As you can see, I have multiple variables (var1, var2…) at multiple timepoints (baseline, 1h, 2h)
What I want to do is to obtain the difference between each of the timepoints and the baseline (delta) for all the variables.
So I would have something like this.
I thought about unpivoting for baseline and then applying math formula like in the image attached, but it doesn`t work, as the columns remain with their value:
quick question, is your 3rd line in the result table correct? I think you want the Baseline to be unchanged, but the last entry of Var2Baseline is different.
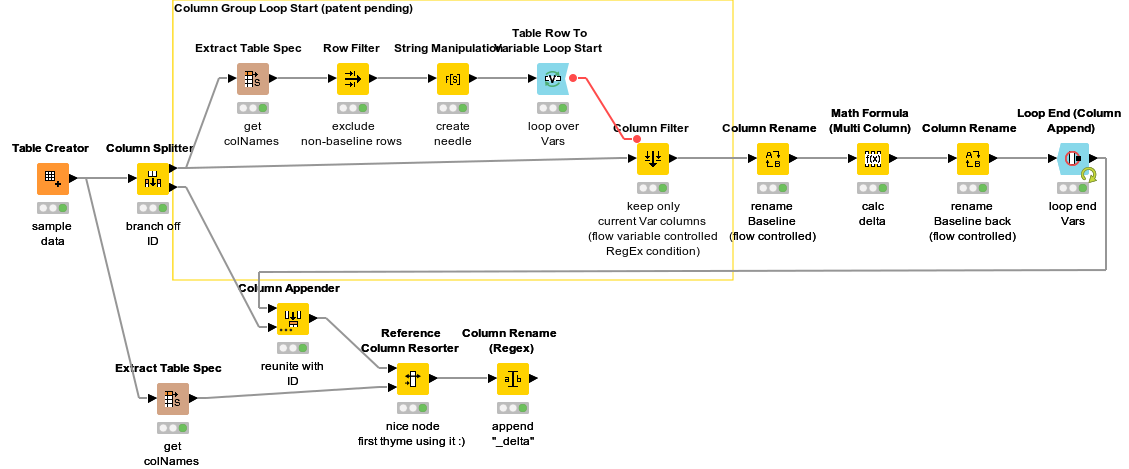
Now for the solution, do you remember what I initially had in mind for your previous question? I think you’ll need the “Group Column Loop Mechanism” here. Link:
Since it’s late, I’ll just describe how it would be done. I can do a workflow tomorrow.
Extract Column Names, exclude non-baseline columns, string manipulation to get the Filter-Needle
Table Row to Variable Loop Start with the table containing the filter needles
Column Filter. Haystack is the original table. Enable RegEx/Wildcards
Math Formula (Multi Column): include all non-baseline columns and do “CurrentCol - Baseline” via RegEx (is that possible? not sure); don’t forget to replace the columns, don’t append (keeps the names)
Column Append Loop End
rename the non-baseline columns to get the proper names
Column Resorter
Sweet Dreams, T
edit: is “Column Group Loop” actually the correct name? not a native english speaker …
Thank you @Thyme , yes, there is an error, the var2baseline in the third row is supposed to be 120, so the delta is -20, but this just an example, but I think the idea was clear.
However I’m not sure I’m following you, if you could give post the workflow that would be great
Yeah, the idea was clear. Two days ago we had a question were what looked like a mistake was actually intended because the algorithm was more complex, so I was making sure
Here’s the workflow with the Column Group Loop mechanism . I changed the end a little bit to keep the ID column. If the column renaming and resorting doesn’t work with the actual table, you could also:
Rename them directly after the Loop End
Extract the column names
Get Var number and time from them, then sort by number and time