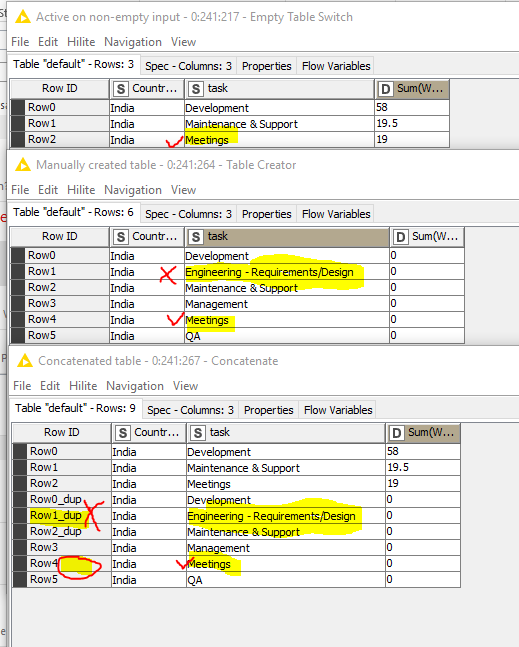
I have 2 tables with values and did a concatenate. The contactenated table Contains all rows from both tables and reports Development and Maitnenance & Support correctly as duplicates. It does not report Meetings as a duplicate, which is incorrect. It also does report Engineering - Requirements/Design as a duplicate, which is also incorrect. .
What I need is a table that contains the intersection of both tables,where missing values from Table 1 that appear in Table 2 are joined / contactenated to Table 1 in the output, which should look like this
India Development 58
India Maintenance & Support 19.5
India Meetings 19
India Engineering Requirements/ Design 0
India Management 0
India QA 0
When I tried to join I got question marks instead of field values, and an article indicated Concatenate and a filter or ROWID was the way to go but that doesn’t seem to get me there either. Any tips?
the Concatenate node only looks at the Row IDs so if you for example have two RowId with Row1 those are marked as duplicate. This is actually something you can decide inside of the node configuration of the Concatenate node.
If you now only want to keep those rows which are duplicates based on multiple columns, you can use the Duplicate Row Filter afterwards. There you can define which columns contain the unique values.