In one dataset I have several hundred rows, each with a unique identifier, and several hundred columns with the column header identifying a specific potential quality within each row. The field of each row/column intersection contains a number also identifying the column quality when present within a specific row, or the “?” symbol if that row does not contain that particular column quality (graphic below; dataset #1 attached).
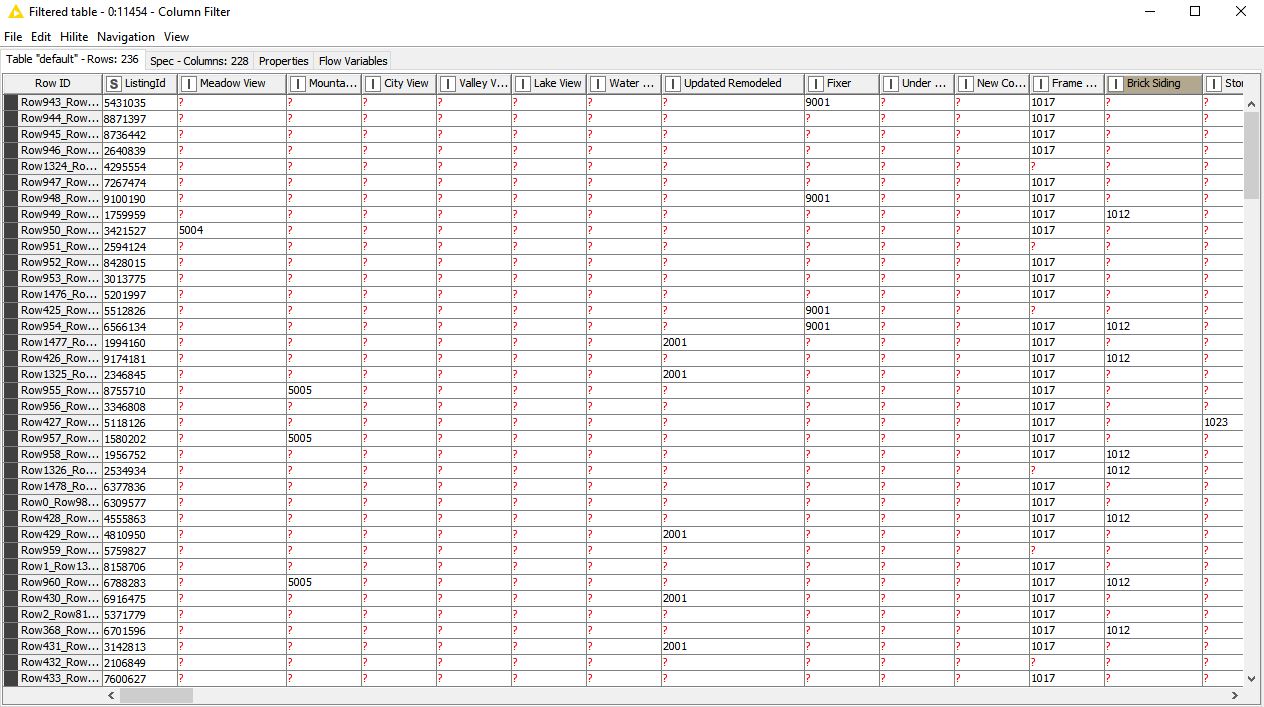
In a second dataset I have solved for the likely dollar value of each quality identified within the first dataset, obviously only when present at the row/column intersection. (graphic below; dataset #2 attached).
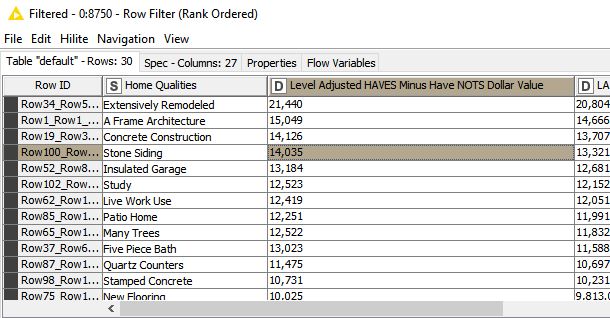
My goal is to trade out the field identifier when present from dataset #1 with the dollar value from dataset #2. For example: dataset #1 row identifier 5118126 has a quality identifier match of 1023 within the “stone siding” column. I would like to trade this 1023 for the derived dollar value from dataset #2 of $14,035.

The difficult part is needing to do this using thousands of datasets, each with completely different data–it’s fully customized every time. So creating a standard dictionary and cell replacer just will not work.
As always, any advice is very appreciated.
DataSet_1.xlsx (138.1 KB)
DataSet_2.xlsx (5.8 KB)
PS: I have DataSet #1 in a binary format instead of unique identifiers at the row/column field intersection if that helps in any way.

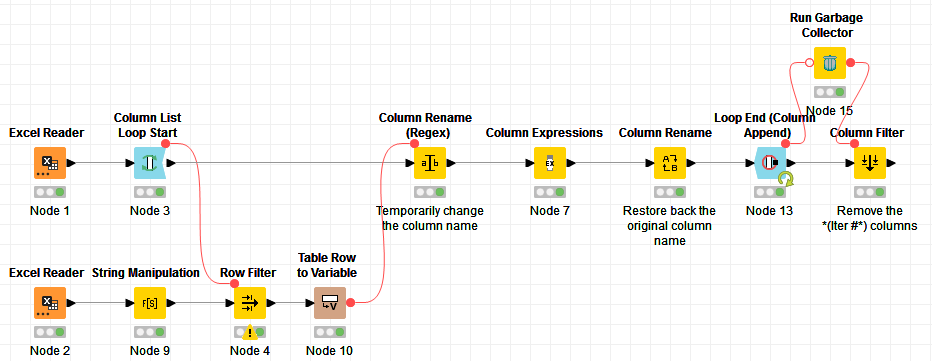
 . I will definitely see if i can get it fully implemented in my stuff.
. I will definitely see if i can get it fully implemented in my stuff.