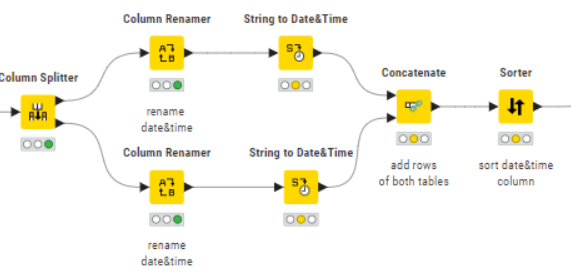
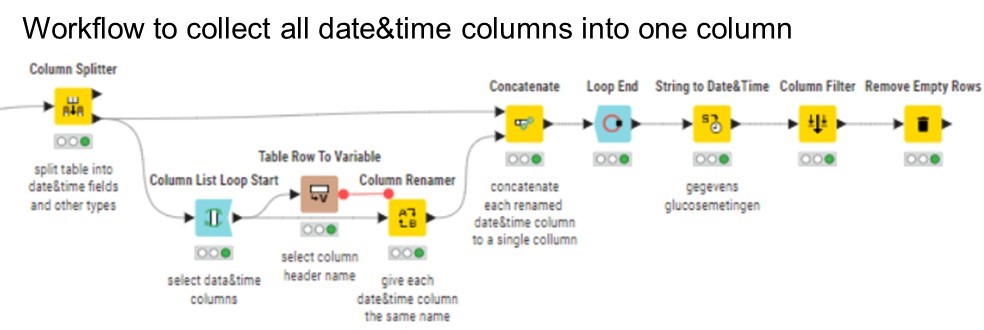
I have a dataset which consist of a number of variables each having its own date&time collumn. I would like to concatenate all date&time collumns into one collumn. The workflow I set up works OK for two variables. My idea is to split four colums using the column splitter into two tables, rename each date&time collumn to the same name. Then both tables are concatenated. This works well (see result below) but I would like to use a loop to concatenate all time columns of all measured variables…
Start situation, each variable has its own date&time column
time1
variablename1
time2
variablename2
29-10-2021 00:01:00
239
29-10-2021 03:50:07
210
29-10-2021 00:06:00
238
29-10-2021 05:49:42
217
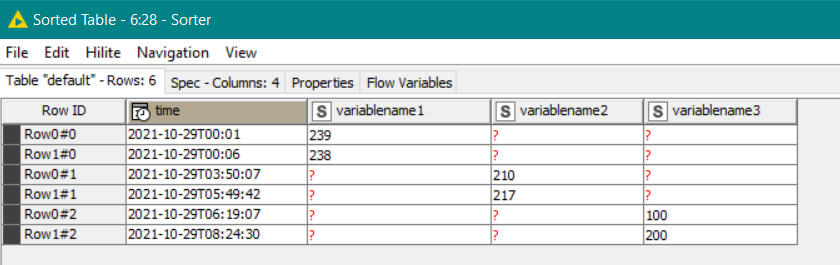
End situation: one date&time column, sorted, hence the datefields use the same date&time column
time
variablename1
variablename2
29-10-2021 00:01:00
239
29-10-2021 03:50:07
210
29-10-2021 05:49:42
217
29-10-2021 00:06:00
238
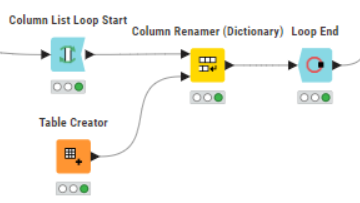
I tried the collumn list loop start node but the time values of one column are overwritten by the time values of the other column.
Your initial solutions with column splitter reflects how I would have gone about the initial task you described but I don’t understand what it is that you are trying to achieve with the loop. Can you show what the expected output would be when you have “concatenated all time columns of all measured variables…”
Is it that your solution needs to be able to do the same thing but with many more than 2 variables, and you need something that can scale to a much greater number?
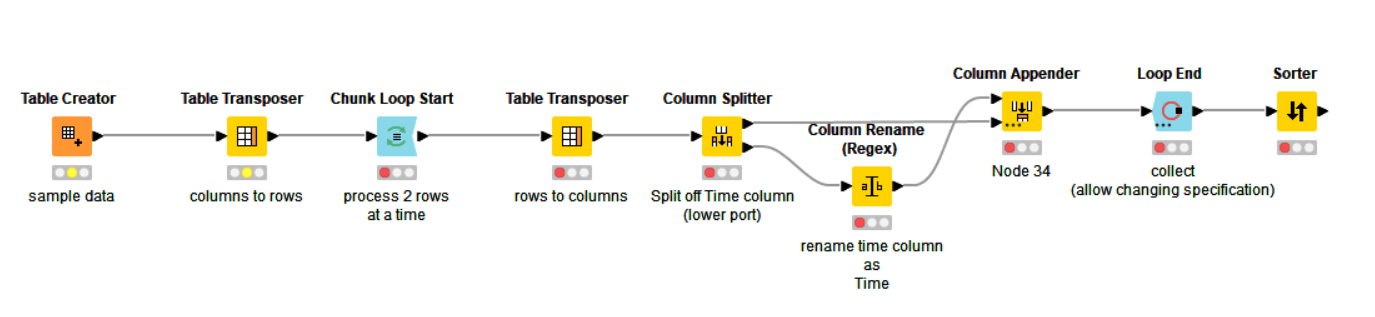
If that’s the case, maybe something like this could be adapted?
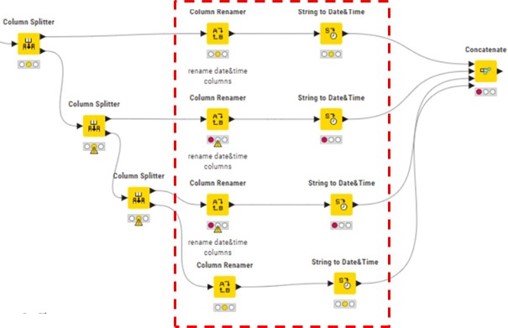
Thanks for helping me. I’m one step further but I haven’t found the solution yet. First let me explain my current solution and result. The dataset contains of 20 variables, each variable consists of one time&data stamp and a measured value. I want to convert the dataset into one table with one date&time column:
In Knime this can be done by splitting the dataset in multiple 2 x 2 columns using the column splitter node.`Hence the same workflow is repeated multiple times. (red dotted rectangle).
However, I would like one workflow using flow variables in order to add new variables without changing the workflow.
I have made a workflow to collect all time columns in one column, however than I loose the connection with the measured values.
@reedere
use all time columns (wildcard selection for new columns if required) and feed them into column aggegator node with list aggregation. Then do an ungroup
br
Hi @reedere , I didn’t see you had replied… if you put @ in front of our usernames (e.g. @takbb) we get notified of a direct response, otherwise it is down to luck whether we see your message
I’m afraid I have not worked out the difference between what my uploaded workflow did, and what you are now wanting. When you say you “want a workflow using flow variables in order to add new variables without changing the workflow”, what is it in the workflow I provided that you would have to change if you added further “variables”.
The output matched your initial output, and if you add more columns of time and variables, it doesn’t require changes from what I can tell.
Perhaps if you could upload some actual sample data, along with the required output, it would be clearer? Then I could try your sample input data into the workflow I did and see where it is not performing as you need.
I have modified the previous flow slightly, but only so that the Time column doesn’t have to be named “time1”, time2" etc, and can now be called anything. It now renames it to “time” based on it being a Local Datetime data type.
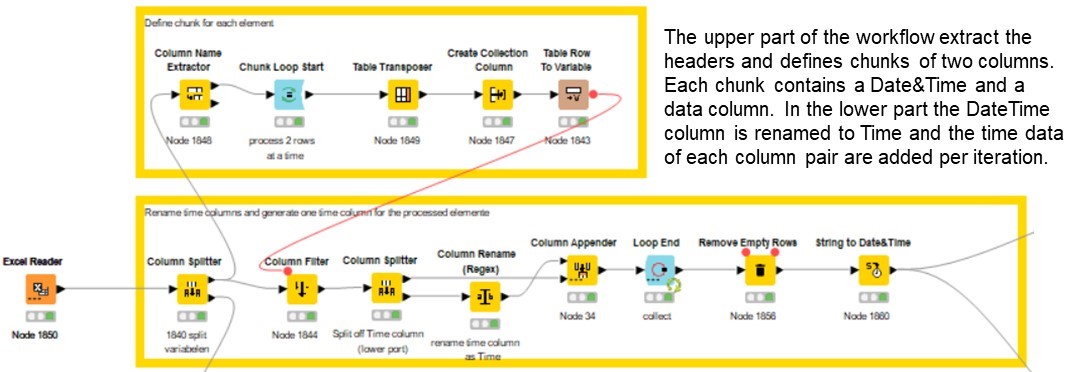
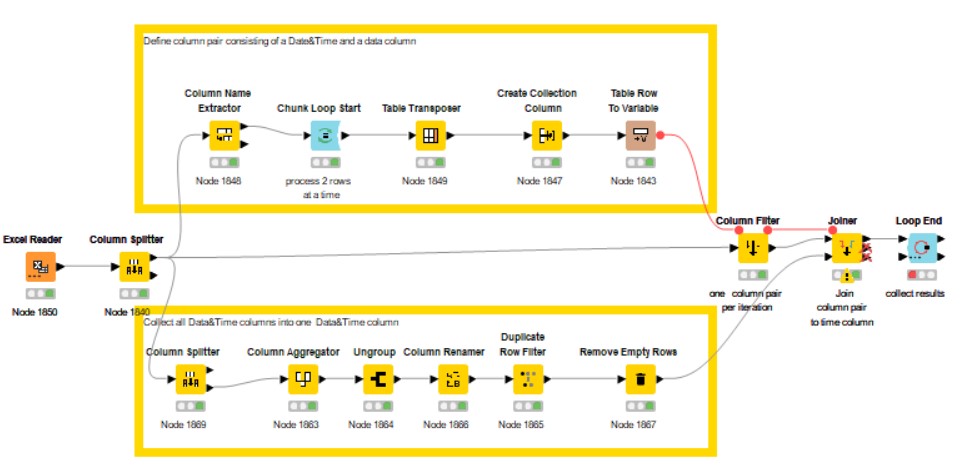
Hello @takbb, thanks for your solution, I adjusted your workflow a little bit. Instead of transposing the data table I extracted the headers of the data table and converted these in an aggregated flow variable where after the flow continues according your solution.
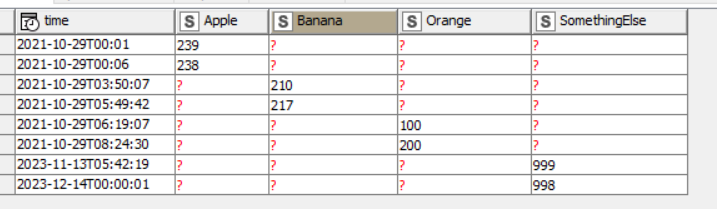
To solve this I tried to the following workflow using one time column to which I would like to join column pairs consisting of Date&Time value and a data column:
The problem is to define the name of the “top left (upper table)”. According to the information I this flow variable setting in the joiner node should work:
The flow variable “AggregatedValues” is deliverd by the Table row to variable node to select the column pairs one by one. But the name of the “top left (upper table)” is not replaced by the flow variable. So, my questions are:
how to solve this and
is this strategy a good solution to get all data having the same Date&Time stamp on one row?
By the way the format of data in the excel node at the start of the workflow is:
Hi @reedere , would you be able to upload a sample workflow including the excel file, as unfortunately I’m having difficulty working this through in the abstract without being able to see what is going on at each node.
Thanks.