I have a long list of pathways with the proteins in capital letters (below). I wonder if there is a workflow showing how to establish and use a dictionary to tag and extract (collect) the protein names from the surrounding text.
Pathways names:
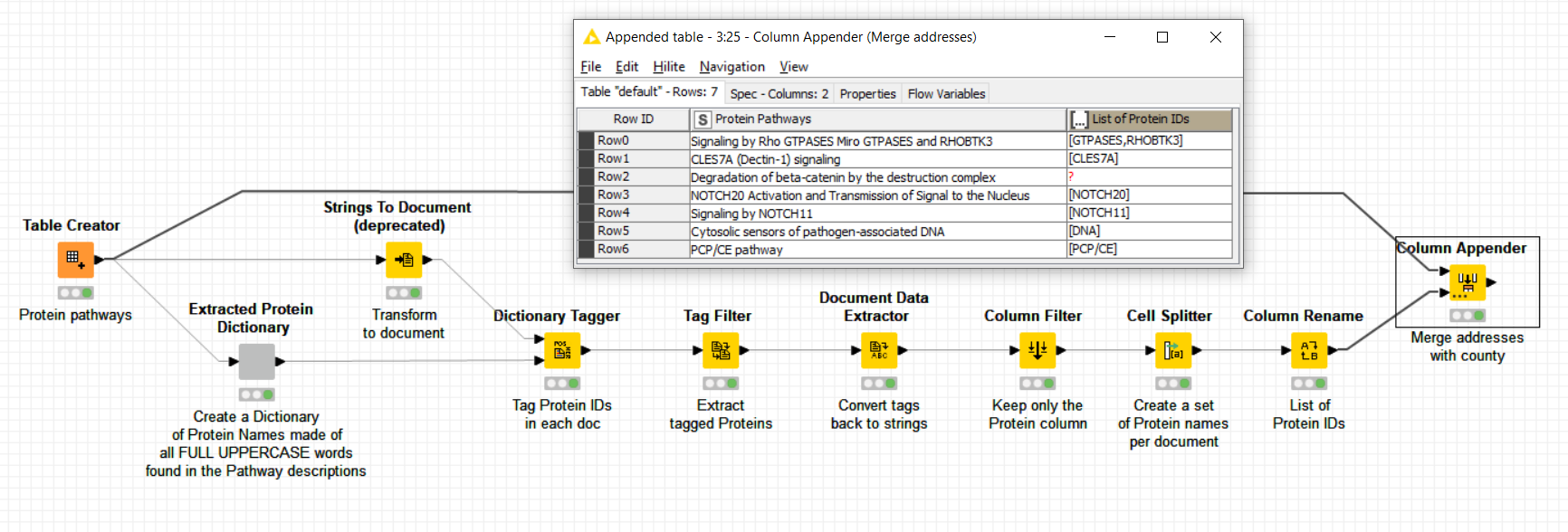
Signaling by Rho GTPases Miro GTPases and RHOBTK3
CLES7A (Dectin-1) signaling
Degradation of beta-catenin by the destruction complex
NOTCH20 Activation and Transmission of Signal to the Nucleus
Signaling by NOTCH11
Cytosolic sensors of pathogen-associated DNA
PCP/CE pathway
Interesting question. I just checked against the PDB but the protein names are not always referenced exactly as in your pathways Protein names.
Would you mind please to point us to a Protein dictionary of words to download as reference which contains the terms you want to match? We could quickly from there suggest solutions if nobody pops up with an off-the-shelf solution in the meanwhile.
Well, I actually modified the name of the proteins for confidentiality reasons. However, my question was more related to the fact that protein abbreviations are always in capital letters by contrast to other words in the sentences.
The dictionary I ment, is not yet in existence. My plan was to create it from the scratch to can sort (Collect) the words of my long list. I really have no idea how to use the Dictionary replacer node to get (Collect) the “proteins” I am tagging not to exclude them out of the rest of sentence.
Would a workflow that extracts from every pathway description the words in capital letters be a -preliminary- solution for you ? Would this be good enough to start ? Then you would just need to compare these terms against your dictionary.
I have put in place an example of workflow that I think fulfills your need. The workflow is commented so self-explained. Do not hesitate to get back in touch if you have questions about the workflow.
The way the workflow is built, the dictionary is created from the same example of Protein Pathways, but you could easily modify it to have a dictionary that is not made from the same source of Protein Pathways so that you could check against an independent second list of Protein Pathways. I imagine this may be one possible goal.
It did work very nicely. I guess I have only two questions to improve my learning process:
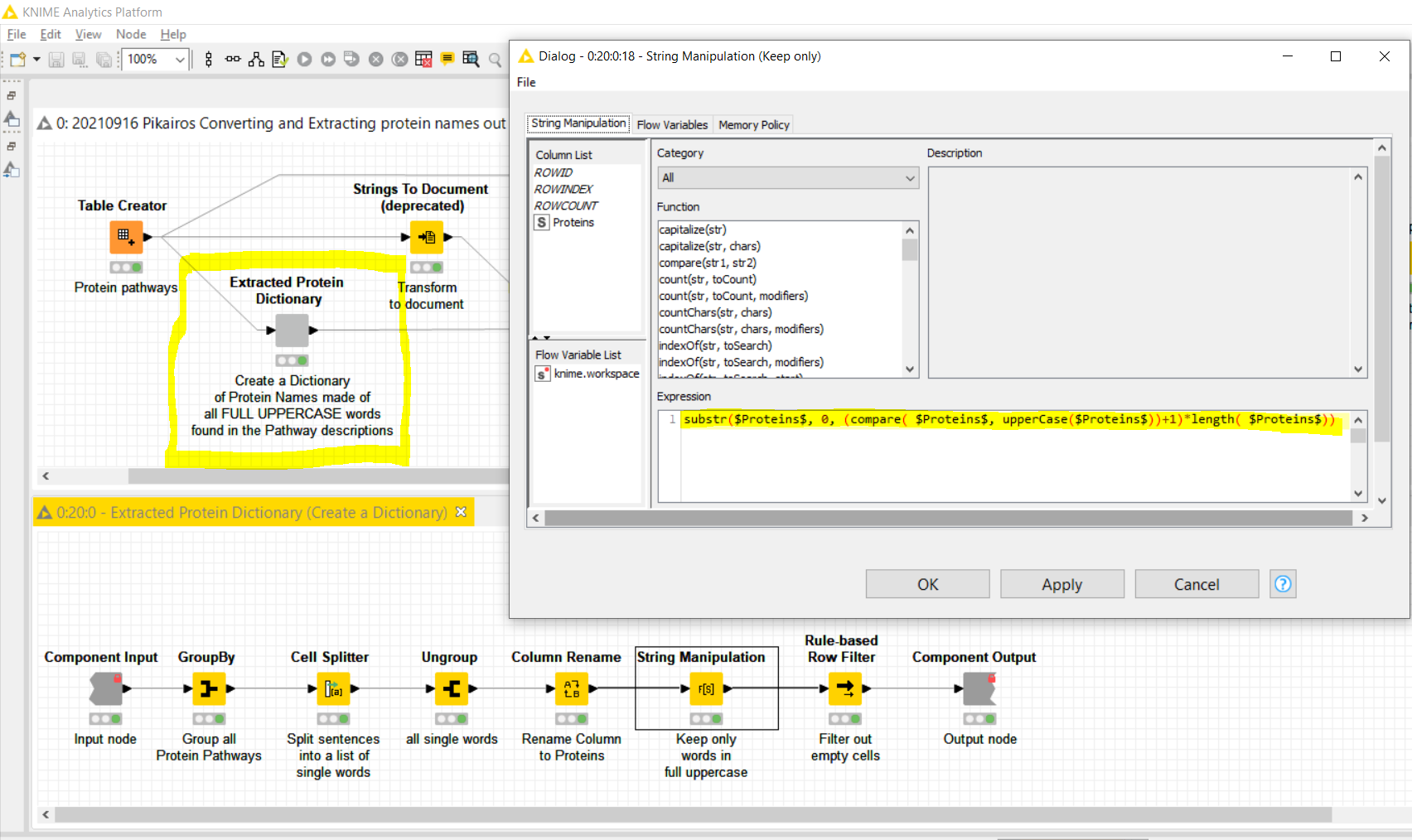
The string manipulation: It looks a bit complex to me. How should I understand: substr($Proteins$, 0, (compare( $Proteins$, upperCase($Proteins$))+1)*length( $Proteins$)). Especially the part of the upperCase. I will expect by the explanation in the node that it will return the number of letters in the words, not the word itself.
In the dictionary Tagger or the Tag filter, I observed that there is also the option of defining the Tag type. For example, there is the Pharma one that allows you to tag proteins. Would that work for me as well with real protein names like Foxp3, Foxo, Nfkb? or I would have to define the dictionary list manually nonetheless?
Glad to read it worked nicely and thanks a lot for your nice comments. Concerning the two questions:
The aim of this -String Manipulation- node operation is to check whether a retained word is the same one as its equivalent when converted into uppercase:
compare( $Proteins$, upperCase($Proteins$))
If this is the case, then it should be a Protein ID, as you specified in your messages. Any other word not being equal to itself when converted into uppercase, should not be a Protein ID.
The “compare()” function returns -1 if they are different and 0 if they are exactly the same. I add +1 to convert the -1 into 0 and the 0 into a 1 values. Then, I use here a trick to retain the word if it is a Protein ID or convert it into an empty string if it is not, by doing a substring() extraction based on the length of the word, multiplied by 1 or 0, depending on the compare()+1 result.
If the comparison is equal, then the substr() function returns the whole length of the original word. Otherwise, the substr() function returns a 0 length string because it is multiplied by 0, the result of compare() + 1. This is hence just a trick to simulate a kind of if-then-else function that doesn’t exist in the list of functions available in the -string manipulation- node. Other ways to solve this may be found as usual, for instance using several nodes or alternatively a regex expression.
I have never used the option “Tag Type = PHARMA” & “Tag Value = Protein”. May be other Forum members could shed some light about the use of different Tag Types.