have the following tables
- s/n * battery * name voltage
- 12569* type A * jude * 3,5 *
- 25689* type AB * law * 2,6 *
- 45069 * type A * arthur * 4,1 *
- s/n * battery * nickname * current*
- 122512569 * type A * J * 2,75 *
- 122525689 * type AB * Long * 2,3 *
- 122545069 * type A * Faray * 4,23 *
I would like for example to join the two tables through the first column in which we see that a serial number has been written in a shorter way than the other table using the condition of contains, or taking the voltage and the current do the division and this it represents the electrical resistance.
I tried with Join but I can’t find a place to insert a condition
I think @bruno29a and @takbb have in the past proposed a solution (which I really like by the way) to write your 2 tables into a database e.g. (SQLite or H2) first and then use the SQL Statement Query which could be very dynamic including WHERE with wildcards and multiple conditions.
Sound like a feasible approach to your challenge as well
br
2 Likes
Hi @pollyste ,
As you have found, there is unfortunately no option on the joiner nodes for making a join based on partial matching of columns, or pattern matching.
There are a couple of workarounds to this as @Daniel_Weikert has mentioned. Out of the box, using an H2 database or similar is a possibility.
A similar method is one I use for the occasions when I need something like this, which is using a component I wrote with Python. This second option does require that you have Python installed along with pandas, numpy and pandasql, but once you have those it is a little less effort to use!
Both of the above require a small amount of basic sql knowledge and may work well.
The non-sql method I have depends on the size of your data set. It uses the cross-joiner node to join all rows in one table with all rows in the other, so for two very large tables this could be impractical, but for smaller tables it works just fine. The idea is that having cross joined all rows, a rule-based row splitter can be applied (after a couple of other “setup” nodes) to match one column with another using the required wildcard pattern.
Attached is a workflow that demonstrates all three approaches. Obviously if you don’t have python installed, the “pandas join” component won’t work for you.
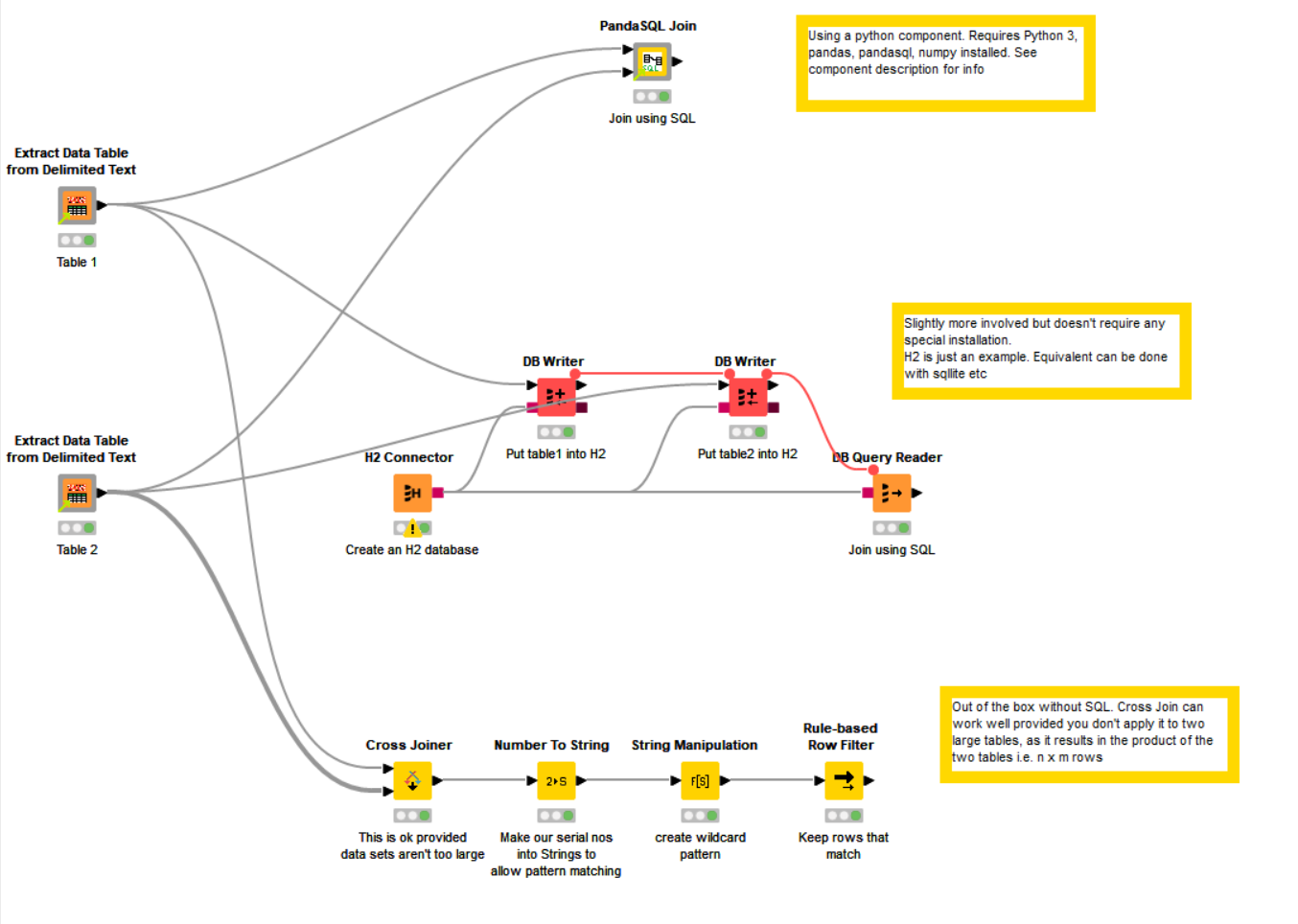
The component at the start “Extract Data Table from Delimited Text” simply allowed me to use your sample data without loads of effort ![]()
Here is the sample workflow
Some options for non-equality joins.knwf (85.3 KB)
2 Likes
So h2 treats double pipes as string concatenation? I first did not understand your “or” syntax ^^
I actually prefer the python solution ![]()
Thanks for sharing @takbb
br
Hi @Daniel_Weikert , lol…
I can see why that might seem confusing given its alternative logical-or meaning in some other languages. It’s funny as I use it interchangeably between languages but hadn’t even noticed its double-meaning until now that you are mentioning it.
Yes double-pipe || is surprisingly the ANSI standard string-concatenation operator in SQL, and shorthand for the concat() function. I believe it is valid for Oracle, H2, SqlLite, MySQL, Postgres and probably others. The notable (I think) exception is SQL Server which uses the + sign.
1 Like
Later I’ll try so I could give you an answer,
because i am working also to another projects.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.