I am stuck with the analysis of my data. I am working with an 18 year time series of daily temperature measurements (4 measurements per day, at times 00, 06 12, 18 UTC). In the series I have several missing data.
Also, I have the time series (of the same variable and for the same period, with the same measurement times) from a nearby point. For this reason, I would like to make a correlation between them to see how similar they are, and to see if it is viable to use the second one to complete the missing data of the first one (which is my series of interest).
Is this logic correct? And if so, what kind of correlation should I do and how should I perform it?
By the way, I am using RStudio, but any conceptual contribution will help me to better understand my problem.
To impute values you could try and use the R package Amelia. I once wrote a warpper for KNIME. If you are familiar with R(Studio) you should be able to adapt and use it. I somewhere had a workflow for time series pecifically - I would have to see where that is.
welcome to the community! That sounds like an interesting analysis, and your logic sounds very correct to me. These are my suggestions for doing this with KNIME:
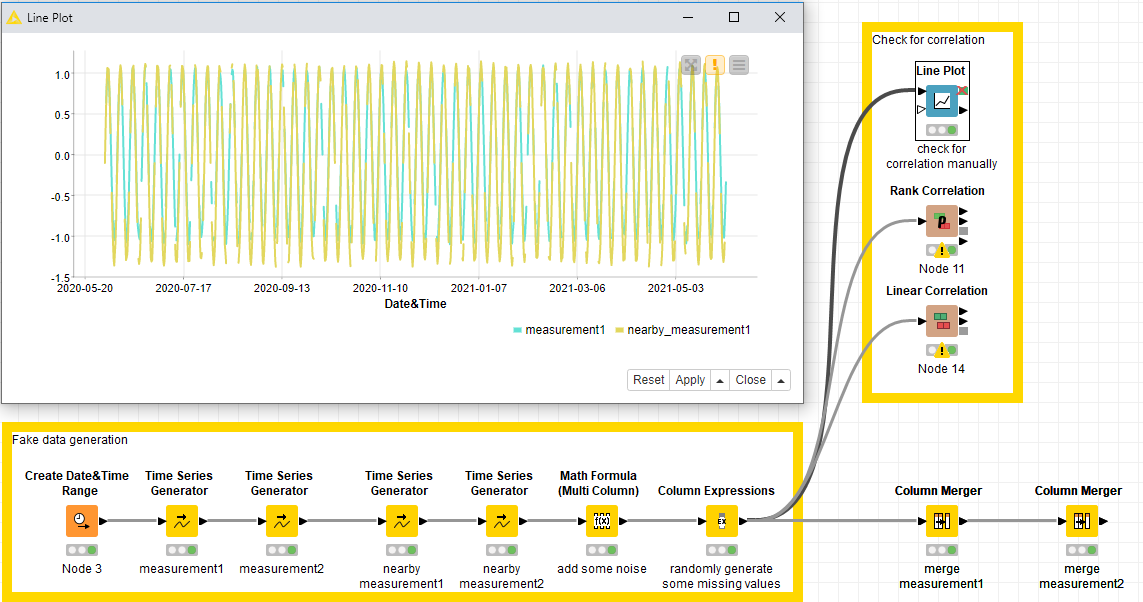
Off the top of my head, I would suggest a simple visual check for the start, by plotting each measurement pairs as a function of time, like so (assuming you have a column of the times and one for each measurement):
Any strong deviation would well be visible and it can tell you if it could make sense at all to replace the missing values with the measurement from the other location. Additionally, it can give an indication whether a simple linear interpolation via the “missing value” node would make sense.
If you need to put a number on it, I know of these two nodes:
A correlation value close to 1 indicates a strong correlation, and the lower the number, the weaker the correlation. Which method to choose exactly, though, I can’t really tell, since this depends on the details (how many missing values, …) and what your overall goal with the data would be. Same goes for choosing a threshold above which columns count as correlated.
Replacing the missing values by values from the other column then becomes a simple matter with the “Column Merger” node.
Additionally, the “Extract Missing Value Cause” node can give details on which rows have missing values (e.g. to identify the case that both columns are missing)
For completeness, here is the (dummy-) WF I used to play around:
Let me know if that helped and happy NKIMEing!
Best, Lukas
Hi Lukas!
Sorry for de delay response. Thank you very much for your aport! It’s really helpful. I am right now on the first step, plotting each measurment for a visual check, and they are quite similar. I also make a linear correlation and the value was very high, 0.977, so I think i wont have problem to complete de NAs with the other station. I’m trying to see wich is the best way to do that, since i’m working with R Studio, so nedd to study which package and function to use.
Thank you very much!
Hi!
Thank you very much! I’ve started reading about Amelia package, trying to understand how to use it with my data in R. I’ve been using it for a while now but still find it difficult at times.
It’s realy helpful your aport, thanks for that!