Hello dear KNIME community
I am trying to predict prices with KNIME.
The products have different properties, like weight, material, shape. And depending on the properties, the price changes.
I have listed some products with which property, which costs occur.
How can I make the connection in KNIME between the properties (strings) such as “material”, “manufacturing process 1” “coating” and the associated costs (numbers) such as “material costs”, “manufacturing costs”, “costs for coating”. At the end I would like to import only the properties and get the price automatically output.
Is this possible?
Hi @Antonia,
What you are looking for is a regression model that creates a mapping from a set of independent variables (or features) to a dependent variable (the target, in your case the price). There are many algorithms in KNIME for doing this and if you want to learn more, I can recommend the Machine Learning part of our self-paced L1-DS training. Good algorithms you can try are Simple Regression Tree Learner, Random Forest Learner (Regression), and Gradient Boosted Trees Learner (Regression).
One example that is similar to your use case can be found here on KNIME Hub. It learns to predict housing prices based on different features of the real estate. Make sure to do what they also do in this workflow: split your data into training and test data so that you can properly evaluate your model.
Kind regards,
Alexander
7 Likes
@Antonia Here’s a very simple example of creating a model and then deploying it for use with new data. Note that the new model reuses the test data from the original model. In a real case, you’d feed it your new data. Hope this helps. There’s a lot more that could be done to optimize and/or choose possibly better model(s). You might want to check out the AutoML component which " automatically" selects the best model for a given data set.
2 Likes
Hi @AlexanderFillbrunn
thank you for your help.
Just as in your example I had tried it, but unfortunately with little success.
I think my problem is that each cost block depends on a property (a string), and also on the weight of the product. an example: I have different coatings so I have a column with “coating” then comes a column with “cost of coating” and there is another column with “weight”. My costs for coating depend on the type of coating (column “coating”) so also on the weight. In total I have 5 cost blocks, which are composed of attributes and weight in my table.
I have not yet managed to display this in KNIME. For this reason I never get a high accuracy in the prediction.
Hi,
Maybe you can engineer some additional features from the ones you have, e.g. with rules or math formulas?
Kind regards
Alexander
1 Like
Are the weights you refer relative weights or absolute weights, i.e. lbs or kgs? You if can explain this and provide a sample data set, it would be easier to try ti help.
1 Like
Hi,
it is the absolute weight.
This is what a row in my Excel table looks like.
All costs depend on the absolute weight of the workpiece. But also from another variable.
I am already closer to a solution with the simple regression tree. But as soon as I split the data into training and test data, the accuracy is only 20%. If I use all data for prediction, the accuracy is 93%.
Is this due to the amount of data I have? Unfortunately, I don’t have more data that I can use to train the program.



Hi @Antonia
You didn’t tell us how much data you have. Besides this, a Decision Tree can overfit, that’s why one needs to split the data into training and testing to check the model performance. I would recommend to use instead a Random Forest with enough trees to avoid overfiting.
Coul you please share your workflow & data (if not confidential) here so that we can better help you ?
Best
Ael
1 Like
Hi
I have 77 rows with complete records.
I would be reluctant to post the exact numbers.
Below is my workflow and the evaluation of the numeric score when not using a partitioning node.
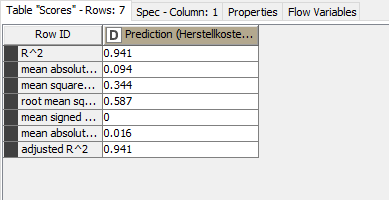
If I use a partitioning node then my workflow and numeric score looks like this:
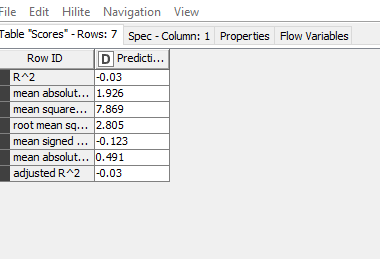
Hi @Antonia
No problem at all. With so few samples, I would rather use a -Linear Regression Learner- node which should not be prone to overfitting. What are the results returned by the numeric scorer if you do so ?
Best
Ael
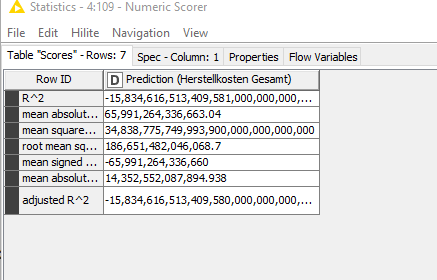
Hi @Antonia
The node setting is probably not correct, maybe there are several columns selected as target. Can you please post here a snapshot of the -Regression Learner- node configuration ?
Thanks
Ael
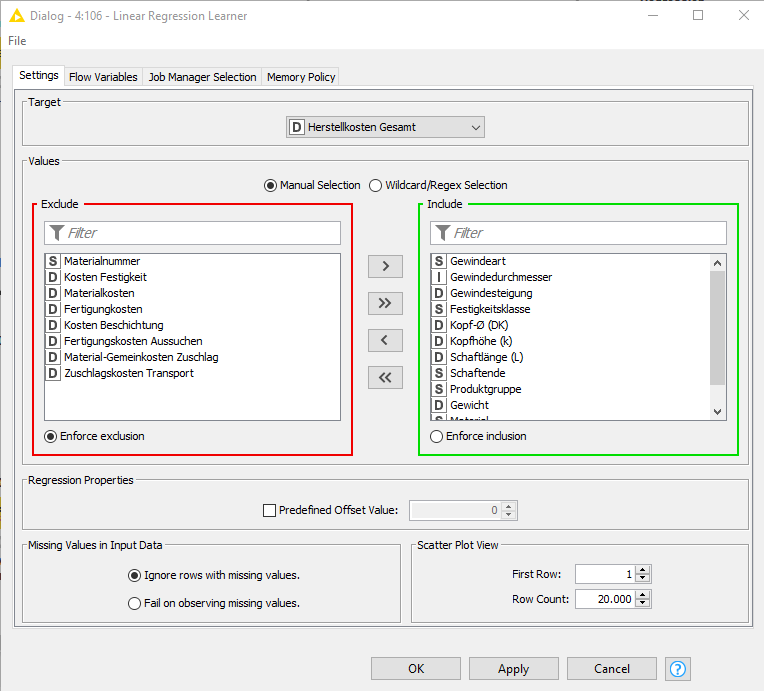
Hi @Antonia
I have not seen this behaviour before. I may be missing something but it is hard to know without having access to your workflow and data. Given that your dataset is very small, couldn’t you please anonymize it (i.e. remove column headers) and then share here your workflow with anonymized data ? Otherwise it is going to be hard to understand these results.
Thanks
Ael
1 Like