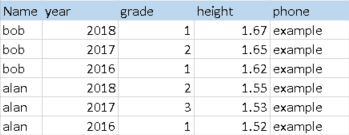
and I need a solution to transform it to:
where each data_year column is transformed into a single data column with an additional year column that identifies the year.
I am able to do this manually for each data group (e.g. grade, height, phone), but I have many data columns for many years, so I require a solution that doesn’t require manual configuration for each data group.
Any help is appreciated, even if its just pointing me in the direction of what to search up for it! I’ve been trying for a couple days with loops and even some Python code, and had no luck - but I’m not entirely sure what this process is called / what to search the internet for. Thanks!
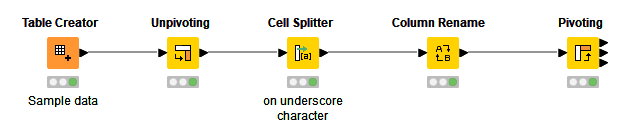
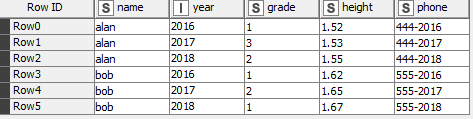
Try this workflow out and see what you think. It works on your sample data, but I think it should be fairly extensible to your larger dataset. The trick is making sure you understand how the configuration of the Unpivoting and Pivoting nodes work.
Hi @zm004433
The workflow that @ScottF shared is the right answer for an strict KNIME ‘no code’ question, all the principles are there. But based in the description of the problem as he mentioned; it might be fairly extensible for some reasons:
the data is presented in a single format (string) that clearly it is not the case in your tables. It requires prior convert into string data
for an extensive data set, you have to deal with format type backward transformations in the output for further analysis
Full develop in KNIME will require looping over the different data families …
As a Python tip for the university; deploying the same steps in a ‘Python Script’ node by family categories, may result in something like this: