Hello guys, I have a csv file with too many rows, for example 275.000.
In one column appears repeatly the name of the source cyber attack country but the file is not grouped or it’s in disorder, for instance:
row1: …, France,…
row2:…, USA,…
row3:…, USA,…
row4:…,France,…
row5:…,Colombia,…
row6:…,USA,…
row7:…,Colombia,…
I need to find the number of ocurrences by Country, for instance in this case, in the standard output interface of knime I hope to list:
Country #
USA 3
France 2
Colombia 2
I tried in knime via GroupBy but only it’s counting the number of the total rows of the file. Please, any help will be welcome.
After that I had to build a Pareto table but with the previous totals it’s easy to finish in excel.
Best regards.
J. Ignacio Saavedra V.
Bogotá - Colombia
Hi marzukim, thanks for the wellcome and your answer.
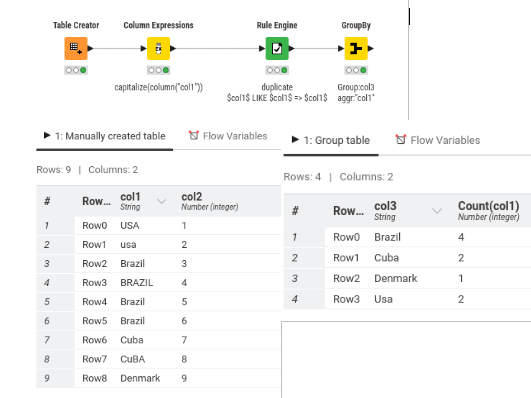
When I replicate the column, ¿does knime automatically group the rows by the column values?
I can’t see clearly the code or graphs that you attached, if it’s not too much abuse, ¿could you attach the code, please?
glad to hear that you were able to resolve the issue.
just to update you, you can take out the rules node (as not use in “groupby”).
i just use it for other execution tests. it still give the same results.