Hello,
I currently have a process in an Access database that uses a VBA loop to transpose data from a 3 column table into a table with 60 columns. The data from 20 rows is consolidated into 1 row.
The data starts off in the 3 column table like this
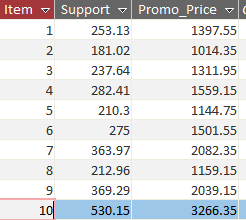
The transposed data results looks like this. Each of the 3 columns is not necessarily a straight transposition, but rather i have consolidated multiple rows into a single row. You can see in the image here, that the first row’s data for item # 1 is in columns 1-3, then item # 2 is in 3-6, etc.
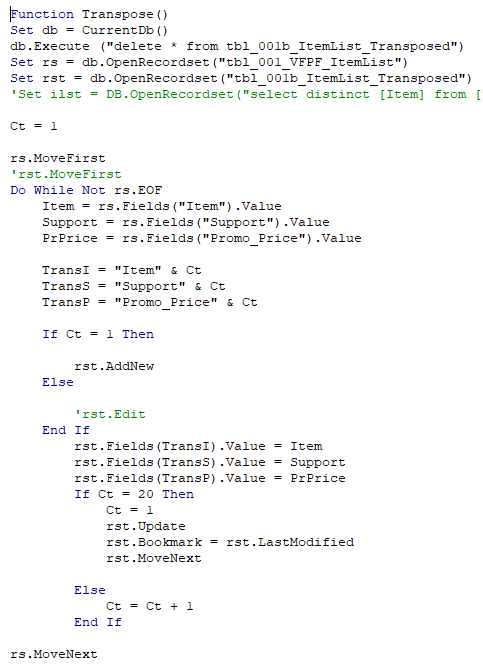
The code to do this is here. It basically loops through each record and manually builds the transposed table. This may seem like it would be slow, but it is actually lightning fast.
The purpose of this is to reduce the amount of records that Access needs to upload to a Teradata server. This table can be as many as 10,000 rows and Access is slow. By transposing in this way I can reduce the row count of my upload table 20 times over and increase the upload speed dramatically.
Once my table is uploaded to Teradata, i run a union query to rebuild it to it’s normal form. Teradata is extremely fast, so this is no problem.
I have tried a few nodes such as Transpose and Pivot, but they do not seem to function the same way my VBA loop does which allows me to consolidate multiple rows into a single row while limiting the columns. Transpose node will transpose them all, but it results is millions of columns which cannot be uploaded.
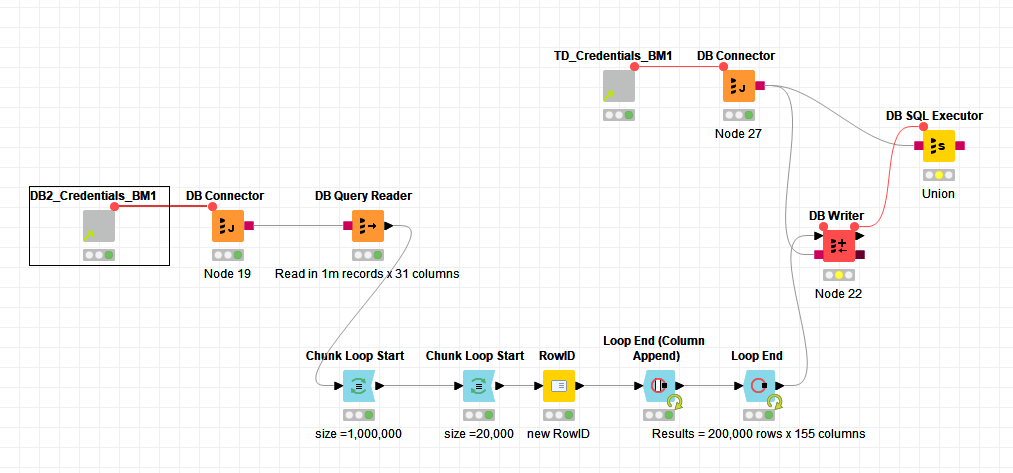
The reason i need this is because, I run multiple ETL workflows moving data from a DB2 server into a Teradata database. These tables can be hundreds of millions of rows long and Knime takes about and hour to move just 10 million of them. I would like to transpose the data in similar fashion to my Access VBA loop from a table with 31 fields to one with 2,046 (Teradata columns are maxed at 2,048). This would give me a much shorter table to upload and i believe would significantly speed up my workflows for large tables.
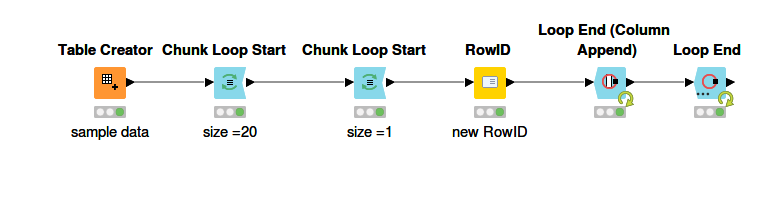
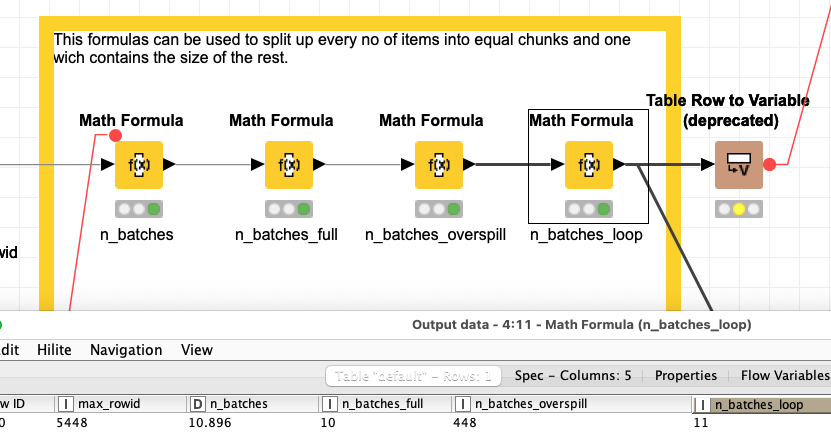
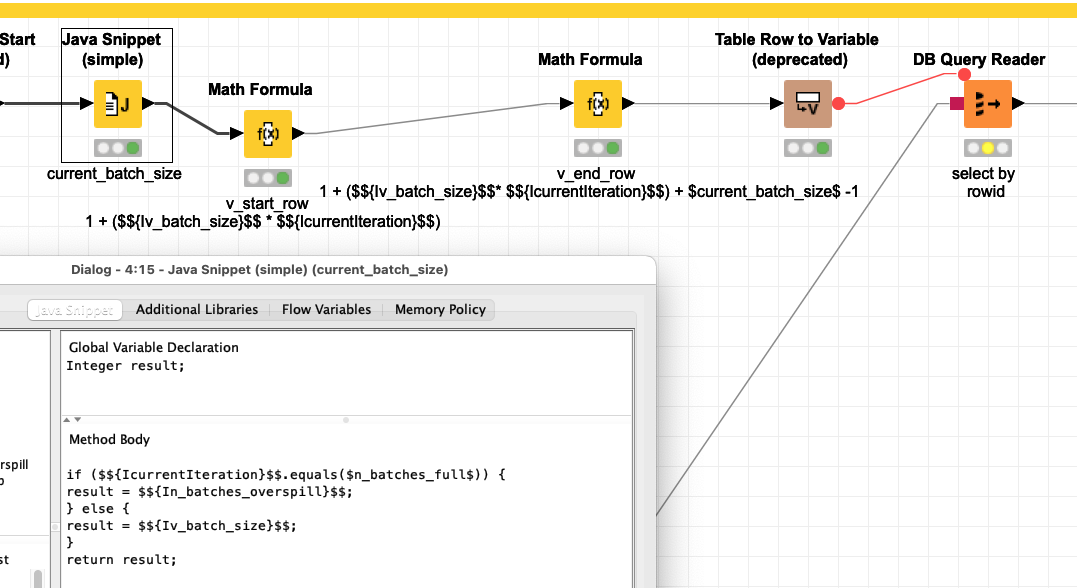
My current workflow is very simple.
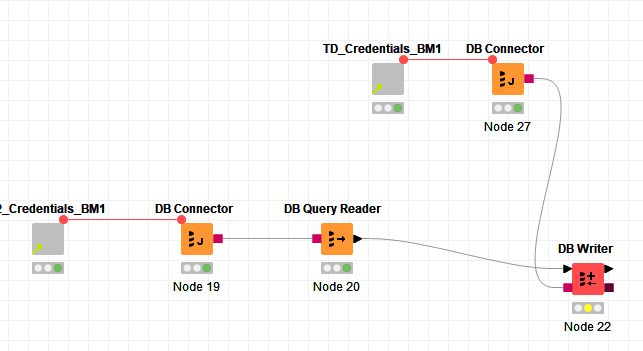
Are there any nodes that perform similarly to my Access loop? Or, is it possible to code something similar in a JS node? Or, is there something i am missing about uploading large amounts of data. My batch size on the DB writer is set at 100,000.