How can i retrieve the number of columns in a file.
I need to compare if in two files are the same number of columns.If not then the rest of the workflow should not run.
If the number of columns are the same, then i need to compare if the column names of the two files are the same.
To retrieve the number of columns you can use the “Extract Table Dimension” node.
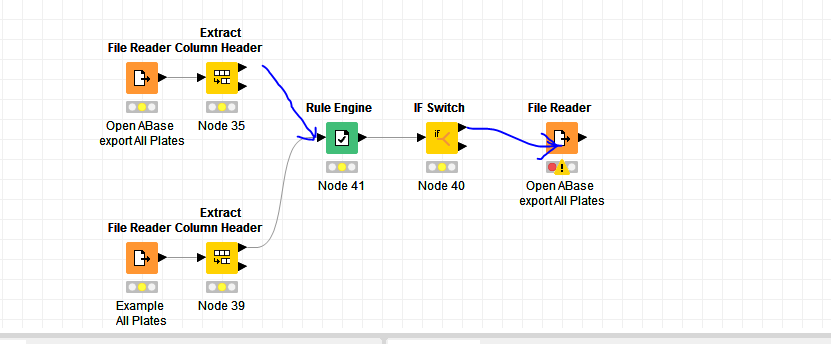
To compare the column headers I would first extract them with the “Extract Column Header” node and then compare them with “Rule Engine” node.
To control whether or not to execute the rest of the workflow you can use a “IF Switch” node.
Is this already helpful or do you need a small example workflow?
if the two header rows are the same then I don’t know how to connect the rule engine node and how to set this up to compare all the column headers.
Finally when the columnheaders are the same, then the file should be opened and further processed.
Would be great if you could create a small example
thanks for the workflow. I tested it and you get the difference in number of columns between the two tables. But I wonder how to continue. If the number of columns is the same then the whole table should be further processed.
attached is a workflow, which checks whether all column headers are equal. If both tables have the same column headers, then they have also the same number of columns.
Please let me know in case you have any questions!
thanks a lot for your help. Your workflow does the job. I only changed the connection from “Transpose to the IF-Switch” to “Table 2 to the IF-Switch”. Now I get the original table data and can continue handling these data.
I am new to KNIME and I truly appreciate your detailed responses and extremely helpful workflow!!
While I was working through your workflow, I noticed the console warnings on the “Row Filter” node creating an empty data table regardless of whether the tables created by the “Table Creator” nodes had equal columns or not…
I suspect this is because the table created by the “Joiner” node creates a row with a “Row ID” column similar to Column #_? and corresponding “Column Header” column, instead of missing values.
To resolve this issue, I set the “Row Filter” criteria to “Include rows by row ID” and used a regular expression to identify rows with missing values ([a-zA-Z]+\s+\d+[_]+[?]).
Just sharing this minor update since I find your workflow to be extremely helpful and wanted to clarify further for those who will reference in the future.
Please let me know if there are items I have misunderstood, and many thanks again!!