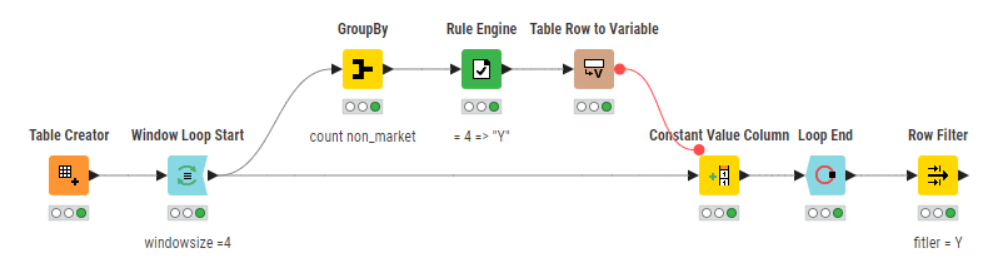
Greetings all, help me with this please. I need to keep only the rows where Column 2 says “marked” at least 4 times in a row. Each group needs to be processed separately, so rows from different groups are not counted together.
Column 1
Column 2
Column 3
Group 0
marked
1.0
Group 1
marked
2.0
Group 1
marked
3.0
Group 1
non-marked
4.0
Group 1
marked
5.0
Group 1
non-marked
6.0
Group 1
marked
7.0
Group 1
non-marked
8.0
Group 1
non-marked
9.0
Group 2
non-marked
10.0
Group 2
marked
11.0
Group 2
non-marked
12.0
Group 2
marked
13.0
Group 2
non-marked
14.0
Group 2
non-marked
15.0
Group 2
non-marked
16.0
Group 2
marked
17.0
Group 2
non-marked
18.0
Group 2
marked
19.0
Group 2
non-marked
20.0
Group 2
marked
21.0
Group 2
marked
22.0
Group 2
marked
23.0
Group 2
marked
24.0
Group 2
non-marked
25.0
I am expecting my output to be like this:
Column 1
Column 3
Group 2
21.0
Group 2
22.0
Group 2
23.0
Group 2
24.0
I am hoping to get a solution that does not involve looping, but I welcome all attempts regardless.
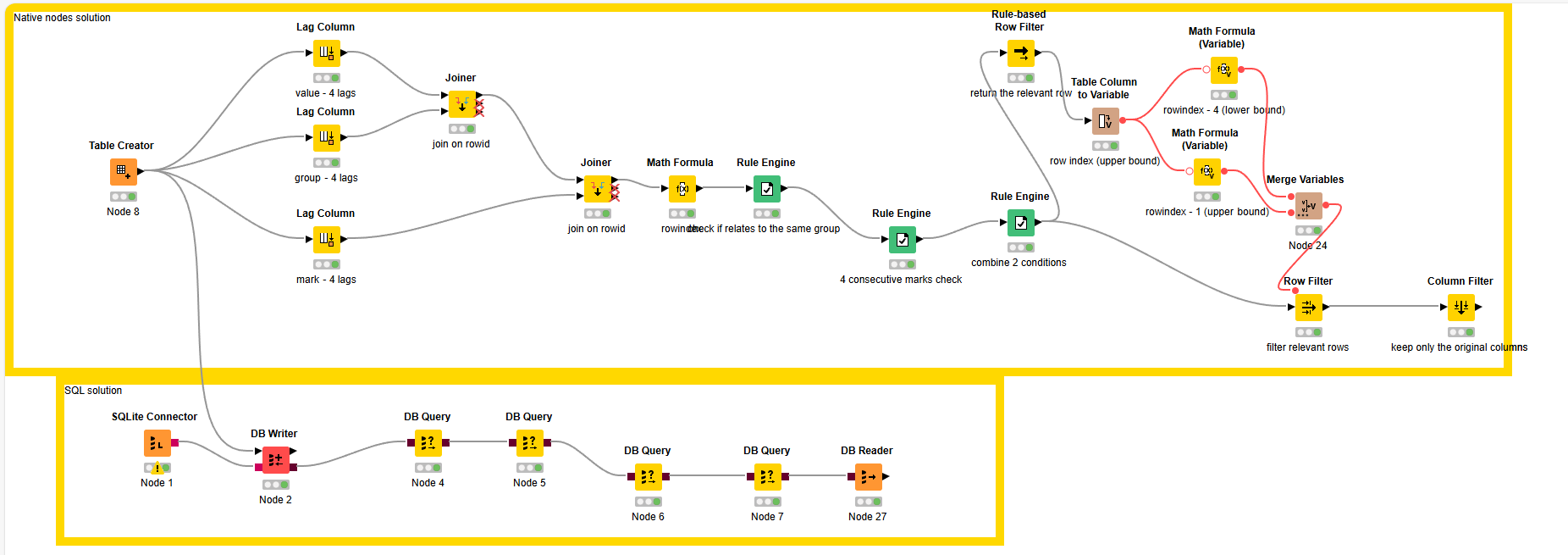
Instead of a Window Loop it uses the Lag Column node to create some dummy variables to help identifying a sequence of 4 rows “marked”. The relevant rows (id-s) are stored in a list. After unlisting the id-s, the Reference Row Filter fiilters the rows with a sequence of 4x “marked”.
It is fairly straightforward to implement in SQL with no loops required ( e.g. using SQLite node + in memory connection). This will involve using the lead function for all 3 columns, then checking if the values have 4 consecutive marks + if they belong to the same group. Then you can return the index of the next 4 (or more) rows meeting those conditions. Happy to send that over later tomorrow when I have my laptop with me if you want a truly no code solution with no loops - it may work with the lag nodes but all 3 columns would need to be lagged/ led and cross checked.
Thanks @Add94 , I won’t be able to verify a SQL-based solution, but feel free to share one if you have it available later, might be useful for those who understand SQL.
@badger101 - No worries! I managed to implement the SQL-based solution using KNIME-native nodes too. Please see the workflow containing both (SQL-based is a lot cleaner in my view!)
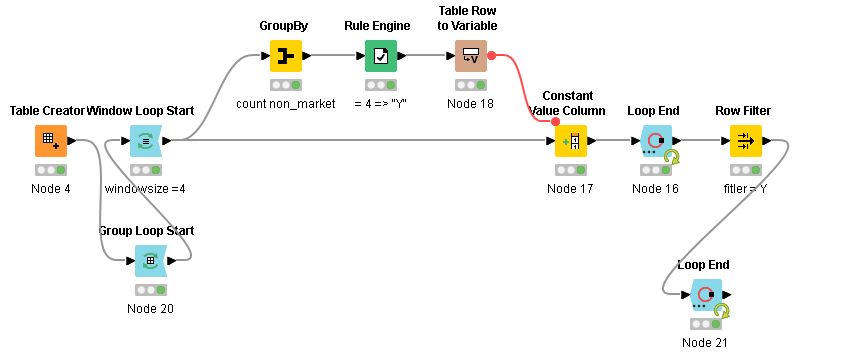
Thanks @Add94 , I have subjected your no-SQL route to the same tests as I did to @HansS solution (which passed it). Although yours worked for the dataset provided, it currently does not work when
a group contains two subgroups of consecutive rows that fit the rule. For example, if Group X has this sequence: marked-marked-marked-marked-nonmarked-nonmarked-marked-marked-marked-marked, then the workflow should be able to produce two results for that group.
the dataset has more than one group that contains consecutive rows that fit the criteria. For example, if you alter the dataset provided such that the first 4 rows of Group 1 to be marked-marked-marked-marked and leave the rest of the dataset intact, then the workflow should produce two results, one for Group 1 and another for Group 2.
I really appreciate the effort though @Add94 – thanks so much!
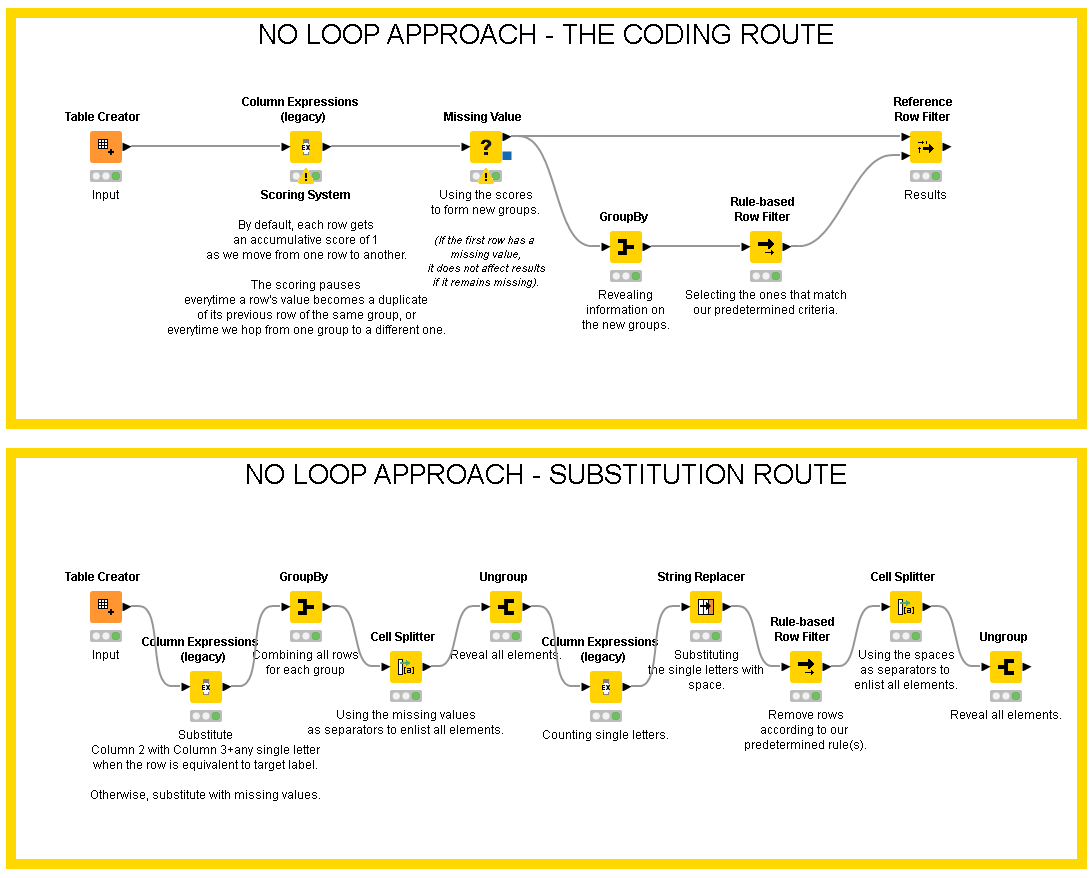
I have spent some time yesterday to work on my approach on this which passes the tests, just like @HansS solution passed them; the only difference is that I have managed to avoid loopings altogether.
If anyone reading this from the future & is looking for alternatives, here it is
Ah thanks a lot for letting me know! I suspected there may be additional cavaets / special considerations that otherwise would be hard to infer based on the sample data alone! Great to know you finally found the “ultimate” solution after iterating over the community provided workflows!