Hi All,
I know this topic has been raised here clustering with restrictions previously but I just haven’t found the solution for this yet.
As we know, when we applied K-Means to datasets, we always get the cluster with same size, but this also means we didn’t get the numbers per cluster we desired. For instance, the number of desired clusters is >=20, but we get some clusters with number <10 due to distance or size.
Here is the sample data that I have resulted from k-means node in the first cluster, in which after the first clustering, I will further cluster each of the cluster. The point is, problem i faced with this data even though the k-means has done the work is that I cannot use it since the number per cluster has huge range.
Is there any ways I can put constraints to k-means so that it would not exceed given threshold currently in KNIME? is there any example workflow I can learn from since I am not that familiar with coding?
Hi @Martyna
I’m still not able to solve the problem above. What I have done currently is that I’m planning to put constraint on distance & time variable since it’s related to TSP (Travelling Salesman Problem). However, I’m not able to find any solution that could put 2 constraint in KNIME.
I don’t find any options in our clustering nodes which could help to solve your issue (fixed number of data points per cluster).
What I could imagine is if you use the hierarchical clustering method, you could try to combine close results of the tree to get to the number of data points per cluster you want to, but it might be probably difficult to get to the exact number.
Do you know if there is an external Python or R library which has this functionality?
If so I would recommend using that one in a scripting node to solve your problem.
Could you please explain a bit more what you are planning to do with the constraints and how this is related to TSP?
Is this still related to the clustering or another topic?
Could you guide me for a moment on using hierarchical clustering method to get the close numbers in each cluster?
Yes, I know about the external Python to run this functionality, but I only got until the routing instead of the number for each cluster.
Sure, what I’m to solve currently in TSP is to leverage the raw data points, which consist of geotag ranging 5000-8000 points with the center point being the headquarter and trying to use algorithm in KNIME (I’m currently using k-means) to generate 2 level cluster:
1st level cluster: divide all data points to get 10 cluster, which is the working day (monday-friday)
2nd level cluster: divide the 1st level cluster to get the optimum number of seller that I need. from this 2nd level cluster combine with Python script will get me the routing. However, I’m still stuck in how to get the optimum number of seller and cluster for this 2nd level.
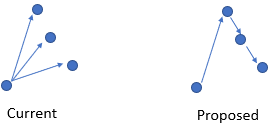
From the results, it’s showing not desirable results since all the k-means algorithm take into account distance from all points to the headquarter instead of distance from point to point and considering time visit in each points. Meaning if in the 2nd level cluster, sales A already reach threshold of distance 20 kilo/8 hours working time, it will move to sales B and so on.
something like this is what I’m trying to solve in the 2nd level cluster but to no avail.
Do you have any suggestion? Let me know if you need clarification.
I think it would help people if you’d rather explain your problem in more detail, i.e., what you want to solve than how you currently trying to solve it. Maybe someone did something similar to that and can help you out.
Could you in addition please clarify what exactly your data look like. What are the constraints on your problem, e.g., ppl can work only 8h a day or the HQ’s have to be computed etc…
I am also confused. I do not understand the need of a second K-Means clustering to try and achieve a TSP problem. Perhaps my educational background is different, but you need an optimization node (with certain constraints like @Mark_Ortmann mentioned), and not a clustering node, to achieve an order in which the traveling salesman “travels” to each cluster.