Hello, good evening, I present the following query:
I have several files inside a folder called COLOC, where the format of the files is “.txt” and the name of each file is the following “10102_COLOC1_202201”, where 2022 represents the year and 01 the month of that file, then the other file is called “10102_COLOC1_202202”, where 2022 represents the year and 02 the month of that file, and so on.
All files have the same column structure, number of fields and data structure, finally these files do not have column names (image and files are attached) 10102_COLOC1_202208.txt (2.6 KB) 10102_COLOC1_202209.txt (2.8 KB) 10102_COLOC1_202210.txt (5.5 KB)
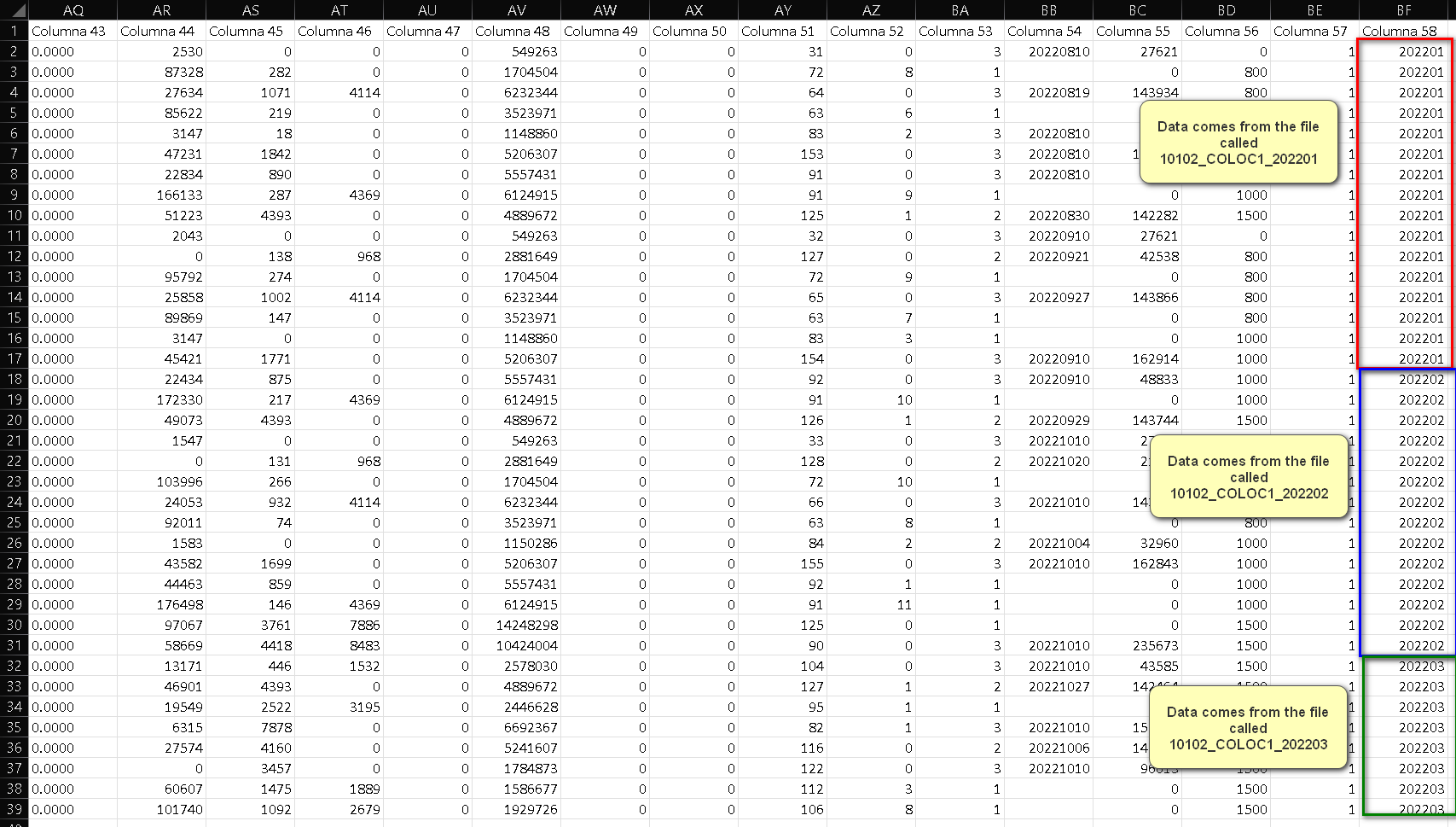
What I do is occupy the concatenate node to group the files in a single base. However, I need that at the moment that it is concatenated, I can identify the date expressed in YYYYMM for each identified and concatenated data (excel image of what I need is attached)
Hi @Pedro87 , the File Reader or CSV Reader nodes allows you to open several files into 1 table for you instead of you having to open each of them individually and concatenate them.
Choose the option “Files in folder”, and then browse to the folder you want the Reader to the read files from.
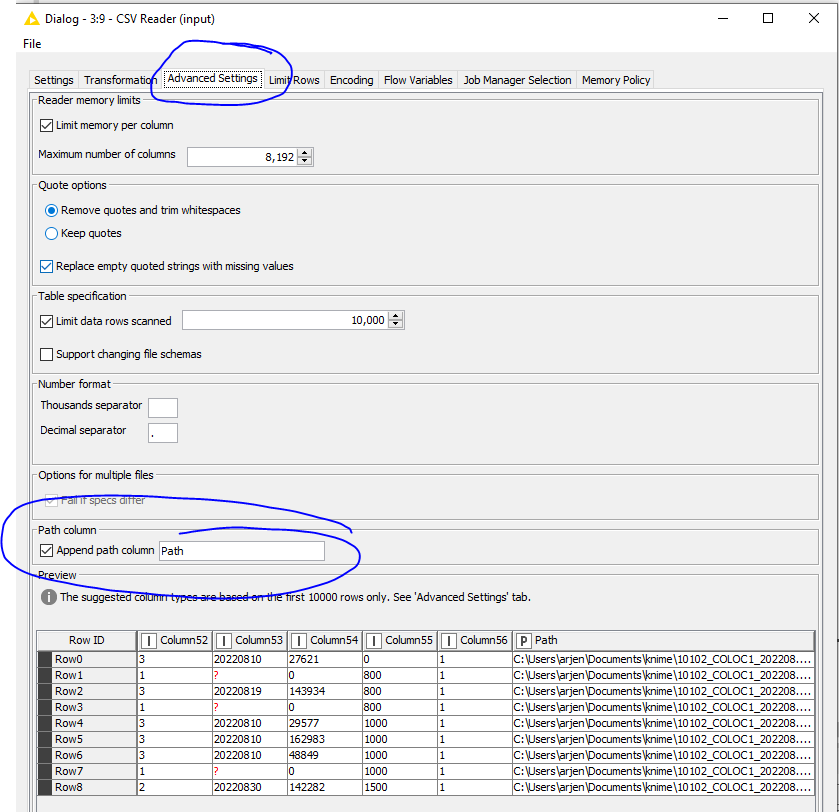
You also have the option to append the path of the file in a column, so with this option, you know which file the data is coming from.
FYI, you’ve not presented to us what the issue is though…
Hello @bruno29a, thanks for your comments, however I expressed myself badly from what I understand, so I present my problem:
Occupying the reader node in csv format to read a folder containing several files named as follows “10102_COLOC1_202201”, where 2022 represents the year and 01 the month of that file, then the other file is named “10102_COLOC1_202202”, where 2022 represents the year and 02 the month of that file, and so on.
The problem is that I don’t know how to add in a new column the periods of each file in YYYYMM format where YYYY is the year and MM is the month and that they correspond to the corresponding data
Example: for the file called 10102_COLOC1_202201 and 10102_COLOC1_202202 (an image of the expected result is attached)
As @bruno29a already mentioned, you have the option to add the path from the file in a column…
You can convert the Path type column into a String with ‘Path to String’ node.
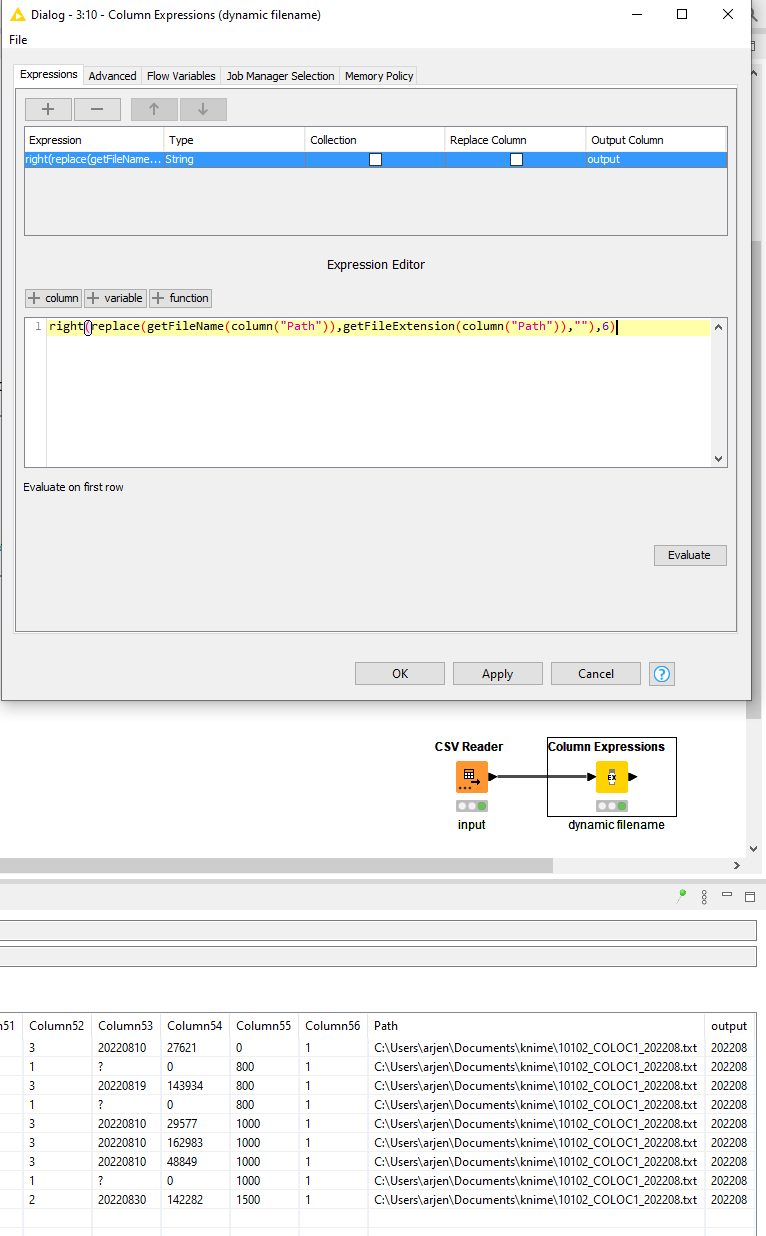
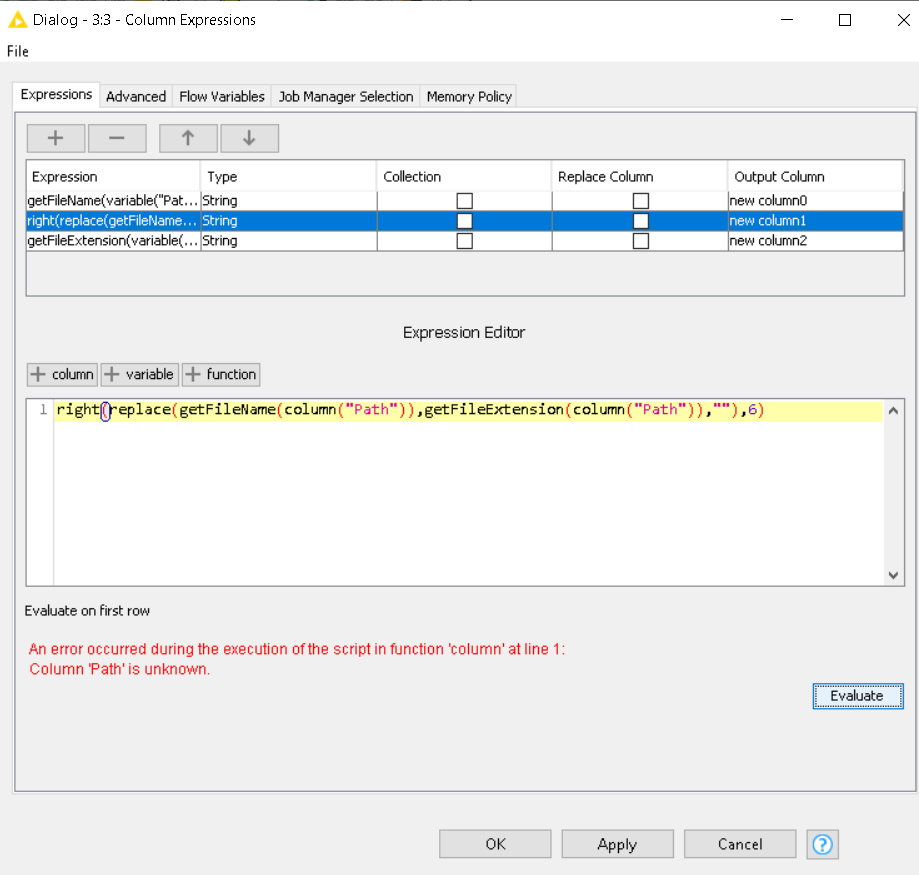
Then, as your file name is standardize, the position of characters in column $Column 58$ within your example, it is always starting 10 characters from the end of the path string and a length of 6 characters.
You can extract this character sequence from the string Path with the ‘String Manipulation’ node:
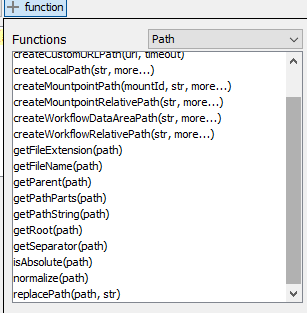
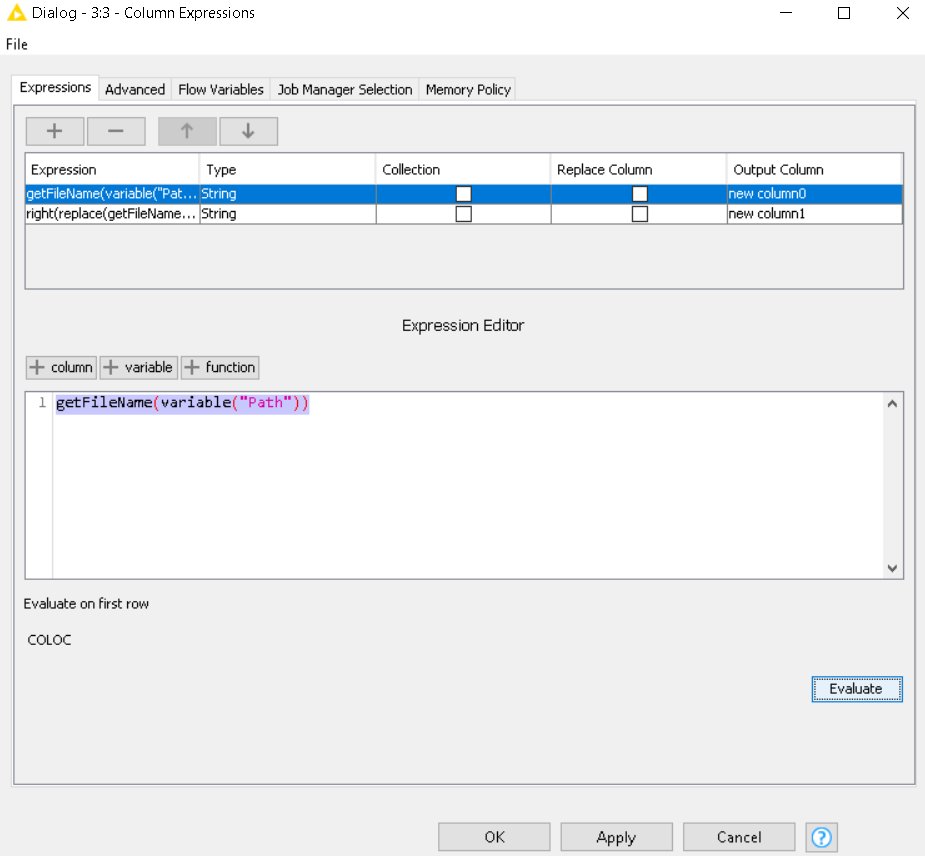
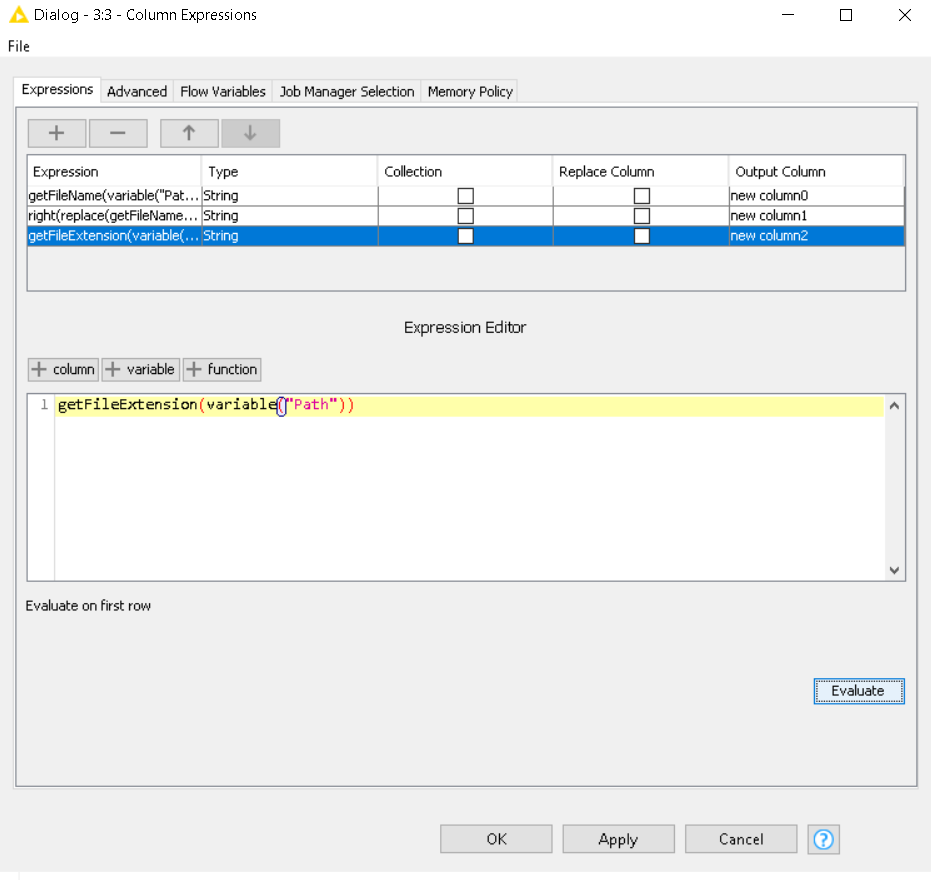
To add for future reference, KNIME has some direct functions related to Paths which takes away the requirement to convert it to a string first (available in Column Expression).
Thank you very much for your comments and help. I’ll start at the beginning to explain if what I’m doing is correct since I try to execute the workflow and I get an error
Step 1
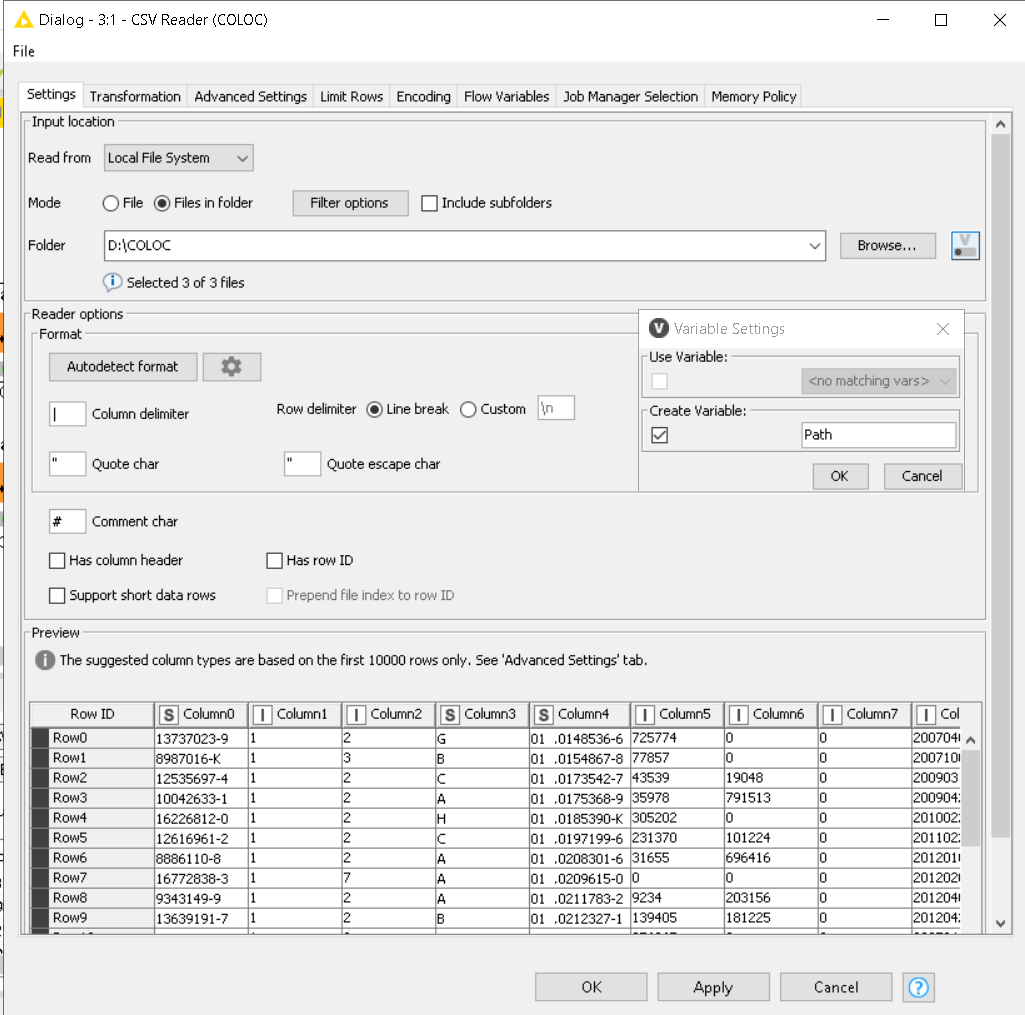
In the attached image I have the csv reader node and I create a variable called “Path”
We are all referring to this function under the advanced section of the CSV reader You should not go the flow variable route here since you are dealing with multiple files.
Dear, thank you very much for your support, I did not understand exactly what you were telling me since my language is not English and I have to translate the messages into Spanish and vice versa, therefore the accuracy of the messages is lost, since the google translate is very literal
For translations you might want to try deepl.com. My impression is the translations are much better.
————-
Para las traducciones, puede probar deepl.com. Mi impresión es que las traducciones son mucho mejores.
Para traduções pode querer experimentar o deepl.com. A minha impressão é que as traduções são muito melhores.
Pour les traductions, vous pouvez essayer deepl.com. J’ai l’impression que les traductions sont bien meilleures.
Per le traduzioni potreste provare deepl.com. La mia impressione è che le traduzioni siano molto migliori.