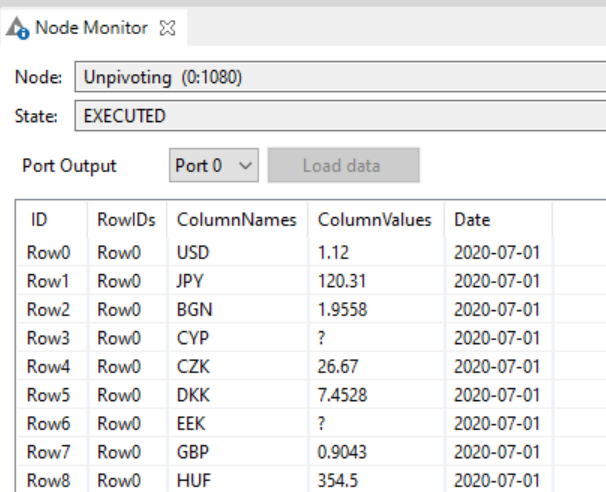
My first table is a list of daily exchange rates in various currencies. Unfortunetely there are only entries for working days, not for the weekends or public holidays.
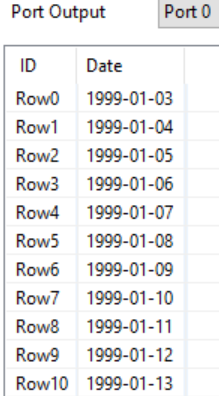
So I created a list of every distinct date since 20 years, which I now want to join with the exchange rates.
For every date where there is no explicit exchange rate, I want to take the d-1 exchange rate. If this doesn’t exist either d-2 etc.
The goal is to have a complete list of all dates with all exchange rates/currencies.
See my data tables below:
Exchange rates (i.e. 2020-06-28 would be missing as it was on a weekend)
A way to deal with this challenge is to create a Group Loop for every value of Currency. Within this loop use the Missing Value node and choose Previous value to impute the missing currency values.
gr. Hans
thanks a lot for your reply. I though about it, and I’m not sure how to implement this. The first table with currencies doesn’t include the missing dates itself. The missing value node can only catch what is in the table itself, correct?
I hope I specified the problem correctly. The single missing values in table 1 are not the problem, I am missing complete date rows which need to be joined in through table 2 somehow.
I tried to join the missing dates and then add data through the missing value node.
But somehow the missing value node only adds the first “previous” date and exchange rate to all missing cells (not every previous date and exchange rate).
Can you post an example workflow, along with some small dummy datasets, that demonstrates the problem? Workflows are often easier to understand than screenshots
See attached workflow, where I added a couple of nodes marked with red annotation boxes.
I think the main problem was that the currency values coming out of the Unpivoting node had an Unknown “?” type - therefore your Missing Value node wasn’t treating them properly. I used a Column Auto Type Cast node to assign these to type Double. I also added a separate Missing Value node for some general cleanup before the loop.
After the loop, you still have some missing values in cases where particular currencies didn’t have a valid value at the beginning of the specified date range. I suspect you will know best how to deal with that.
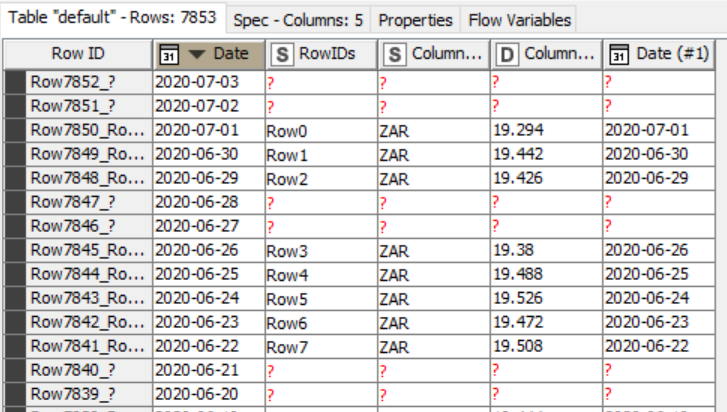
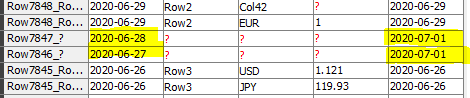
I still have the problem, that for 2020-07-03 and 2020-07-02 I get to add 2020-07-01, but later in the table every missing row also gets 2020-07-01 as a missing value.
I dont understand why the logic breaks, as no date is missing in the table.
Missing currency values shouldnt affect the adding of missing date values?
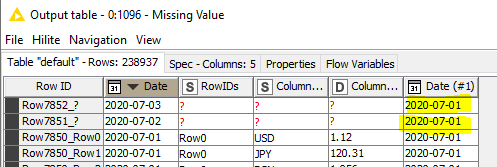
I’m not seeing the same results as you for node 1096. (This is where screenshots get us into trouble. ) My node 1096 is explicitly removing RowIDs that are null since those are non-matches.
It would be good for you to upload the workflow again, I think, so I can check it against what I have.