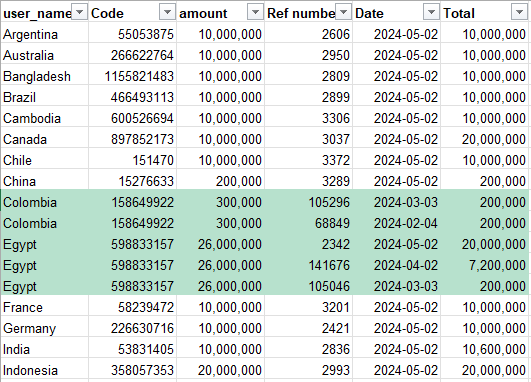
Hi everyone, I have this data as attached. I wrote SQL for drafting first and now I want to bring it to work on KNIME but I don’t know how to convert it into Column Expressions (if any node works).
Here is my SQL, please advise me to change it into KNIME:
WITH cte AS(
SELECT*
FROM test (1).test – My data attached
ORDER BY user_name, Date DESC)
SELECT
c1.user_name, c1.Date, c1. amount, c1. Total.
CASE
WHEN MAX(c1.amount)-SUM(c2.total) >=0 THEN c1.Total
WHEN MAX(c1.amount)-SUM(c2.total)<0 AND c1.Total + (MAX(c1.amount)-SUM(c2.total)) >=0 THEN c1. Total + (MAX(c1.amount))-SUM(c2.total))
ELSE 0
END AS refund
FROM cte c1
JOIN cte c2 ON c1.user_name = c2.user_name AND c1.Date <= c2.Date
GROUP BY c1.user_name, c1.Date, c1.amount, c1.Total
ORDER BY c1.user_name, c1.Date DESC
Hi @Nguyen_Huynh_Du , Column Expressions would not be a good fit for a translation of SQL.
because…
a single column expression returns only a single column
group by and aggregate functions across rows is better done by other nodes, such as the “GroupBy” node
in general, a variety of different nodes would be used for producing the different types of returns for the various columns.
So the question I have when anybody asks how to do something using “Node X”, is are they specifically wanting to use that node for the purposes of learning that node, or are they actually just wanting to get the job done, using whichever nodes are best suited?
For most people, it is actually that they just wish to get the job done rather than apparently saying “please demonstrate how I can paint my car using a hammer”
I have reproduced your table here in text form so that it can be easily copied by other people wishing to help. NB - It was translated from the picture by chatGPT so may not be entirely accurate.
user_name
Code
amount
Ref number
Date
Total
Argentina
55053875
10000000
2606
2024-05-02
10000000
Australia
266622764
10000000
2905
2024-05-02
10000000
Bangladesh
1155821483
10000000
2809
2024-05-02
10000000
Brazil
466493113
10000000
2899
2024-05-02
10000000
Cambodia
600526694
10000000
3008
2024-05-02
10000000
Canada
897852173
10000000
3037
2024-05-02
10000000
Chile
151470
10000000
3722
2024-05-02
10000000
China
15276633
200000
3289
2024-05-02
200000
Colombia
158649922
300000
105296
2024-03-03
200000
Colombia
158649922
300000
6849
2024-02-04
200000
Egypt
598833157
26000000
2342
2024-05-02
20000000
Egypt
598833157
26000000
141676
2024-04-02
7200000
Egypt
598833157
26000000
105460
2024-03-03
200000
France
58239472
10000000
2908
2024-05-02
10000000
Germany
226630716
10000000
2421
2024-05-02
10000000
India
53831405
10000000
2836
2024-05-02
10000000
Indonesia
358075353
20000000
2993
2024-05-02
20000000
Now, looking at the SQL, can you confirm if it is actually doing what you want?
You are using max(c1.amount) in your calculations, but also grouping by c1.amount, for example, so I feel that may not be what you intended.
Back to the question of whether you are wanting to use specific nodes, or see how it could be done with KNIME nodes, or if you “just want to get the job done”… if a solution were presented where you could simply execute the SQL (or an adapted version of it) against your KNIME table, would that be potentially suitable?
Hi @takbb , thanks for you reply and.
Yes, the data transfered is correct.
I agree with you that I only want the job done. I prefer using column expressions because as so far as I know that column expressions node can produce coding and easier than Java Snippet.
I welcome all your help because I am still stuck with this.
Yes, correct for the SQL. I grouped the c1. amount only when the c1.Date <= c2. Date. Means that when the date is not max(Date), group all of them.
Refund is the desired column. Feel free to adjust the SQL code or recommending me other nodes.
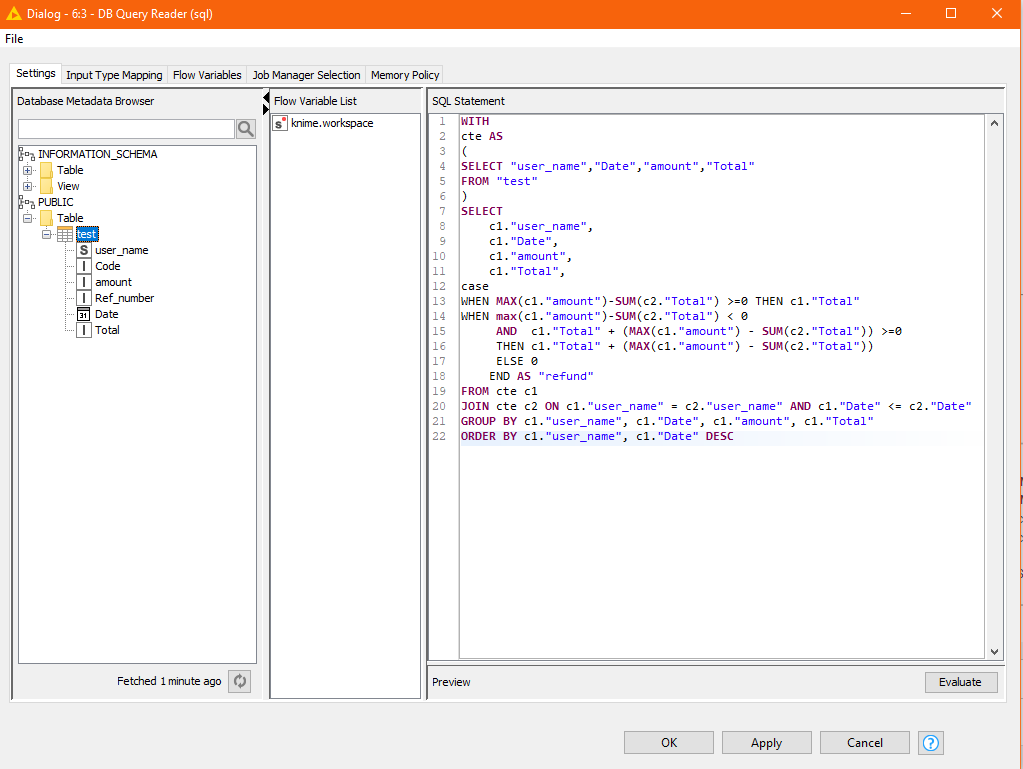
Hi @Nguyen_Huynh_Du , thanks for the update. If you are happy that the SQL is doing what you want, then that’s fine. I wanted to be sure before trying to “reimagine” it into KNIME nodes but I realise this post isn’t about being an SQL tutorial, lol, so here goes…
I’ve used the initial data set for this example, because I’d already started playing with this.
My question about whether you’d be happy for an SQL solution was because one of the simpler options is to make your KNIME data into a database table. Typically you could do this by creating an H2 database connection, creating a table and uploading your KNIME table into it, and then execute a query against that data.
That though, feels a bit “involved”, so it was for that use case that I previously created some components that are freely available on the hub.
For a single one off table, you can use this component:
and then write the sql query directly against it.
I have uploaded a demonstration workflow to the hub here:
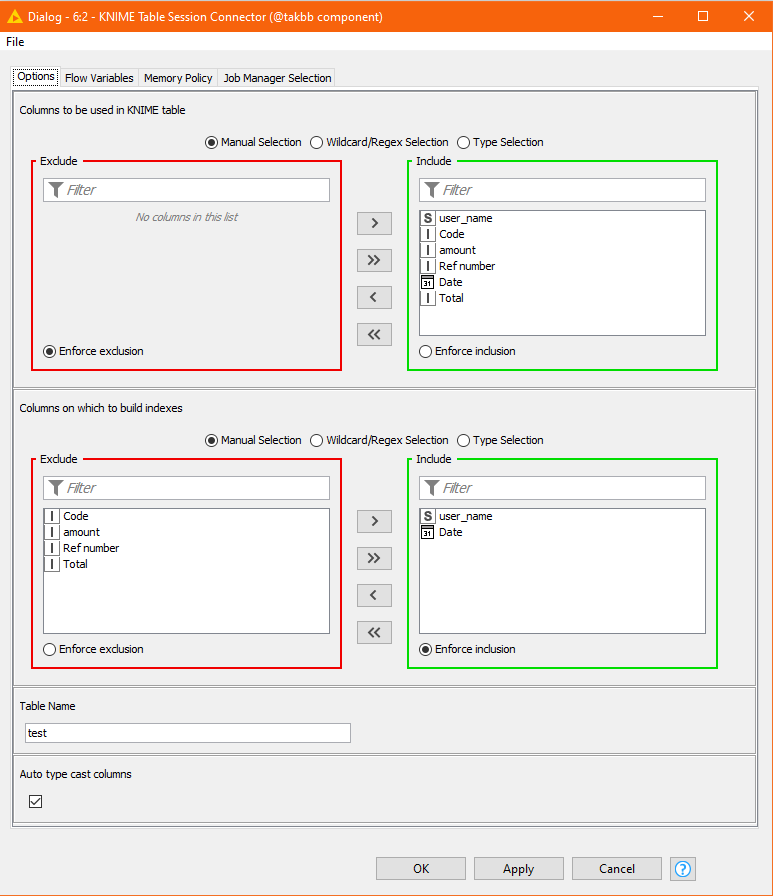
You simply direct your data table at the component
and configure it, specify the columns to be included, and any columns for which indexes should be created (optional, but can improve performance on larger datasets). You also give the table a name, in this case “test”
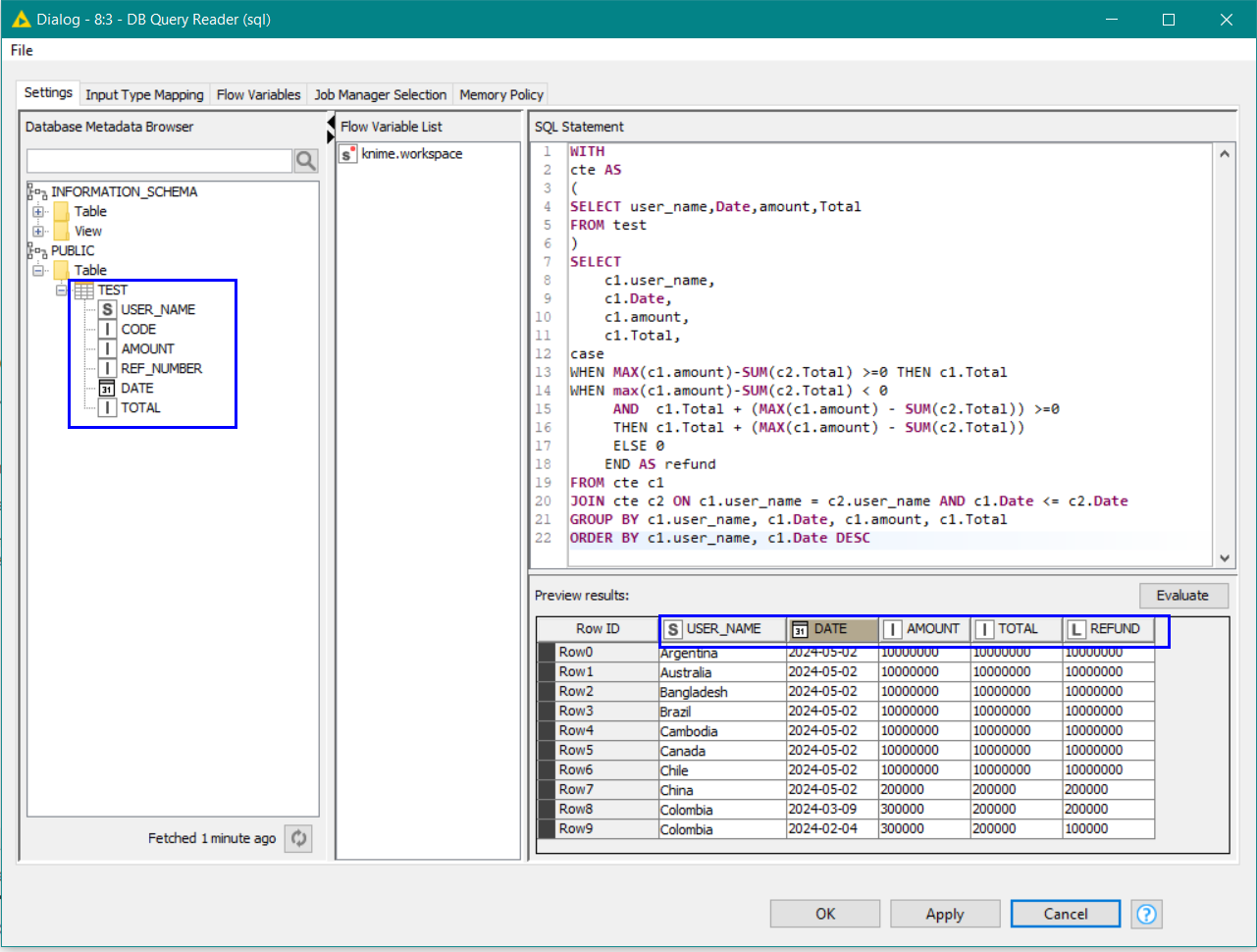
WITH
cte AS
(
SELECT "user_name","Date","amount","Total"
FROM "test"
)
SELECT
c1."user_name",
c1."Date",
c1."amount",
c1."Total",
case
WHEN MAX(c1."amount")-SUM(c2."Total") >=0 THEN c1."Total"
WHEN max(c1."amount")-SUM(c2."Total") < 0
AND c1."Total" + (MAX(c1."amount") - SUM(c2."Total")) >=0
THEN c1."Total" + (MAX(c1."amount") - SUM(c2."Total"))
ELSE 0
END AS "refund"
FROM cte c1
JOIN cte c2 ON c1."user_name" = c2."user_name" AND c1."Date" <= c2."Date"
GROUP BY c1."user_name", c1."Date", c1."amount", c1."Total"
ORDER BY c1."user_name", c1."Date" DESC
as you can see, this SQL is very similar to your original, but I have just had to deal with the case-sensitivity of the column and table names.
As an interesting exercise though, I have also built the equivalent of that same SQL using standard KNIME nodes
The two give the same results (albeit there are differences in data types - long vs double/integer) between the two mechanisms.
For a further demo of the KNIME Table Session Connector, and its counterpart the KNIME Table Connector (used if you want to join to different KNIME tables using the same database connection), see this workflow:
Your solution was really impressive! I tried it and it worked.
However, the node KNIME Table Session Connector. I tried to download it but it showed me this error. Can you advice me on this please?
nodes contained nodes raised a warning
MISSING NoOp (Table) #13007: Node can’t be executed - Node “NoOp (Table)” not available from extension “NodePit Power Nodes” (provided by “Philipp Katz, Daniel Esser; nodepit.com”; plugin “com.nodepit.noop.plugin” is not installed)
Hi @Nguyen_Huynh_Du , ah OK, my apologies. It seems I had forgotten that the component uses the “noop” nodes that are part of the nodepit power nodes.
These are a set of free utility and convenience nodes, available from here:
The installation instructions can be found on the above link.
Let me know if you are unable to install these, as I can probably modify the components to not use those nodes if it is a barrier to using the components.
I’ve updated the components and sample workflows so they no longer require the NodePit Power Nodes. So if you try to drop them on a workflow now, they should no longer show the error.
Amazing work @takbb ! So now the end user has another toolkit and can work on his / her data using SQL as well aside from python and java (from a low code perspective).
I’m assuming this is similar to having duckDB in a way.
Just a question is it possible to type in the column names without the apostrophes; i.e. | Select user_name, Date | instead of | SELECT “user_name”,“Date” |
This depends on your data table. In line with (most) SQL databases, the underlying H2 database treats all column and table names as upper case unless enclosed in double-quotes. So provided that your table name and column names consist only of upper case letters, underscores and digits (no spaces, or lower case) then the underlying table and columns will be created using upper case, and you can then enter your query without using double-quotes:
WITH
cte AS
(
SELECT user_name,Date,amount,Total
FROM test
)
SELECT
c1.user_name,
c1.Date,
c1.amount,
c1.Total,
case
WHEN MAX(c1.amount)-SUM(c2.Total) >=0 THEN c1.Total
WHEN max(c1.amount)-SUM(c2.Total) < 0
AND c1.Total + (MAX(c1.amount) - SUM(c2.Total)) >=0
THEN c1.Total + (MAX(c1.amount) - SUM(c2.Total))
ELSE 0
END AS refund
FROM cte c1
JOIN cte c2 ON c1.user_name = c2.user_name AND c1.Date <= c2.Date
GROUP BY c1.user_name, c1.Date, c1.amount, c1.Total
ORDER BY c1.user_name, c1.Date DESC
Any identifiers not enclosed in double quotes are automatically converted to uppercase by the database.
There is an option on the H2 Connector to “Delimit only identifier with spaces” which defaults to off. I could potentially add that option to the component, but I think it would be more confusing.
This is because it would cause column names to become upper case except if the column name contained a space. So a column called user_name would automatically be created as USER_NAME but a column user name, because it contains a space would be automatically quoted by the database driver when the underlying table is created, and so the name would remain in lower case user name. I feel it is clearer if (where possible) the column names remain as they are in the input table.
Let me know if you want to convert your column names to upper case prior to using the components, and need assistance with achieving that.
Thanks for your explanation, really appreciate it!
That’s fine, I could use column name extractor / column renamer to capitalise before I push the data to the node and reset it after it’s passed through the node.