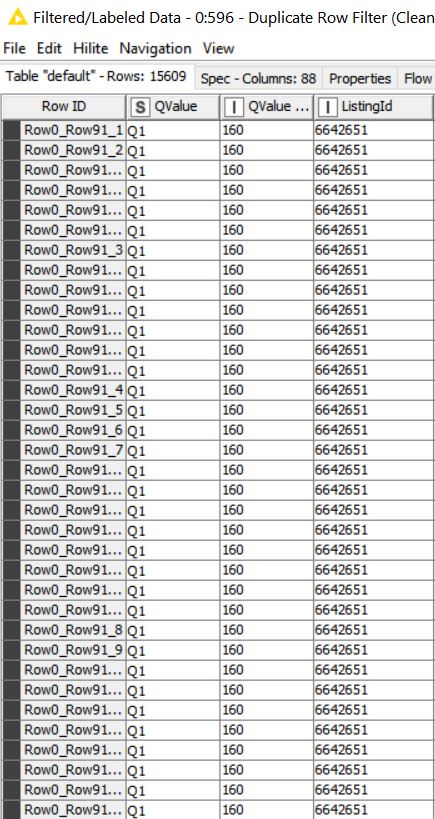
After many steps I have a table with unique categories by column. Each row has a unique identifier tying these column categories and their range of cell values (string and integer) together (see “temp1” graphic here “ListingId” column header).
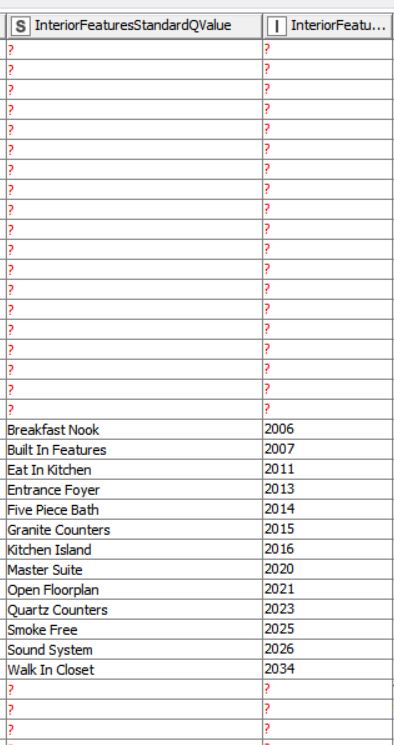
Using text processing the string values are standardized text descriptions and the integers are additional identifiers for each of the standardized text. (see temp2 file here)
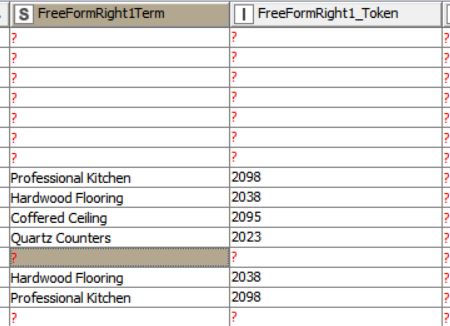
The text analysis is completed on both a series of matched drop-down values at the point of input (I call these Pre-Set values) and also on Free-Form text which I join after processing. Sometimes I discover and label the same values (text and identifier) for each unique property. I need to remove this redundancy when the strings and identifiers match. (see temp3 here) And note how the first set of data and the second set of data both contain “Quartz Counters 2023” for the Property ID 6642651
I am working on a many step, convoluted means to remove redundant Values and Identifiers, but am hoping for a far more concise method from you. The table is fairly large with 15609 rows and 88 columns, so my convoluted method is really beginning to suck. Each column is a different header title, so anything related to “Duplicate Row Filter” won’t work.
thanks