Hi there!
I’m new to the KNIME so please be patient
So, I’m running through the following problem:
I want to keep on my data only the highly correlated variables to the first column (my actual dependent variable). Is there any way to accomplish that?
For ex: My first column is the dependent variable (named: Y) and all the other ones are independent ones. I’m trying to establish a threshold of only the X variables correlated (>0,3) with the first one, and the rest filtered out of the data.
Hey @elsamuel, thanks for your attention, but I already tried that!
I want to keep only the correlation VALUES of the first column between all the other variables, not the matrix all the way (equivalent to the first ROW of the correlation MATRIX).
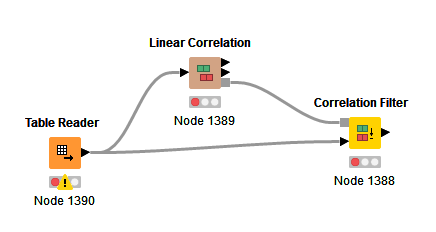
I created this workflow correlation.knwf (383.4 KB) , that makes it possible to filter columns that are “highly” correlated with your dependent variable Y.
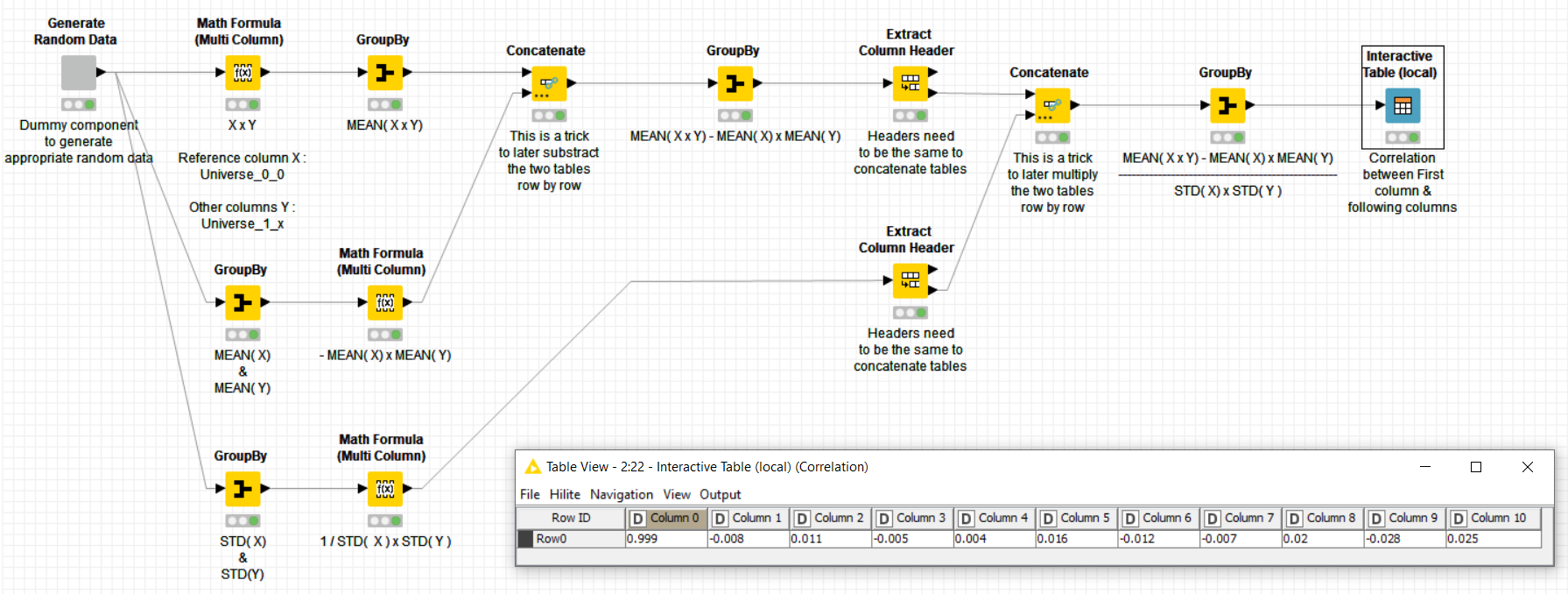
Complementary to previous solutions, please find below a solution that only calculates the correlation between the first column and all the columns (included itself). This may be of help when you have huge tables and using the “Linear Correlation” becomes untractable in terms of memory & cpu use :
It could be implemented with much less mathematic nodes but I have decomposed the correlation factor formula to make it more understandable (I let you to improve it ;-)) . Please go into the nodes to understand how it needs to be configured because for instance the “Group By” is aggregating by “Type Based Aggregation”, which is not the most usual way.