Hi Everyone,
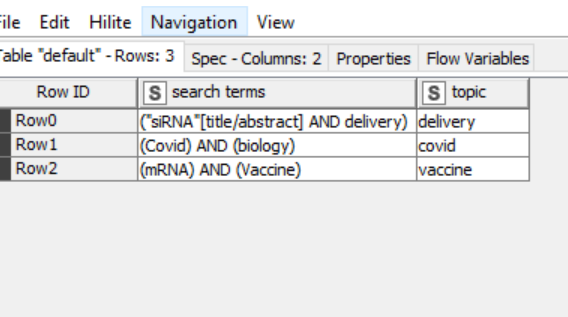
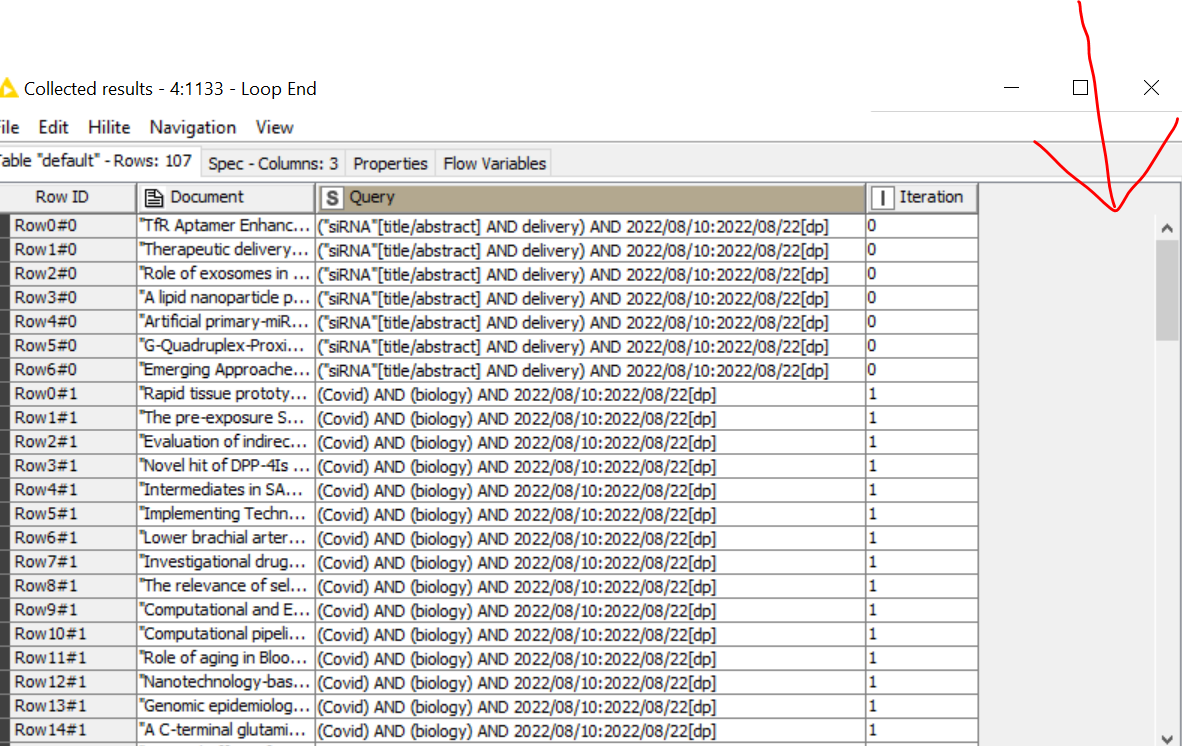
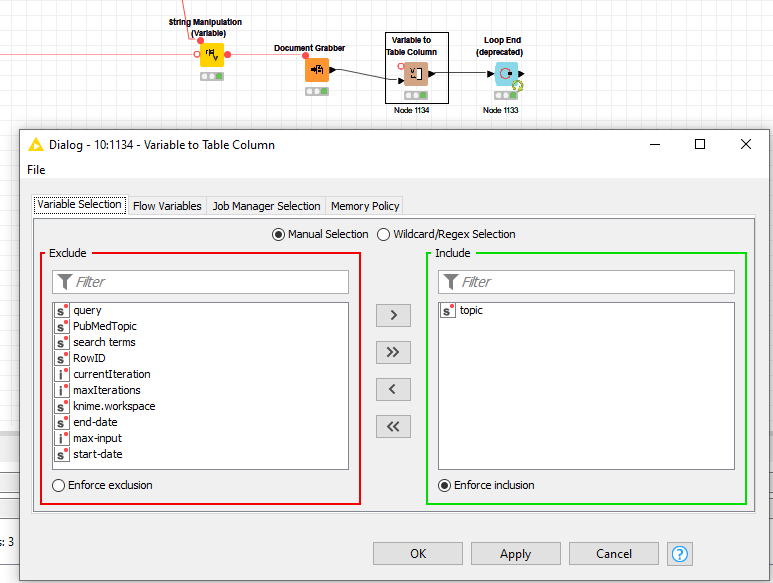
I am creating an automated PubMed search for multiple topics. I build this based on inspiration from a few former workflows posted in this forum. Everything works fine except I want to create a new column to annotate topics for each query. For example. in the first image, I have searched terms and topics. In the second image, I need the topics column for each query. Can someone have a clue how to do it? I also uploaded the workflow if it makes it easier to understand. Thank you.
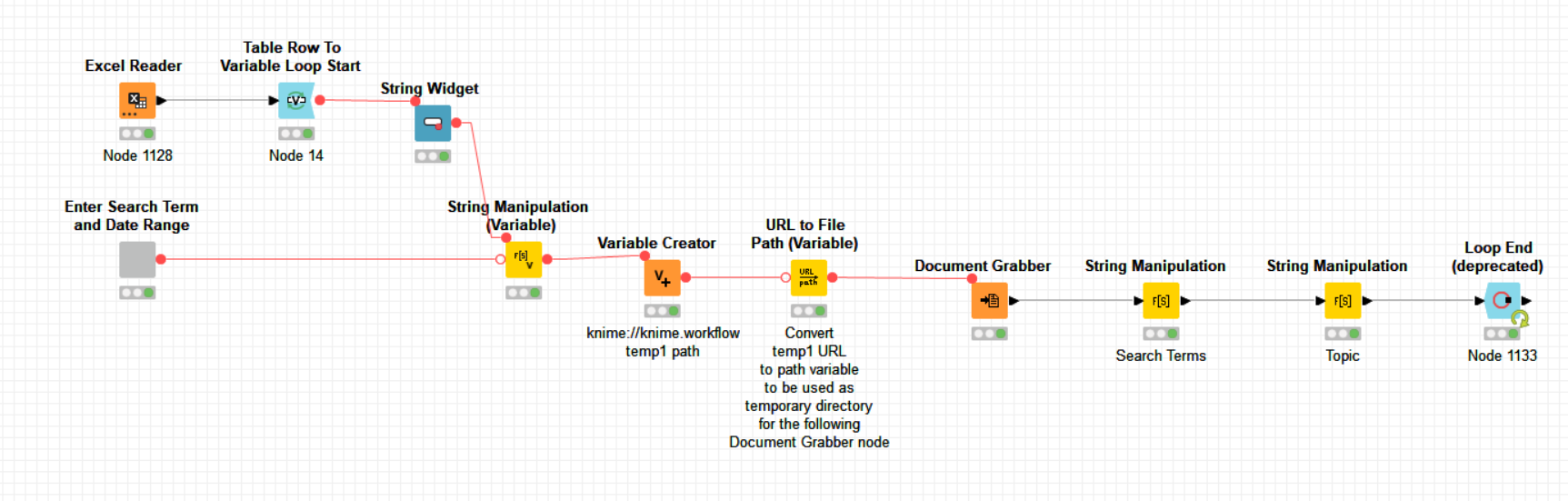
Please find below your workflow with the required modifications to get it to work.
I also added a generic way of gathering a current temp1 workflow directory “knime://knime.workflow/data/temp1” so that temp files can be stored locally making this workflow more generic for everybody:
Brilliant!!! Thank you both for explaining how to achieve it and for editing the workflow. I appreciate it very much. I am learning a lot everyday from this forum
Hi @aworker@ArjenEX and all,
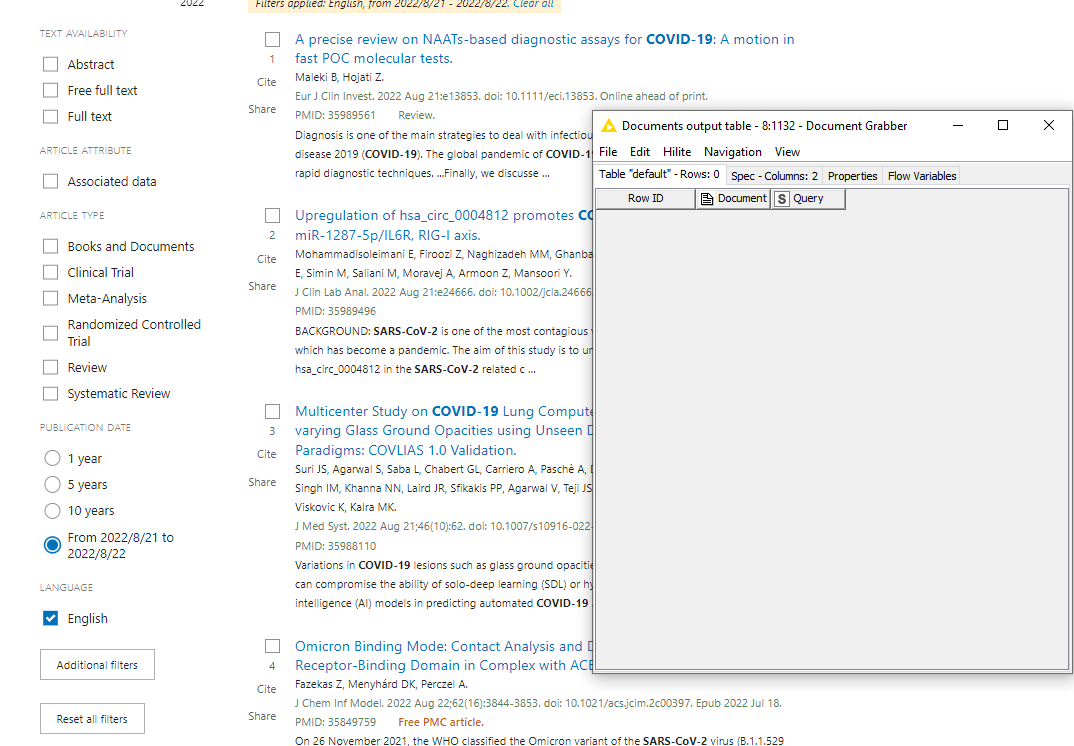
it seems there is a problem with the workflow when I search for a narrow date range. For the search term (Covid) AND (biology), I get 4 hits on the PubMed website but I get an empty table with the workflow. Unfortunately, I could not identify where this problem is coming from. Could anyone of you spot the issue?
It’s on the left hand side under Publication date, meaning from yesterday and today.
@paramasi
As to why you are getting different results, it appears to be a long outstanding bug unfortunately.
See:
I also played around with it but the only other noteworthy thing I found is that the website gives a slightly different query when I search for the same terms and the date range: (Covid) AND (biology) AND (2022/8/20:2022/8/22[pdat]) . This instead of dp like you have, but ultimately it didn’t make a difference.
Hi @aworker I was using the date range from 21.08.2022 to 22.08.2022.
As @ArjenEX mentioned above, there seems to be a bug that may be causing this issue. Thanks for bringing it to my attention!
When I played around, with a wider date range, I noticed that the most recent articles are not listed by the document grabber, but the rest are in perfect match with a direct search on the PubMed website.
I updated the workflow with a few more options to visualize the results (attached).
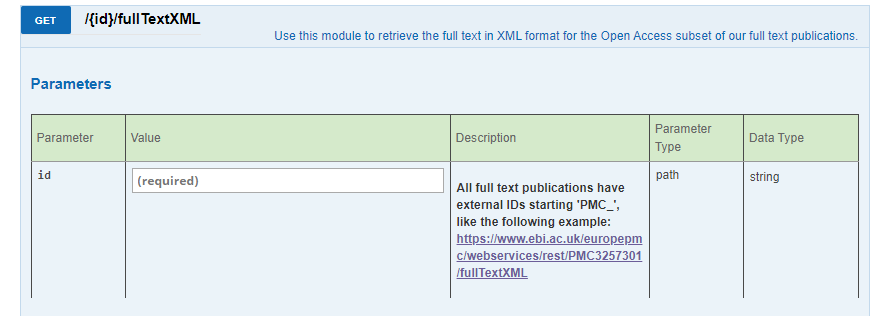
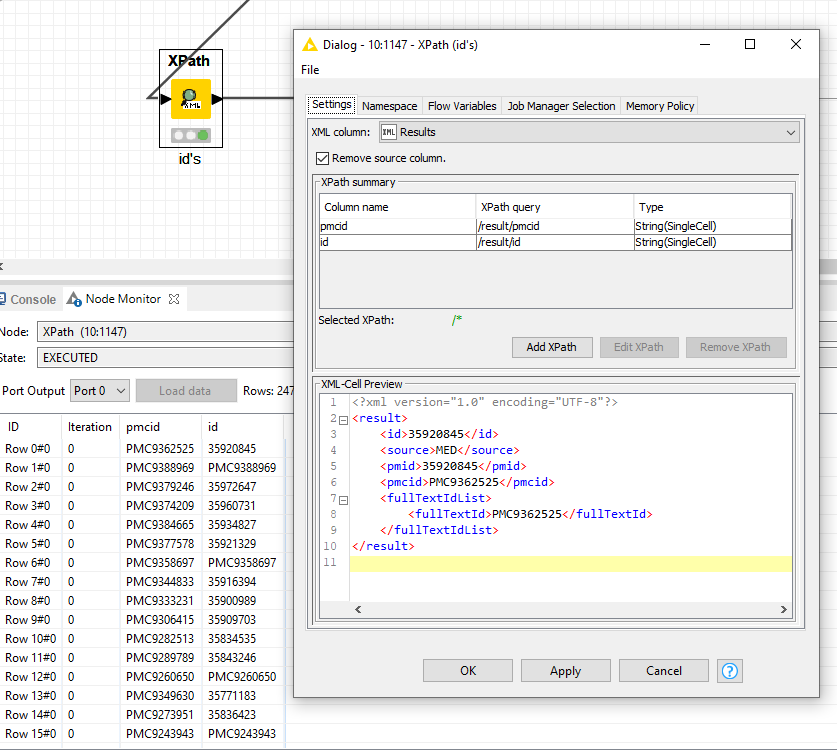
Is there any other option I can use other than the document grabber to solve the issue of search results? I was trying to use the ‘European PubMed Central Advanced Search’ node to replace the document grabber, but the result format is in XML and I do not know how to extract this information. Seems more work and help are needed
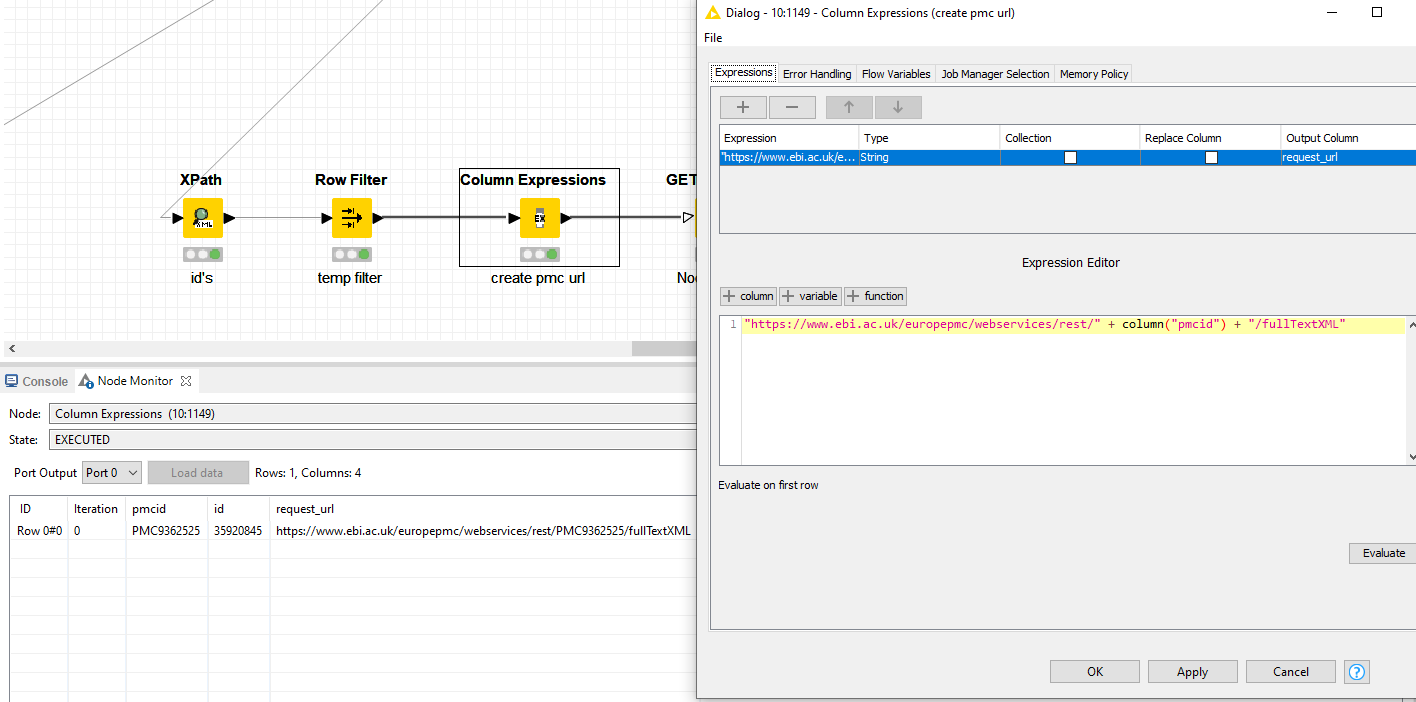
You won’t get this overnight I’m afraid. The result you’re getting out of the node currently refers to the id and pmcid of each document. You need to then use these values as input for another subsequent query.
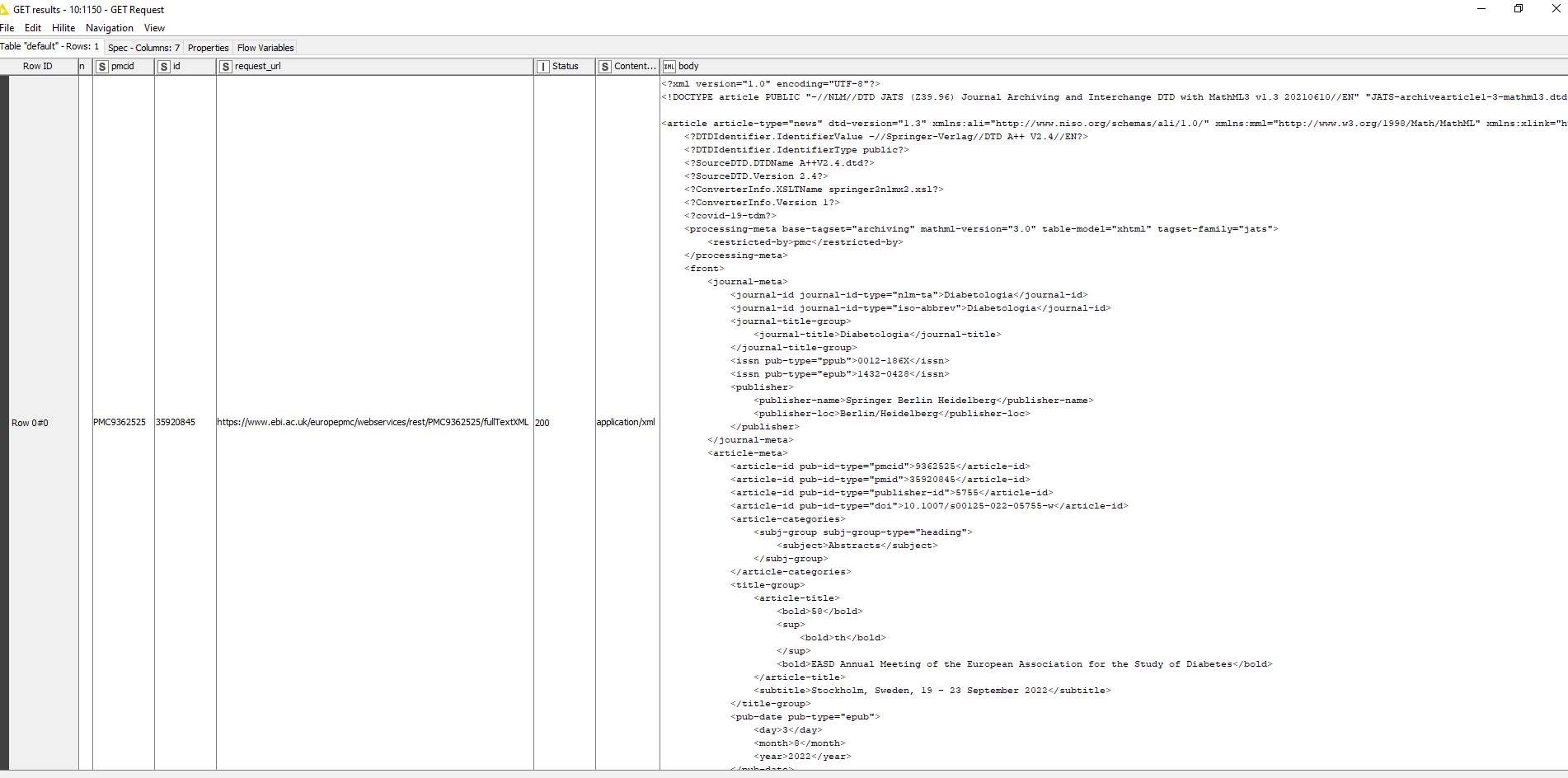
The XML that it’s returning is a very poorly build one which makes it a pain in the rear to extract data properly.
It’s a very slow process due to the size of each xml, it will take ages to process all the results.
The majority of the search results is not even accessible and will give you a 404 error.
The structure of the xml’s is also different so getting the actual title, authors, etc. also has to be done dynamically. Could get a complex matter, even more so if you don’t have a lot of xml experience.
Honestly, I would take this route as last resort. You might be even better of with a webscraper approach. For example with Selenium nodes.
The EU website is somewhat structured whereby the different section are pretty easily recognizable.
But this also comes with its disadvantages like having to account for pagination.
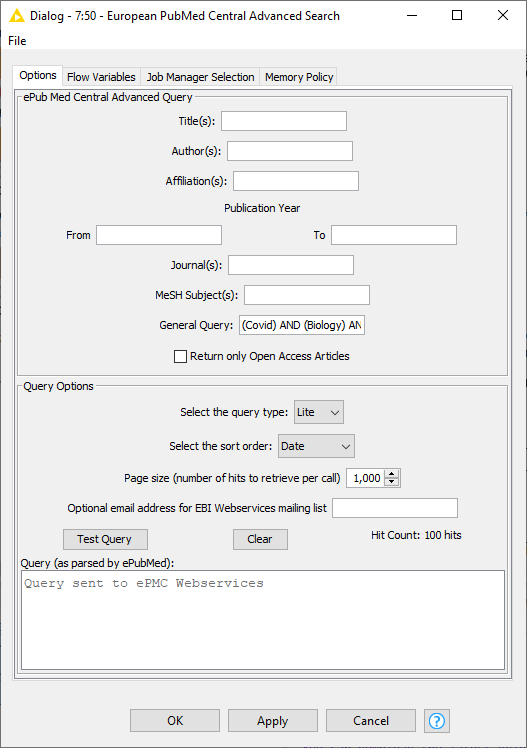
What you also could try is approach the great people of @Vernalis , who made the PubMed Central Advanced Search node. I don’t see any public examples on the KNIME Hub, but maybe they have some reference material on how this can be used effectively.
Hi @ArjenEX, Thank you so much for your very detailed answers. You are absolutely right, it does seem complicated. For the moment, I will use the current workflow and keep an eye on any other alternative options.
Thanks again to both @ArjenEX and @aworker for your support.
We don’t have any specific examples unfortunately for the node, but it should be reasonably obvious I think how to try using it. Most of the query can be copied from the ePMC website or your input table into the ‘General Query’ box: