KNIME Forum Archive
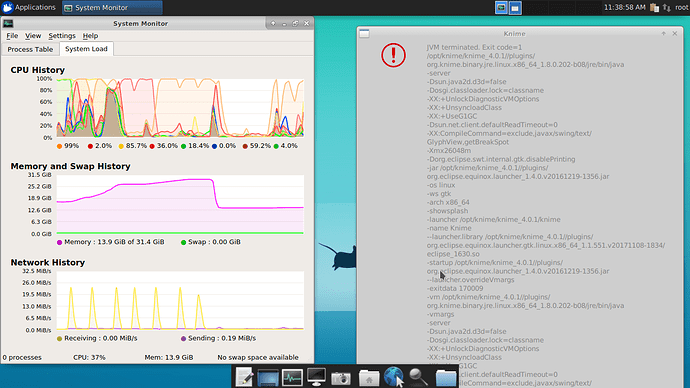
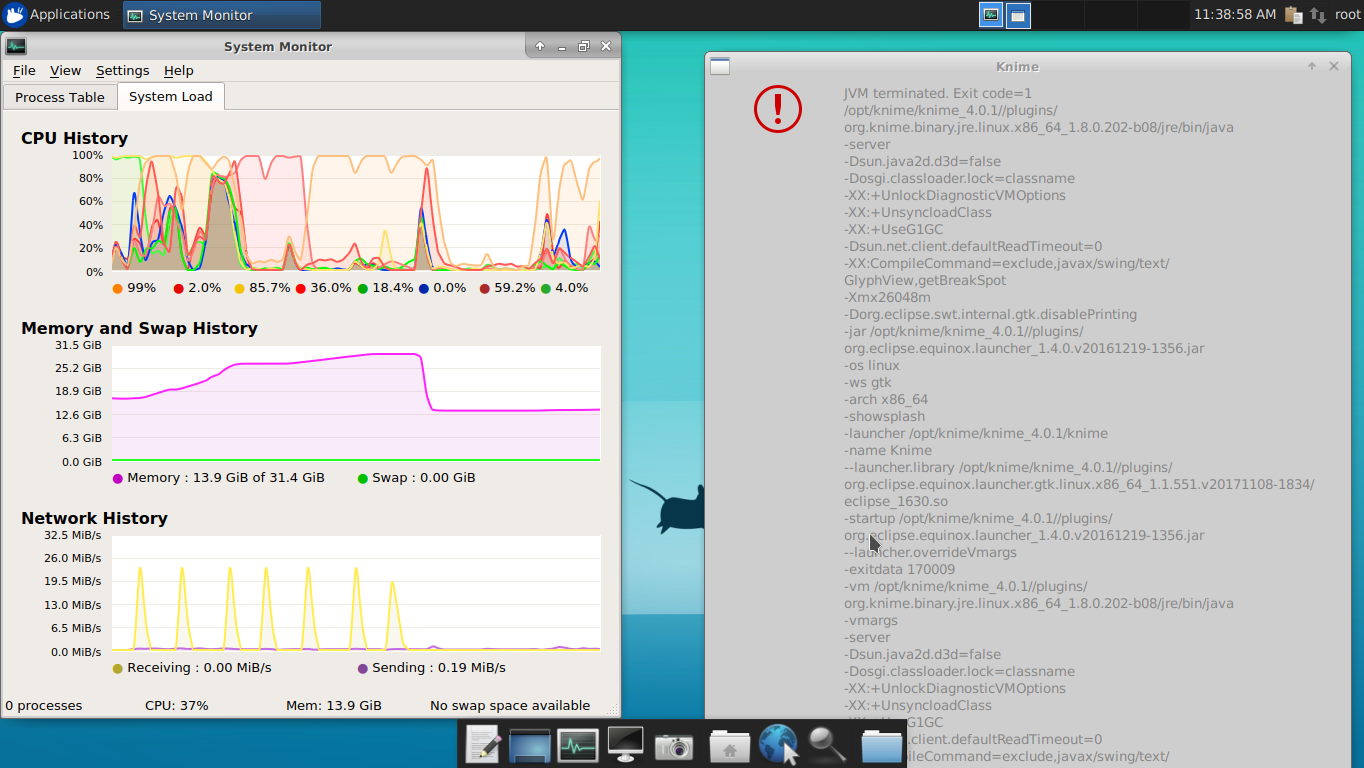
CPUUtilization high and jobs failed - AWS - knime server 4.9
KNIME Server
navinjadhav
November 8, 2019, 7:01am
16
swap%20full%20error%20jvm
1364×768 256 KB
show post in topic