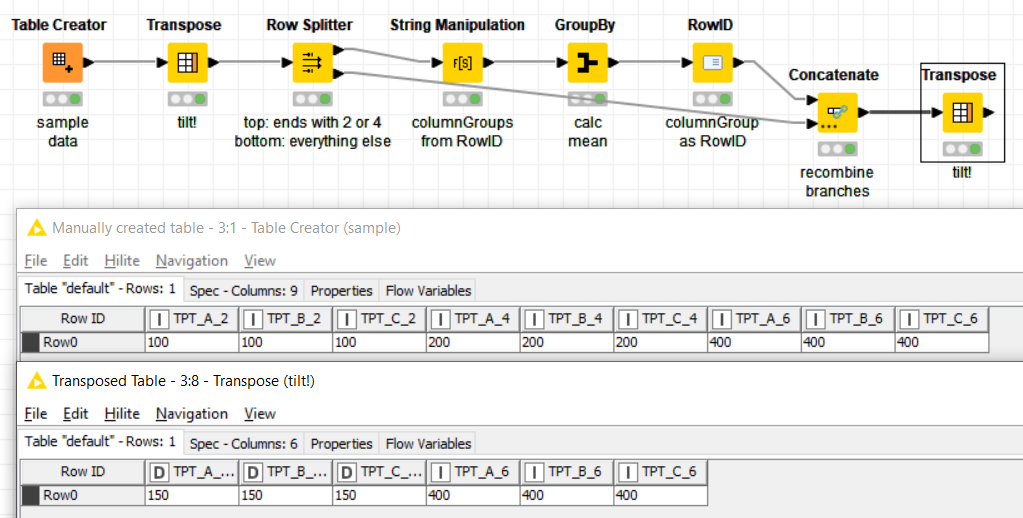
I want to compute the mean for those variables with the same initial substrings as name (TPT_A, TPT_B…) that end with 2 and 4.
So I would get something like:
at first I had something in mind that could be descriped as grouped unpivoting, but since the example dataset has only one row, my solution is a lot simpler.
First, thank you very much for your answer.
Could you please provide some insights on the grouped unpivoting solution? As I said, this was a toy example, and the real datas has many rows.
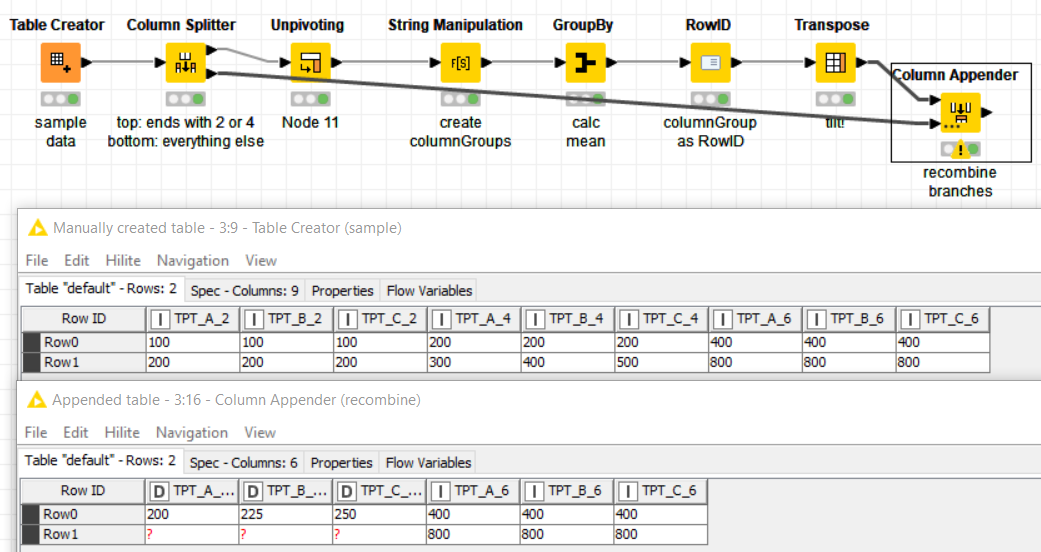
It’s funny that you ask, after posting I had this idea on how to generalise my solution and I went to the “kitchen” right away. Here it is:
split into mean and kind columns
unpivot everything into a single column, no extras
calc mean for each group
transpose
reunite columns (resulting table has empty rows)
This is not what I had in mind, however. Story thyme:
While reading your question, I had this spark in my head: Group Loop Start. Except that it groups rows, not columns. I would have to emulate that behaviour, so the obvious way was to extract the column names, boil it down to the groups, and use a Table Row to Variable Loop Start instead.
Then I could filter the table to one group with that variable.
Not sure how I’d have continued then. I wasn’t even aware of the postfix filter or the 1-row shortcut at that moment.
It might be useful though. Now I know the logical thing would be the unpivot node, but that guy doesn’t even need the Group Columns Loop mechanism.