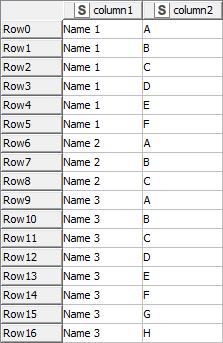
I have a larger dataset consisting of fields such as Column 1 being name (1, 2, 3,etc.), and Column 2 being an ID, and I wanted to perform a function that would count up the number of ID occurrences per name.
Ideally, the result would be the unique name and the total count of each ID per name. Example:
Name 1 = 6
Name 2 = 3
Name 3 = 8
I’ve tried variable loops and Rank/String Manipulation but was not able to obtain the result above.
What you are looking for is counting the occurrences by grouping the column1, so a GroupBy node is required.
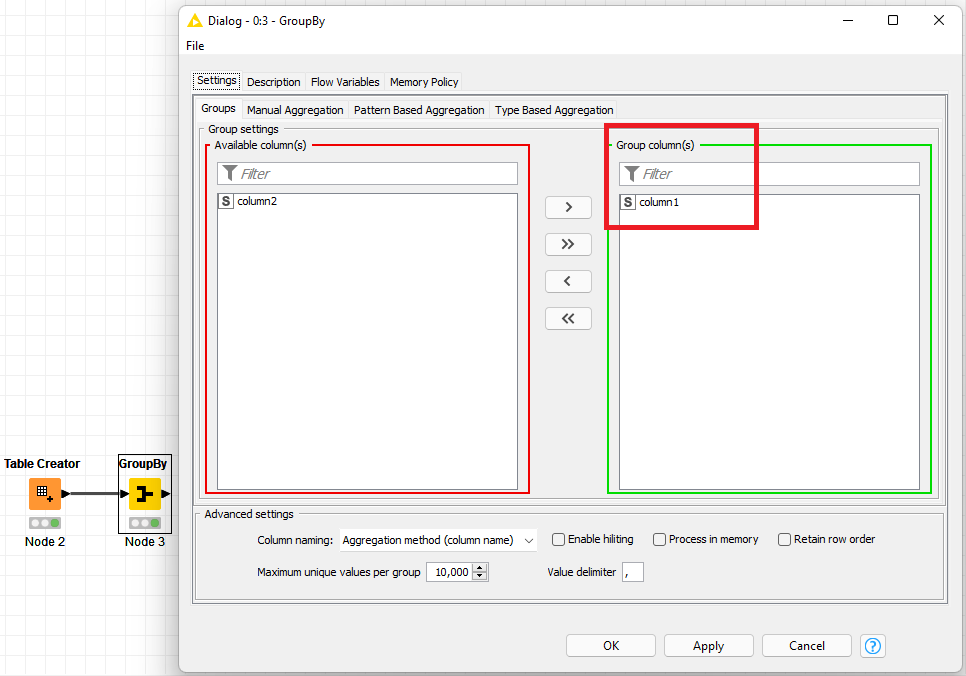
After you create/read your input data, add the GroupBy node and on the right side, include the column you want to group, this would create one row per value in the colum1:
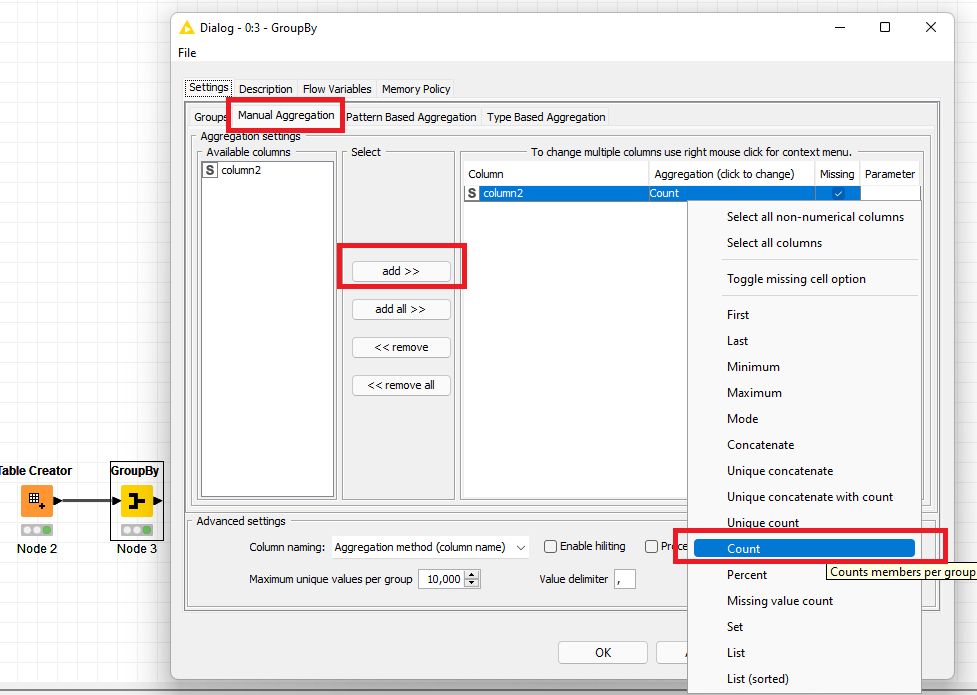
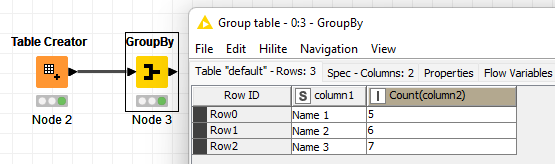
Then, in the next tab of the node, which is Manual Aggregation you should add the column you want to count, being column2 in this example, and the Count function which will count the no. of rows per each value on the column1:
For more complex conditional sums, you can also start with if statement in a Column Expressions Node and have a positive result =1 in a new column. Then use the GroupBy Node to Sum them. This is also an easy way to do conditional running totals.