I would like to compare two tables. One created by me where all possible table headers are collected in rows.
The second table is a random Excel data table loaded into the analytic platform.
I would like the program to compare Table 1 and Table 2 and recognize what data I am dealing with (using the header). Then send this data to another method of processing this data (depending on which data was read in)
Probably the main problem is that this data has a different number of columns and the header does not always have to be in the first row.
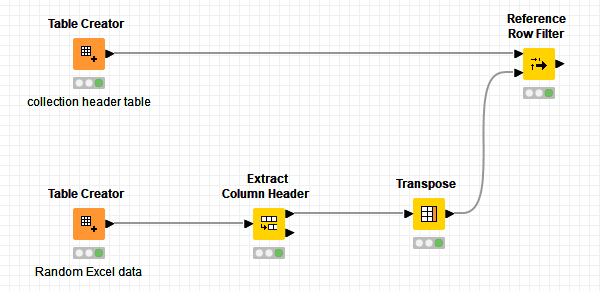
If I got it right you can simply use Reference Row Filter to leave only one row in collection header table. Before that prepare your random data.
Something like this:
In Reference Row Filter you can choose any column from collection header table. Assumption is that column names match. If that is not the case you should play regular expression…
Hi @Sebastian_Baran , in your actual data, will the column names always be completely different between the different table structures or will they actually have common column names?
ie. In your “example” data, you have AAA1-, BBB1- and so on, but I’m assuming that real life isn’t so straightforward, and that your column name list could be more like:
Nr
Column 1
Column 2
Column 3
Column 4
Column 5
1
ID
Name
City
Town
2
ID
Department
Project
3
CODE
Name
Joining Date
Department
Project
4
Name
ID
Location
Grade
5
ID
Name
City
so that there are column names “in common”, and you’d need to match ALL column names (and in the right order??), rather than just the first column name, to be sure of which type of data was represented?
Exactly as you write. I get various data tables with different headers, but I know these headers. Now I would like to automatically, after recognizing the header from the list, pass this data to the appropriate method of processing this data (New Metanode).
Edit
Recognition from just one column is not enough. Some headings may be repeated in the same places and only matching the whole (all the headings from the columns) differentiate them from others.
Thanks for the confirmation @Sebastian_Baran. Here is a workflow that may be able to assist. Replace my “delimited text reader” components (which just enabled me to quickly paste in your example data) with your actual nodes representing data/excel files.
I have used KNIME 5.2.5 for this.
It should work with any KNIME 5.x version. If you are using KNIME 4.x, I’ll have to modify it (and have a small rethink), as you won’t have the Table Splitter node. The Table Splitter enables searching a specific column for a particular value, and then splitting the table at that point. This was useful for the “header” row matching.