Hey Everyone,
I have a question regarding a small problem I’ve been having.
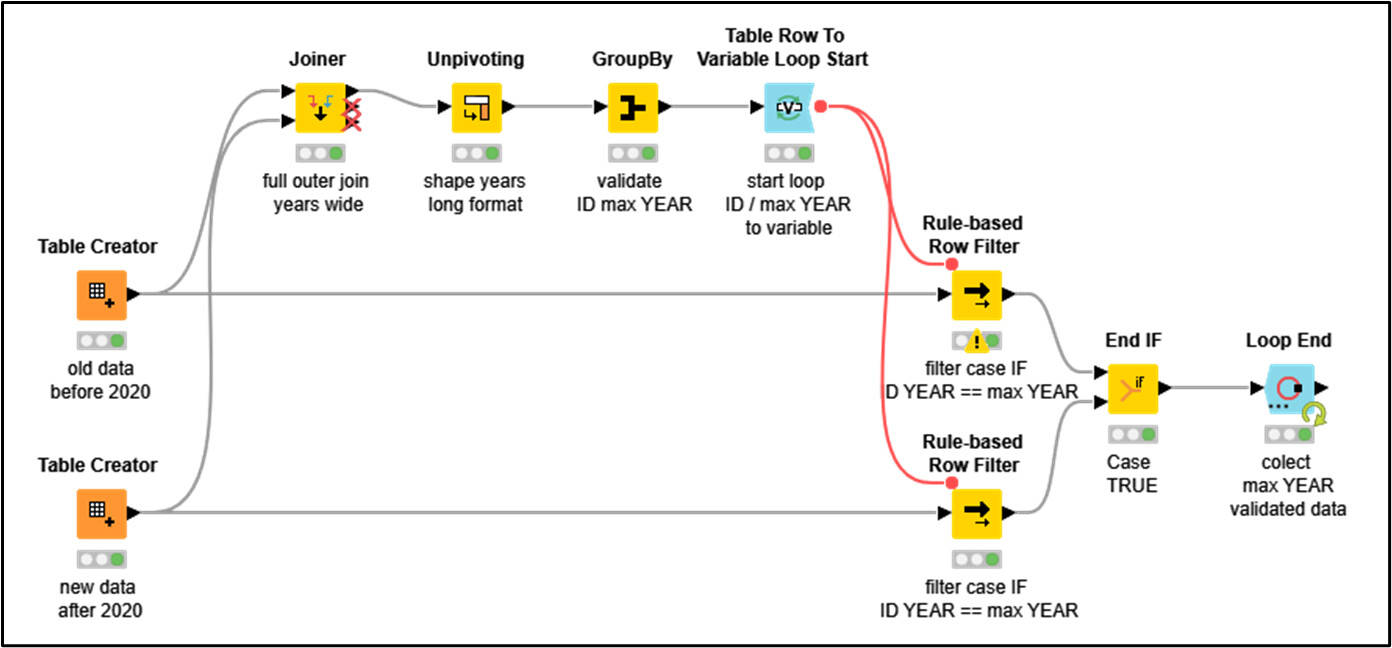
Basically, I have two big tables (Table1, with more recent data, Table2 with more historic data. All with column data from 2015 to 2022) that I need to merge together using a loop and a condition.
The condition being : I have a column named ‘YearMax’ and I implemented a loop in order for it to check the ‘YearMax’ value for each row and all the years that come AFTER take the Value X (I will use that Value X later on in order to fill it with data from Table1).
It goes something liek this : Loop starts → Checks the value of 'YearMax" for one row at a time → ‘YearMax’ value equals 2019 → All rows after 2019 (2020; 2021,2022) take value X → Loop ends with all rows → Column expression to fill the Xs with an if statement.
Could you give me a clarity on how this could be implemented? i would be very grateful!
Thanks a lot everyone.
PS : in case it’s not clear please leave a comment with your specific question and I’ll answer it as soon as possible.
Hey,
Thank you so much for the workflow! it makes things a bit easier to understand.
Could you please share the workflow with me? I’m interested to see what kind of data were used in both tables and what the results of Unpivoting and GroupBy nodes are.
Hello @RDamoNR
You can download the workflow from the link to my KNIME Community Hub, in my previous post; there is a download icon in the upper ribbon. I just created a very simple dummy dataset.
Thanks @gonhaddock I really apreciate the help!
I was wondering, if in the same context but in a different way than using the ‘Missing value Node’ I could reach a conclusion with this example (desired outcome is picture 2) :
This is my table before, as you can see, if the Cutoff year is, for example 2017, an ‘X’ is automatically placed on the next year ‘2018’. The conlusion I want to reach is the same as before, I want to have all the rows after the specific ‘X’ row to also contain the value ‘X’.
Example :
Hello @RDamoNR
I cannot deliver any workflow till evening. But it is a simple operation… you can unpivot the Yearly column headers (as in the sample you can use regex filter for unpivots \d+, and retain $CutoffYear$). Once unpivoted in $ColumnNames$ and $ColumnValues$, it can be edited with a ‘Rule Engine’ node.
Code for numeric columns (then you will want to use String to Number node):
$ColumnNames$ <= $CutoffYear$ => $CutoffYear$
TRUE => "x"
Because of the “x” this Rule Engine will return a String column, as in your example. Removing the second row of the code you will get nulls back.
Afterwards you will reshape back your data to wide by ‘Pivoting’ node.
BR
P.S. By providing your samples as text, knimers in the forum won’t have to type the tables, generating solutions in a more efficient way.