Hi everyone,
I would like to convert any character containing diacritics to an ASCII equivalent for columns, e.g.
ä => ae, å => aa.
I found that string manipulation has function named “removeDiacritic($$CURRENTCOLUMN$$)” but seems like it only removes special signs from string, e.g. Arvå => Arva, ä => a not converting.
Could you please advise me how I can make the correct conversion to ASCII equivalence.
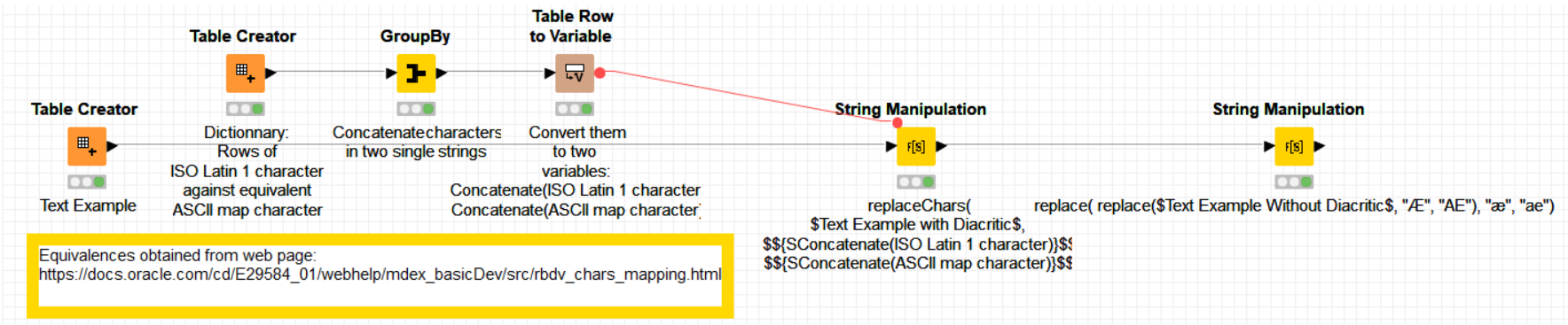
It’s probably going to be easiest to use the Cell Replacer node or the String Replacement (Dictionary) node. You’d create a lookup table and use that to replace the various characters as they are found.
Hi @elsamuel ,
Thanks for your suggestion. I am working on a table containing those characters and found that those characters are usually written like that.
Hi @aworker ,
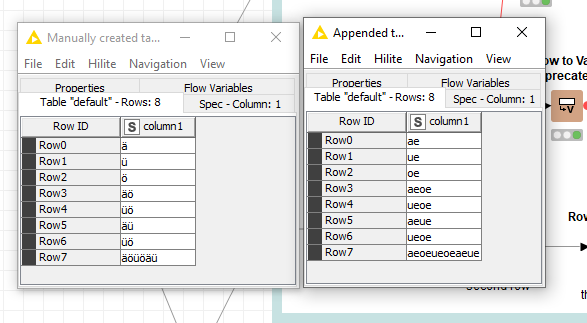
thank you for your help. But when I wanna replace Ä = AE, e.g. SCHÄFERS, then it gives the results SCHAFERS. I think it doesnt work with 2 letters (A and E), only the first letter (A) is used.
Indeed you are right. This is because the dictionary table does not achieve “1 character” to “several characters” conversion. If you need this type of conversion, i.e. Ä => AE, you will need to treat them separately. My first thought to get a solution would be to use in a first instance the propose solution for all the other conversions (those compatible with 1 char to 1 char). And once those are done, then to treat individually with a “replace( …)” operator those that need to be converted from 1 char to several chars in general.
The rough idea is here but if not clear enough, just tell me please and I’ll be happy to provide the modified workflow solution.
Should you have other special conversions from 1 char to several, you would need to add the conversions to the second string manipulator node, as shown here for “Æ” and “æ”:
replace( replace($Text Example Without Diacritic$, "Æ", "AE"), "æ", "ae")
Please be aware that for every special case you need to modify the initial dictionary table in the first -Table Creator- node, so that the diacritic in question is not achieved (or keep it as it is originally which is the same). For instance in the dictionary, I kept the same “Æ” and “æ”.
 not converting.
not converting.