Feeling a bit of an idiot with this question. Running on my local PC trying to run the GPT4All workflow
In the “Prepare GPT4 ALL Model Path” node it is expecting the path to the models folder.
my folder structure for knime local workspace is C:\users\myname\knime-workspace
for the GPT4All models it is C:\users\myname\gpt4all_models
the relative path I think should be …/…/gpt4all_models / given that each workflow has its own folder in the knime workspace
when executing i get the error message Execute failed: The specified folder …/…/gpt4all_models does not exist
I have tried also …/gpt4all_models with the same error so I am obviously not understanding the relative path requirements and I am sure it is not hard.
This is such a basic error if someone could point me at the obvious answer it would be appreciated
Thanks Markus for coming back so quickly, I have done as you suggested
As I am very much a beginner on AI plus not so technical, do you by any chance have some additional blog info to the medium write up, on the use of your workflow (a lot of work in that so congratulations ) that gives some ideas as to the different GPT4 models and how they can be used in your workflow for different scenarios such as Multi-document vector creations or “summaries the document” ? I assume for instance that you used the all-MiniLM model specifically for text documents/
@mgirdwood I have these two blogs about the use of local LLMs:
Question is what do you mean by that? The art currently is to find a good combination of prompts and matching of relevant documents (thru FAISS) while keeping the size in away that your system will understand them.
The above examples focus on local LLMs which are (currently) inferior compared to ChatGPT. There are also examples combining the OpenAI product with KNIME and loading vector stores there. I assume that the results might be much better but you will send your data to the cloud/a third party vendor.
Thanks again Markus, I am looking at the medium blog of course.
By multi document, I meant if there are a number of different documents that you want to parse to the same Vector Store but have them all accessible to the model at the same time.
I would only be looking at local LLM as where I might use them would not have internet access for the ChatGPT style mode
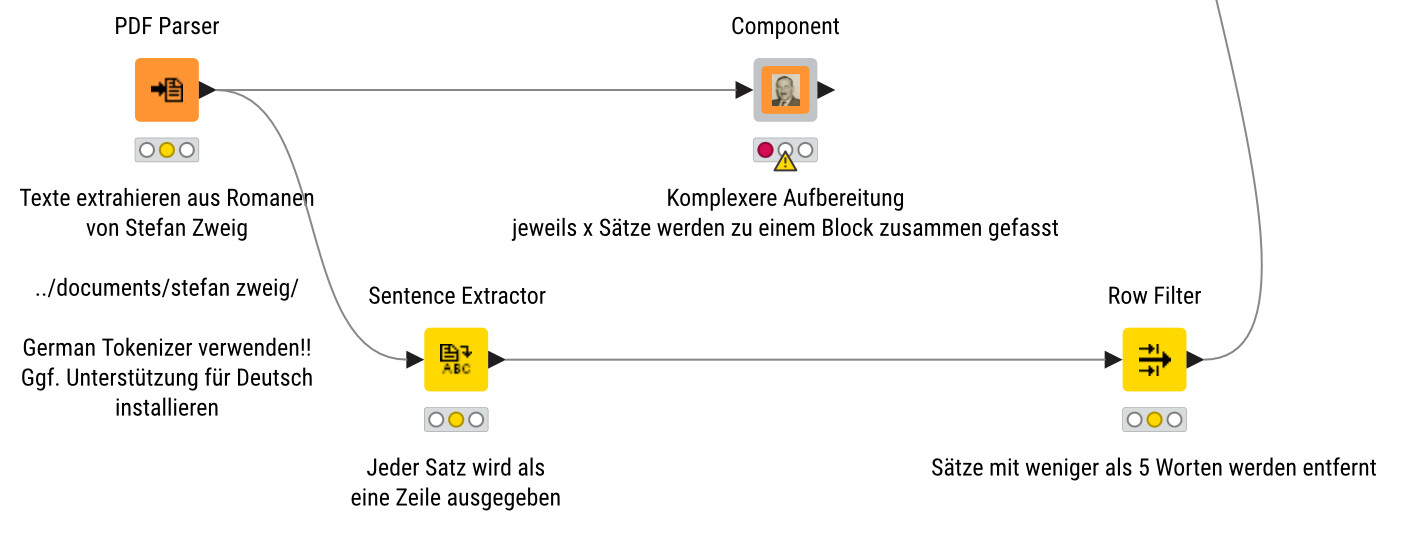
@mgirdwood I have this example where I load several PDFs from the author Stefan Zweig into a Vector store and make them accessible. You might have to experiment with the meta data of the documents and also with the ‘window’ you give the model.
There is a component that tries to do a more complex preparation of the data with giving blocks of text (since a novel might benefit from a few sentences of context). You might have to toy around with such concepts for your own data. A coffee machine manual it might be OK to only send few sentences at a time, for a novel a longer context might make sense.
Also you might have to experiment with the prompts and the LLMs. Different LLMs might ‘like’ other prompts, or you might try an approach where you let an LLM write the prompt and then send that to the model.