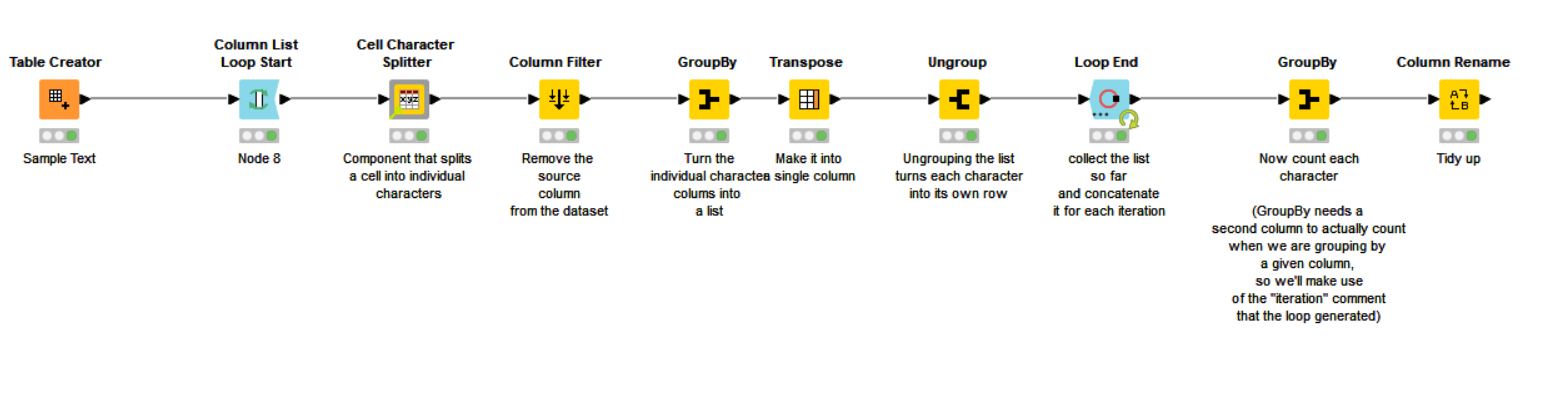
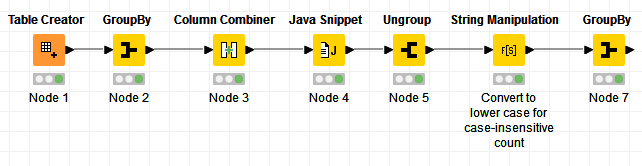
One of the problems you have is breaking down the strings into individual characters so that you can count them. Fortunately I have just such a component on the hub.
Looping through all of the columns, and putting that component inside the loop allows us to turn the set of individual characters within the column into a single column with a row for every individual character found.
At the end of the loop, you have a single column that is a concatenated list of all characters found across all the columns/rows.
This list can then be grouped to provide the count you need.
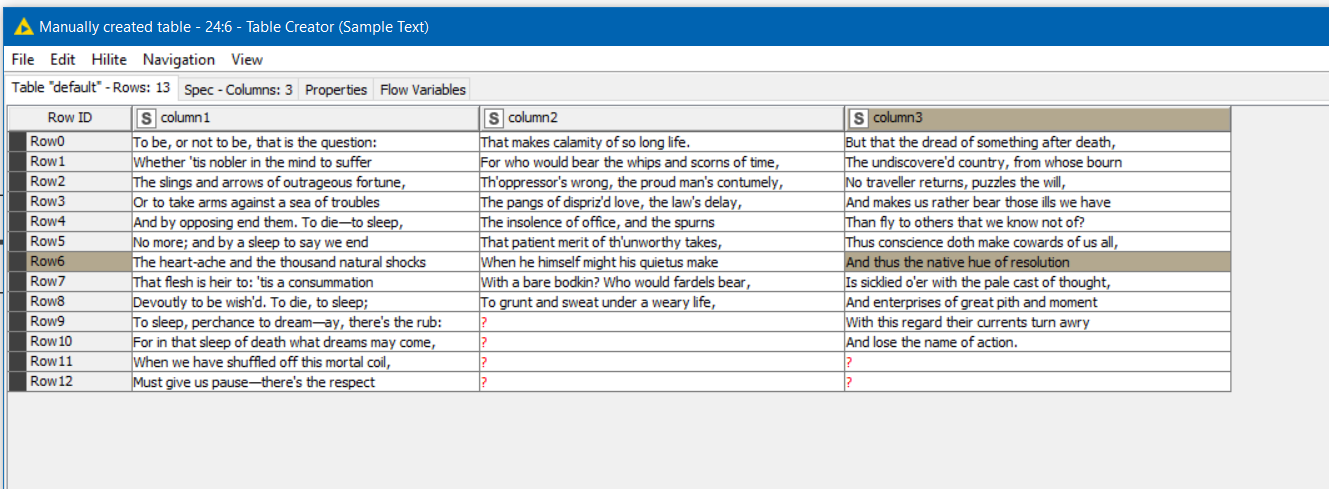
It will be interesting to see how well this performs across your thousands of rows but hopefully it will be of assistance.
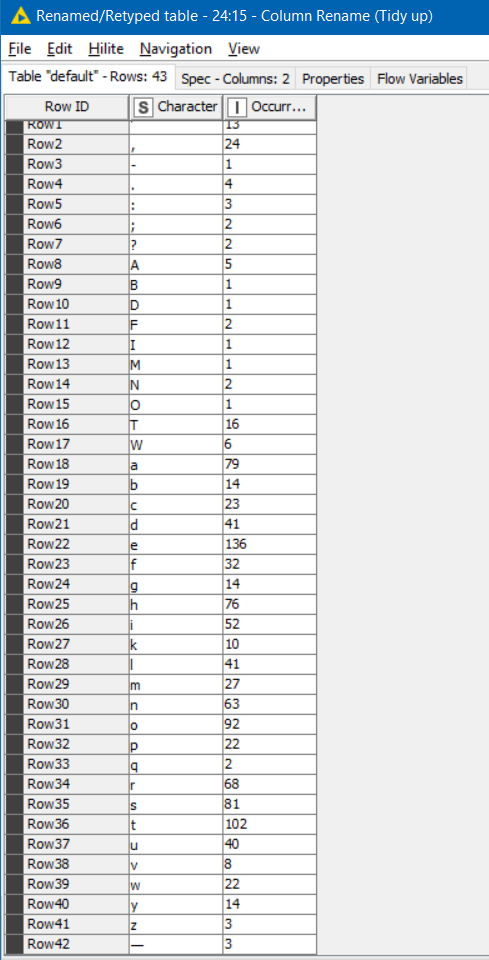
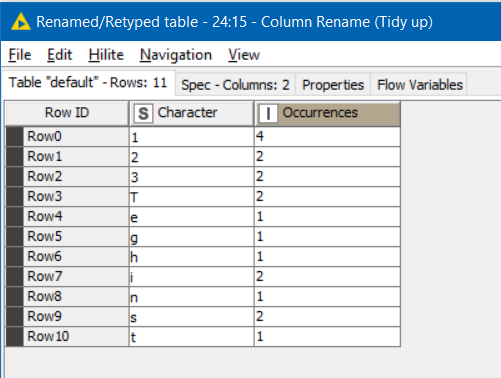
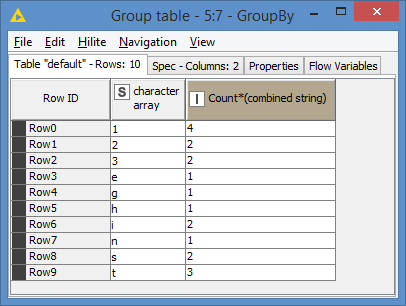
If I run it with your test data I get this, which differs slightly as mine counts T and t separately. If you wanted them to be counted the same, you could for example use String Manipulation in the loop to make the column all upper or lower case.
Hi @takbb , I think this could be done without a Loop, but at the cost of Memory, though the Loop could actually be using as much memory, since it needs to keep the results of each iteration while the Loop is running.
The idea would be to concatenate all the cells into 1 cell. This can be done with GroupBy + Column Combiner:
The GroupBy would concatenate all the rows into a single row, and the Column Combiner would concatenate all columns into 1 column.
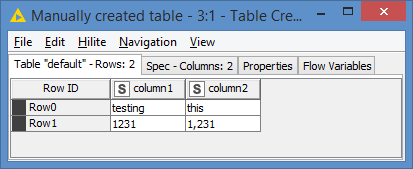
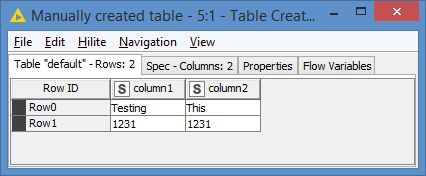
For example, if I have this input:
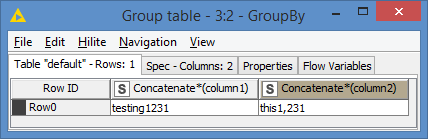
The GroupBy will concatenate all the rows into 1 like this:
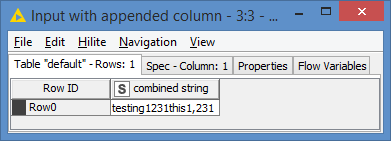
And then the Column Combiner will concatenate all the columns into 1, like this:
We can now split this string into array of characters and then do an Ungroup
EDIT: @RoyBatty296 I completed the whole workflow, and that’s how it looks like: