Hi. I’m trying to deploy a model, but it is very difficult to process properly.
This is a workflow to see if you can classify (yes or no) people’s casual answers (natural language) into a specific category. This is an attempt to create a predictive model based on human categorization(yes or no) and deploy it on new data.
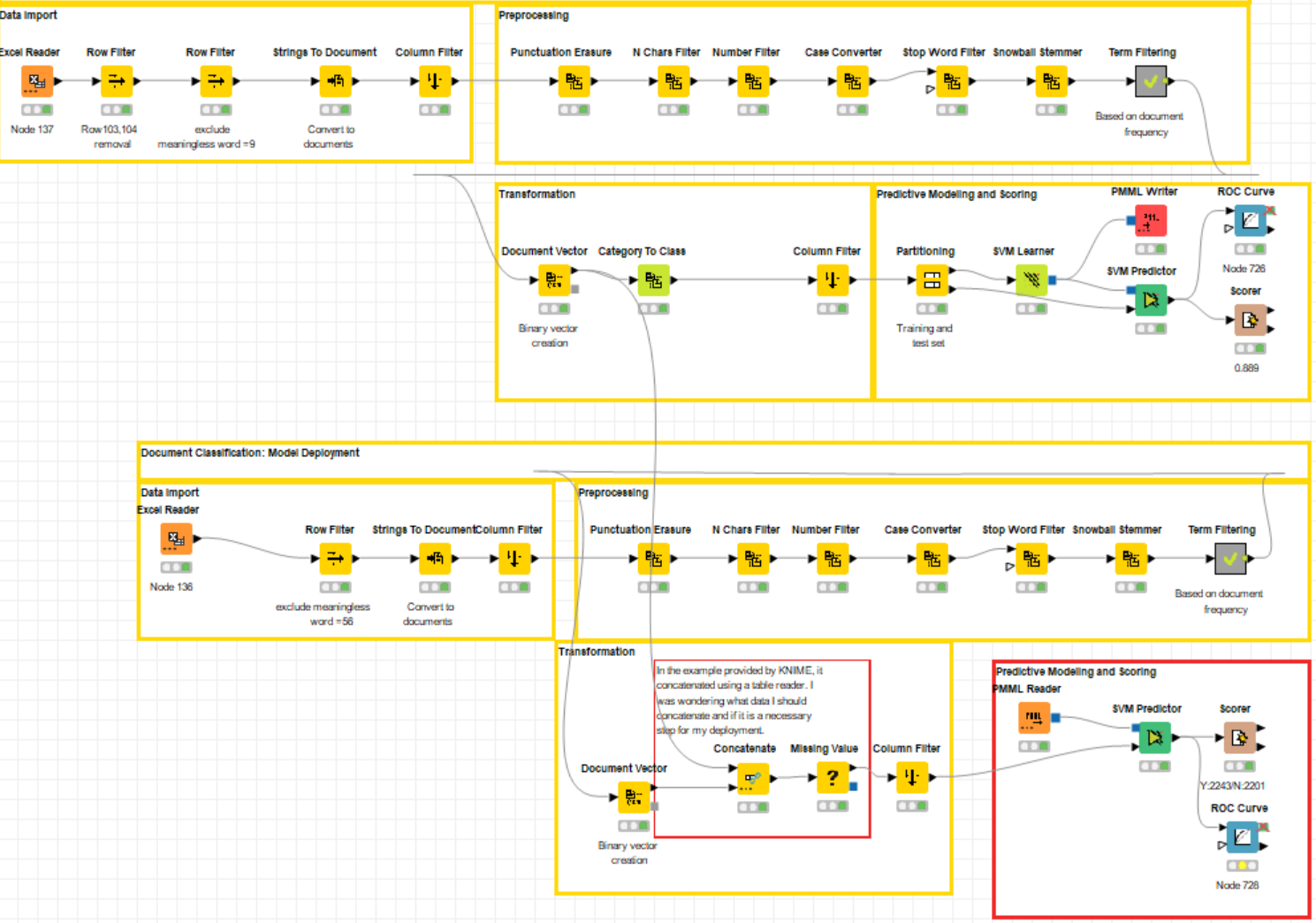

The scores for methods in the deployment is all 1. Above is the result table of SVM predictor. The accuracy of the predictor is 0.889, but it doesn’t make sense that all of them are 1 without any false in the deployment, so I wanted to know how to solve it. I think the problem might be caused by the increased number of columns in the data after concatenation, but there are cases where the term extracted from the predictor is not in the new data to be deployed and vice versa, which causes the error. I don’t think this error occurs in all deployments, but it is not solved by referring to knime hub.
One guess is that the problem is caused by getting the term results used by the predictive model when concatenating in the deployment workflow… I want to, but I don’t know how to solve it.
If I try to process without concatenate node, there is an error that “WARN SVM Predictor 5:99 Column ‘spend’ not found in test data”
It would be very helpful to know the answer. Thank you for your cooperation.