Need help with a certain task in front of me. Guess it can be solved in couple of ways but I’m mostly interested if it can be accomplished with KNIME Network Mining nodes.
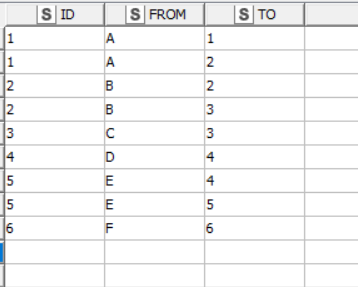
I have table like this:
Group
Value
A
1
A
2
B
2
B
3
C
3
D
4
E
4
E
5
And would need connected groups:
Group1
Group2
A
B
A
C
B
C
D
E
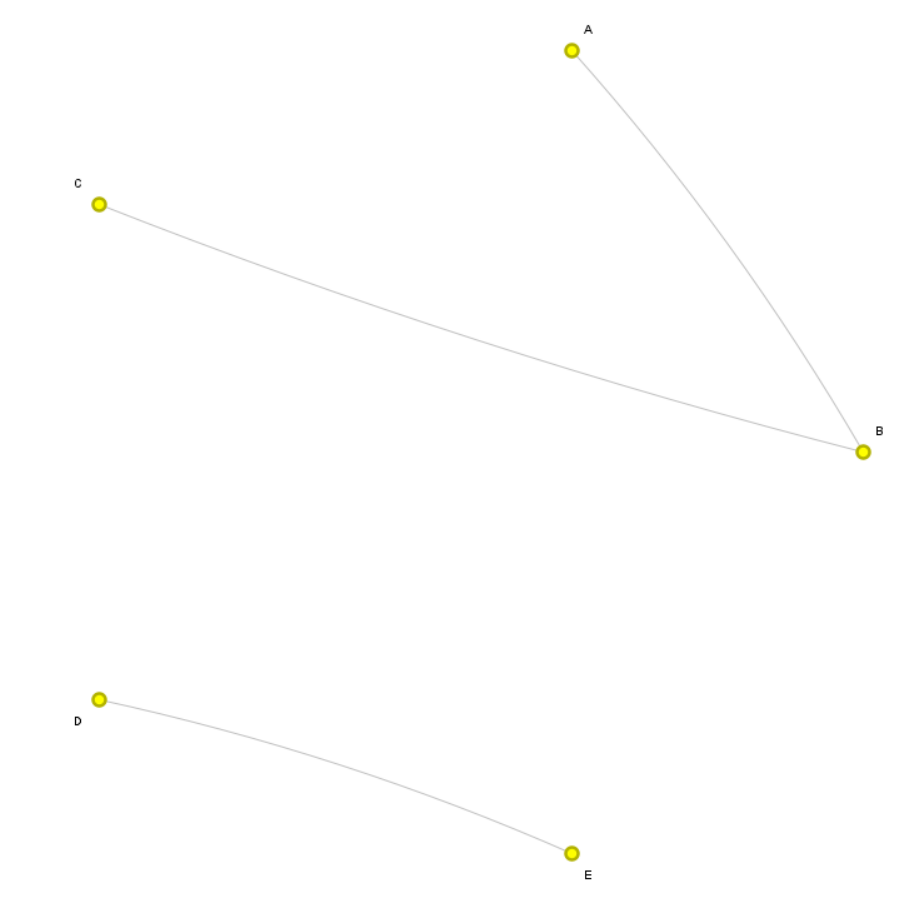
So in above example A is connected with C because B is connected to C and A has connection with B. My table is huge so any kind of recursive loop probably won’t work.
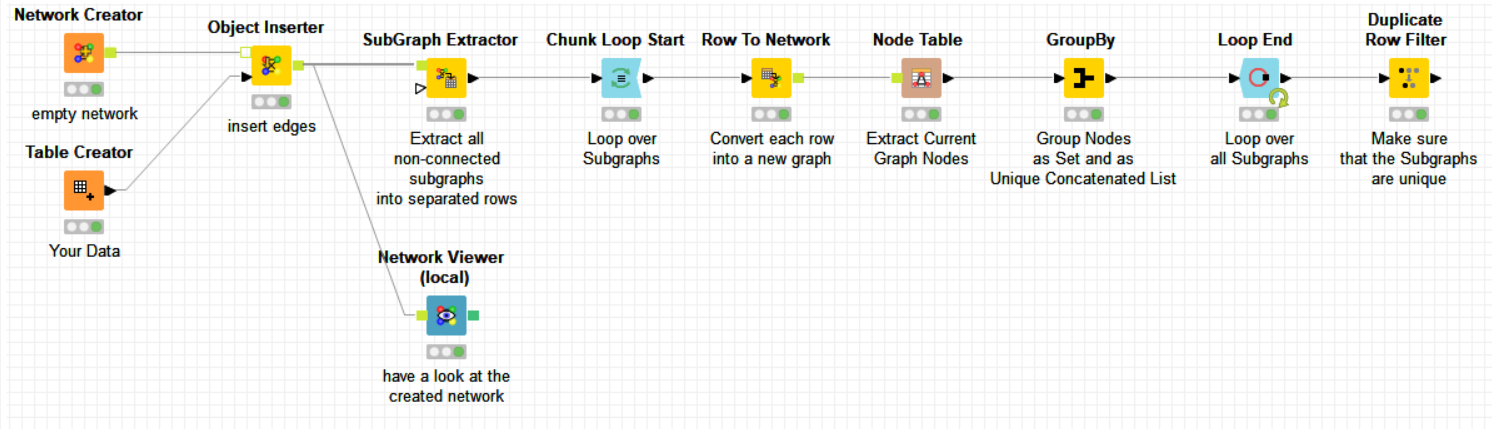
For making a network, you need two lists, a list of nodes and a list of edges. In your example, this would work nicely if e.g. 2 is the connection between A and B, but 2 never appear again. Is this assumption right?
it does the trick but I’ll have an input table with more than 1 million rows and SubGraph Extractor node will probably produce around 5 million rows so going with row by row loop will last too long…
It is not a row-by-row loop but a subgraph-by-subgraph loop ! it makes all the difference !
How many subgraphs do you estimate to have in your whole relational graph ?
Please try it and let me know if still it is too slow. By experience, there might be relational graph “tricks” which could be used depending on the nature of your data
ok. But one subgraph is one row so it’s still row by row
Anyways I tried with around 60% of my data and didn’t work. KNIME got stuck on SubGraph Extractor node. I would say there should be around million subgraphs with all data included.
The workflow I provided can be adapted to the specificity of your data and most probably be highly optimized but before submitting a new optimized version, could you please do the following calculation and tell me what is the result ?
Could you please do a -Groupby- by the “Group” column of your data and aggregate by count the column “Value” ? How many rows in the new table have a count(Value) higher than 1 ? This should roughly give an estimate of how many individual subgraphs are in your your whole graph.
@ipazin@aworker
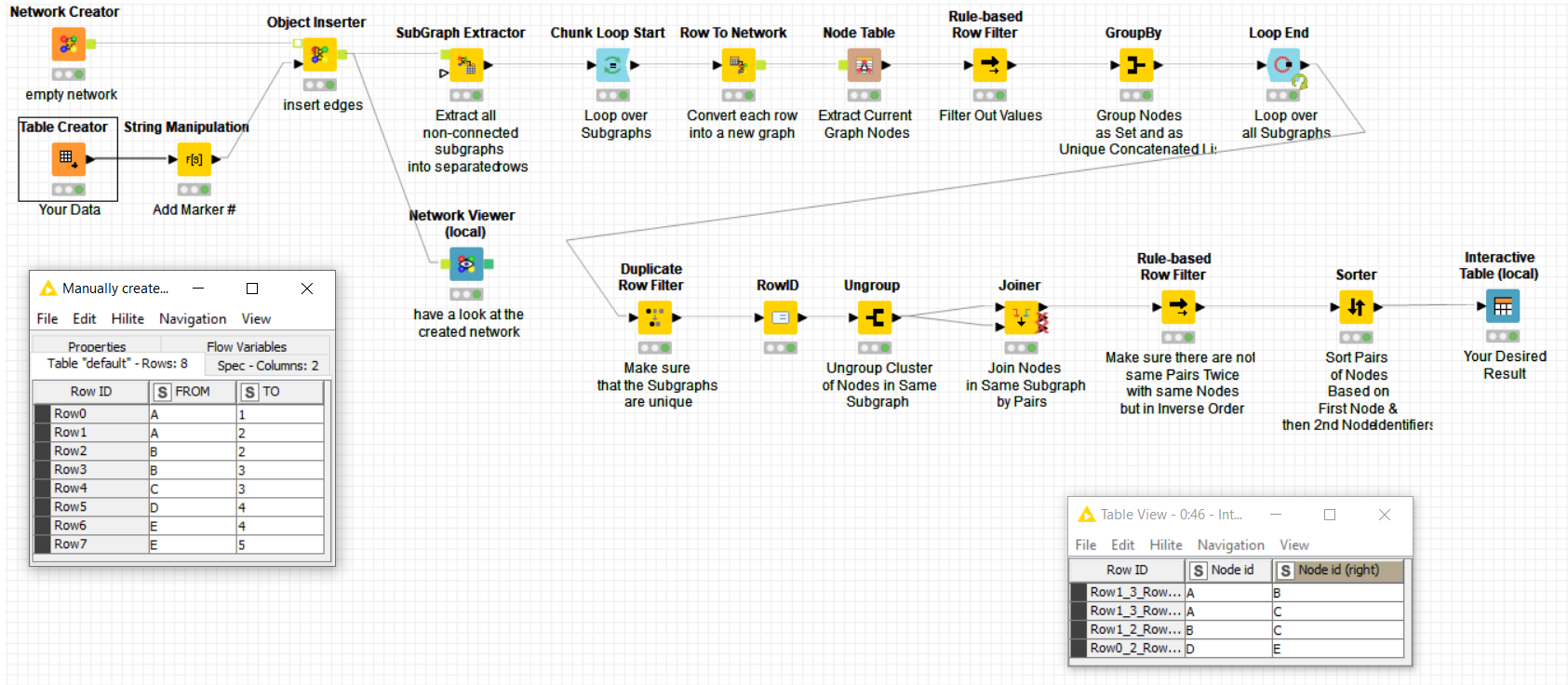
Maybe it’s possible to reduce the number of subgroups before they enter the loop. I’ve tried this workflow (I don’t know if and how it could work with very large datasets)
tnx for your ideas and effort but seems a bit complicated. There are some specialized tools for this which I’m gonna try out. Will let you know the result.
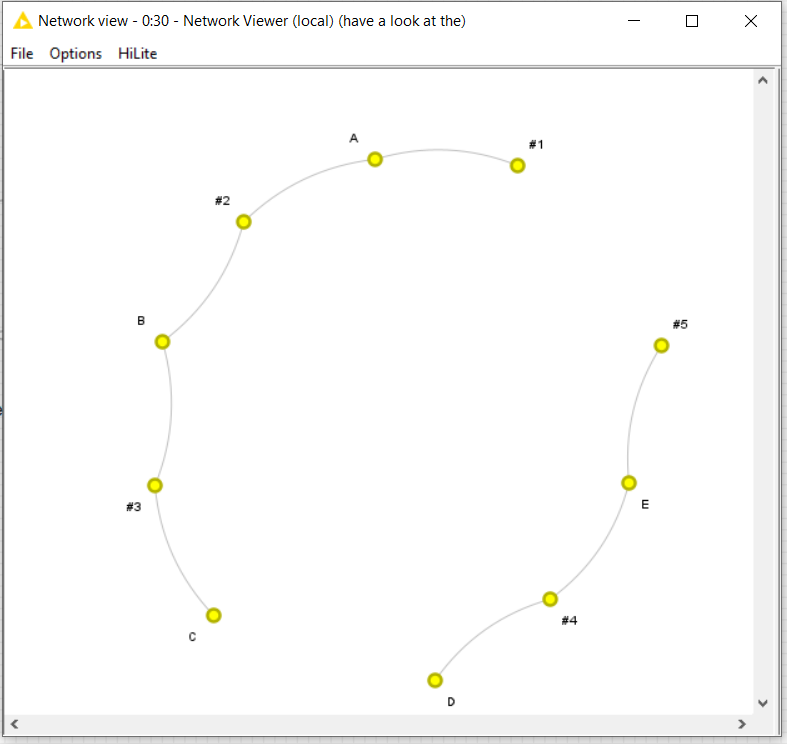
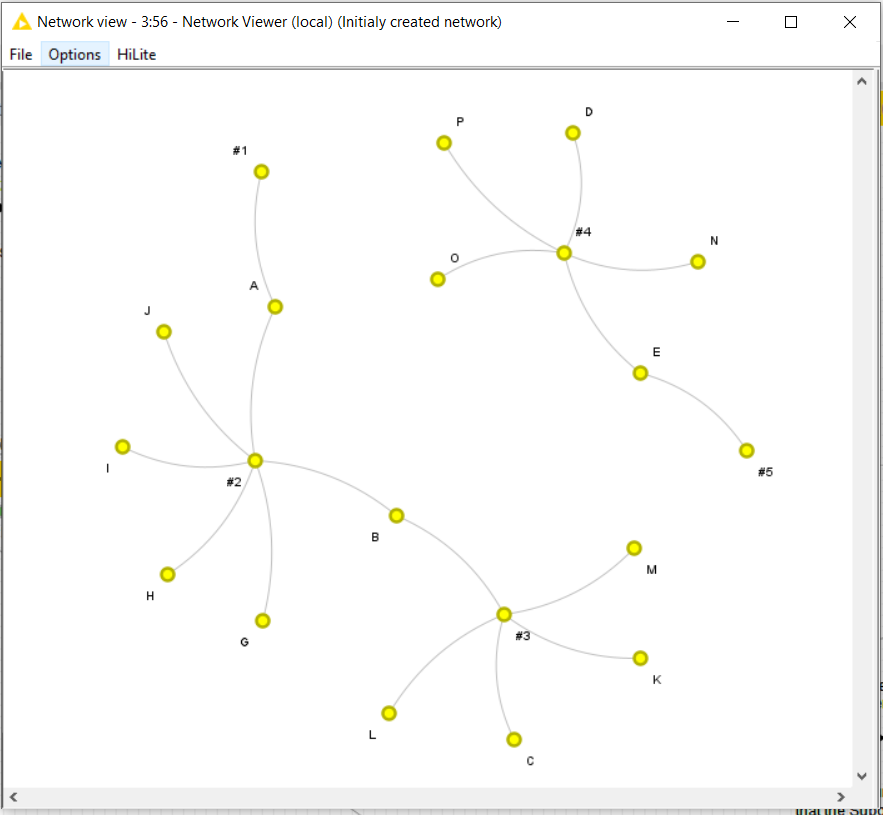
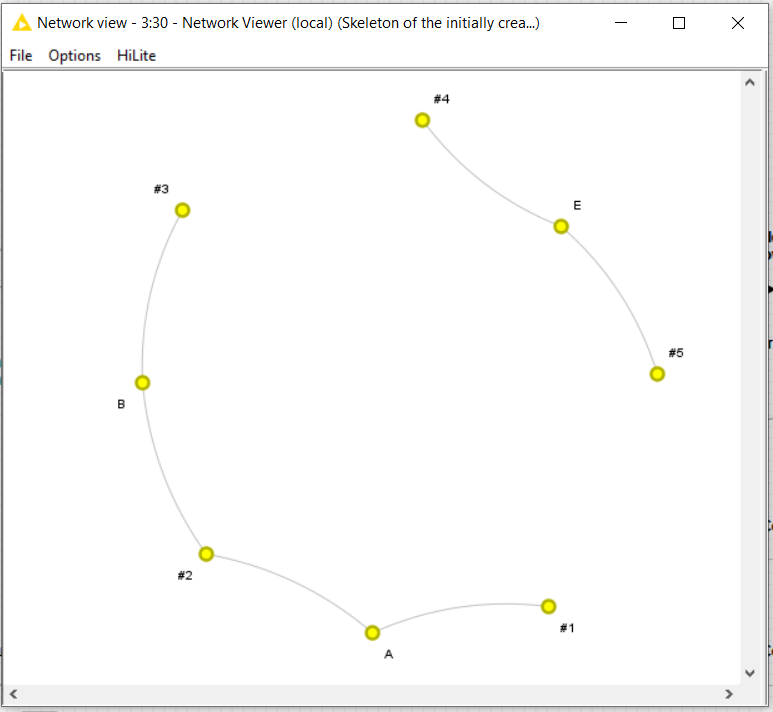
I have studied your network structure from the example data you posted and as I said in my previous post, it facilitates the search of subgraphs without having to explore the whole graph with the -subgraph extractor- node.
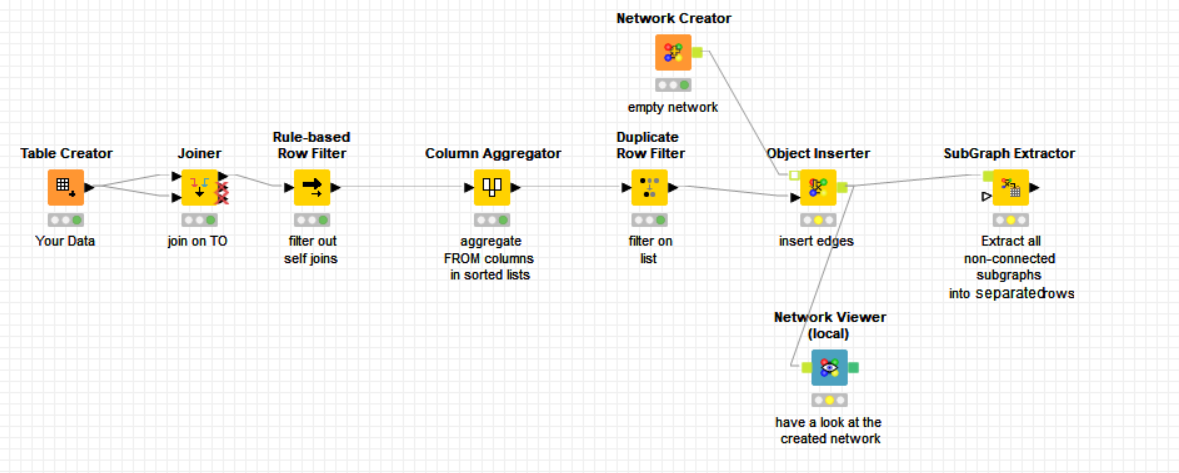
The trick here is to calculate the subgraphs based on the “skeleton” of your relational network rather than on the whole network. Given the underlying nature of your relational graph, calculating the skeleton is easy and hence it simplifies all the rest.
For instance, this is an example of full relational graph using a similar scheme to the one of your Data Table:
tnx for taking your time to help me and sry for late response.
I tried it out and although it seems to be working better (faster) it still can’t handle data I’m working with. I tried (colleague actually) specialized network tool and also couldn’t get it so I’ll drop this for now and come back later to it as it’s not that critical for my work but it is interesting problem
Thanks for your feedback. Maybe other tricks are certainly applicable to your data to eventually attain a good solution. If this problem gets crucial for you at a later time, please get in touch to discuss other alternatives that I have already implemented for my own work. Millions of rows should not necessarily be an issue depending on the nature of your data and problem. I will be more than happy to help.