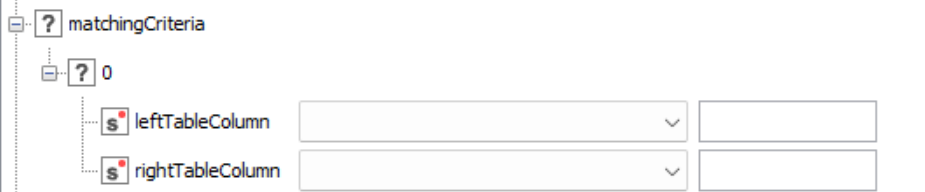
I would like to perform a JOIN between to tables with identical schema based on a configurable set of columns. To pick these, I would use the Column Filter Configuration node to get a variable that represents the array of selected columns. But then, how do I pass these to the Join node?
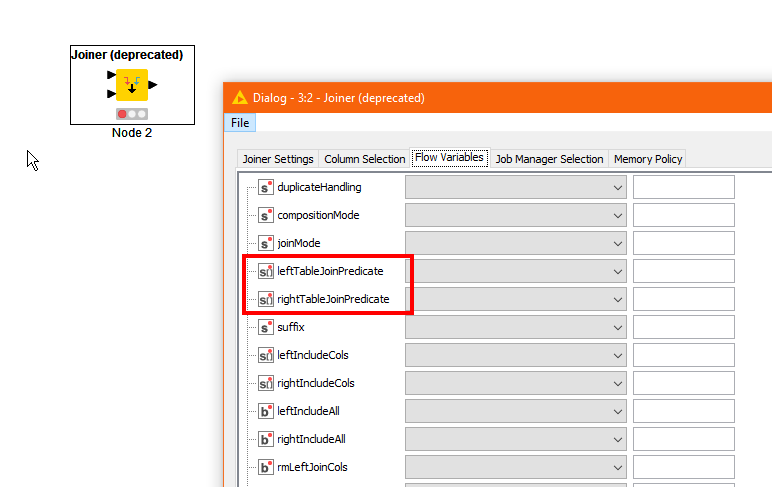
In Knime version 4.3.0 there isnt the option to configure the join predicate as an array of strings
Thanks for clarifying. I can certainly see why that change would be problematic! I admit I am not a fan of the non-array configuration of flow variables for such nodes as it makes it very difficult, if not impossible, to configure them programmatically, as you are demonstrating.
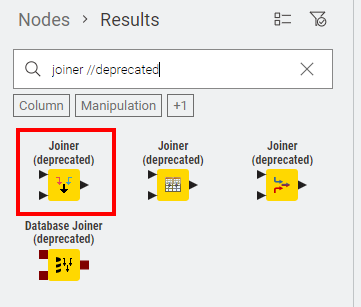
The only thing I can suggest at the moment is searching the node repository for the deprecated version of the Joiner node, which is still available.
(I think you may have to switch in Modern UI for this search to work, if you are currently using Classic. You can switch back again after you have found the node and included it on your workflow)
search for:
joiner //deprecated
and make sure to choose the node shown in red below, as there have been several joiner nodes deprecated in the past!
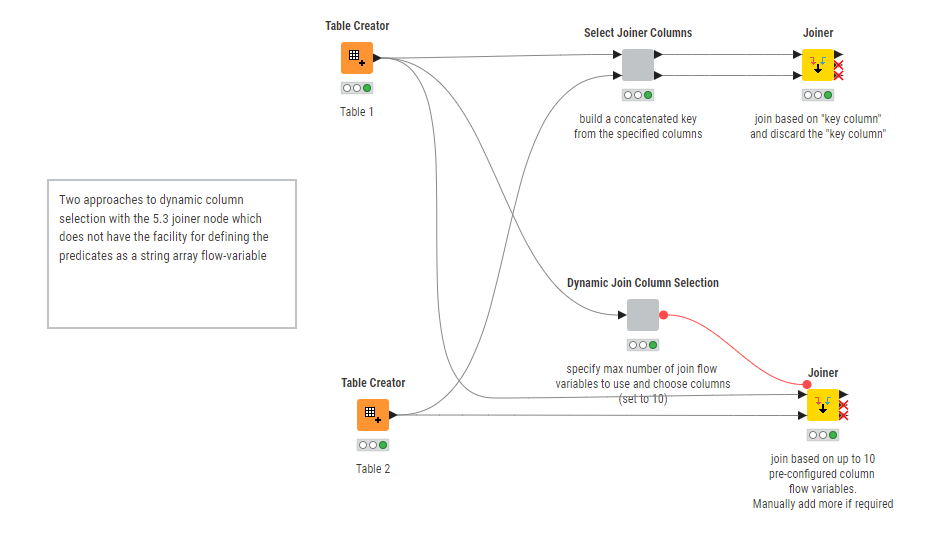
Here are a couple of mechanisms for dynamic joining using the newer (5.3) Joiner node. It’s not particularly pretty.
The additional functions have been added in components on the workflow to enable column selection. One mechanism is to create a concatenated key of the selected columns from the two tables and have the Joiner join using just that key column.
The second mechanism is to define a series of flow variables for a predefined (maximum) number of columns, and have a component generate the flow variables. The joiner node is pre-configured with, say, 10 join predicates. The component generates this number of join flow-variables; repeating the first predicate if there are fewer than the (10) defined predicates.
Hi, @takbb I take a look at your workflow and I made the connection with a old problem I have : in your workflow, it is assuming that first colmun selected in table 1 match first column in table 2. I search for a selection widget for : for each of the column chosen in table 1 (so an arbitrary number of column), user can select a value (take in the list of columns choosen in table 2) ie a generalized Value selection widget. Is the solution straightforward or may I create another post ?
Best,
Joel
Hi @JPollet , the “solutions” I gave were intended to answer the specific question from @marcandavi2 in which they were trying to join two tables that had identical schemas. They are very much a proof of concept and I think generally it would be better to use the deprecated nodes than to try to work with the suggestions given, so I think should be treated more as an academic exercise than a production solution :-).
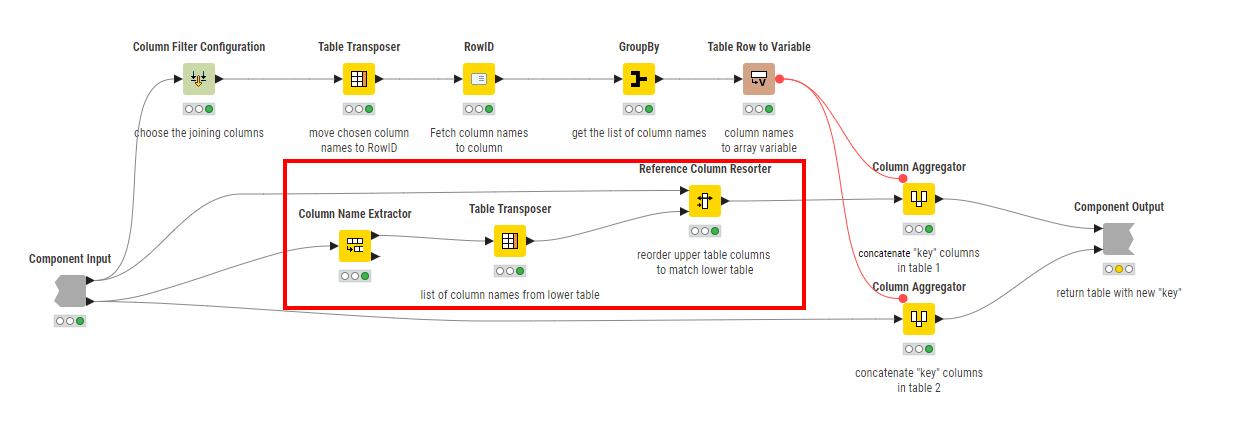
You are right that the first (upper) solution, which creates a key from column aggregations would work only if the chosen “join columns” were in the same order on both tables.
To make the upper solution (using column aggregations) work regardless of the table column order, it would be necessary to ensure that the column order was the same in both tables when generating the column aggregations.
This could be achieved by modifying the upper flow’s “Select Joiner Columns” component as follows:
This still pre-supposes that all of the column names to be used for joining are the same in both tables.
The lower solution in that workflow simply requires that columns in both tables have the same names, and should work regardless of whether the columns are in the same order.
There are limitations to the configuration/widget nodes in terms of building components and the amount of control users have over selections and ordering of selections, which I think is what you are asking about.
I think if the above doesn’t provide the answers you are looking for (and I suspect it doesn’t ), then it would be better to create another post as you have suggested, and give more detail of the specific scenario you envisage.