I think that your English is good.
I’m just trying to get an idea of what your data looks like, but you’re not providing those answers.
I try not to assume anything. And in this case, I still don’t know if you have
- a unique individual per row, and 150 columns with a single number in each cell
- a unique individual per row, and a single column with 150 values per cell
- a unique individual per column, and 150 rows with a single number in each cell
- a unique individual per column and 1 row with 150 values per cell
When asking for help here, it’s best if you can provide as much information as possible, including example data and/or a workflow. It’s also helpful if you detail what you’ve tried.
Here’s a workflow:
The table contains 5 person’s responses to 12 questions on a scale of 1-10.

The workflow calculates, for each person, how many responses are higher than 5. I first unpivot the data, then use a Rule Engine node to do the comparison. If the response is higher than the threshold, then that row gets tagged with a 1.
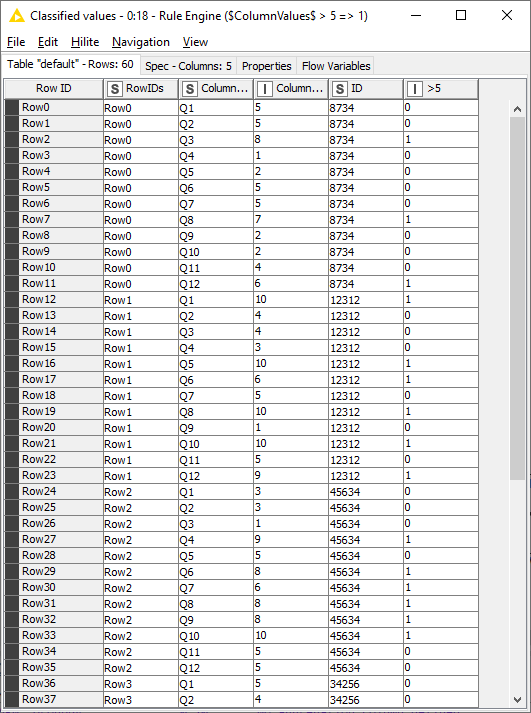
Then I use the GroupBy node to calculate the sum of all the tags for each individual.
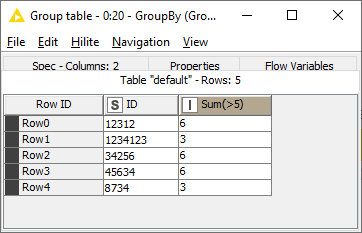
Because I don’t know what data you’re working with, this workflow may not be applicable to your case.