for row in table:
for element in set:
return (element, element+1)
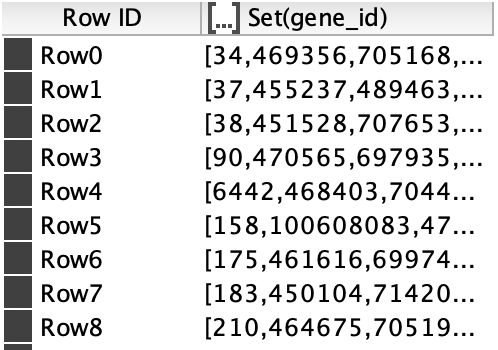
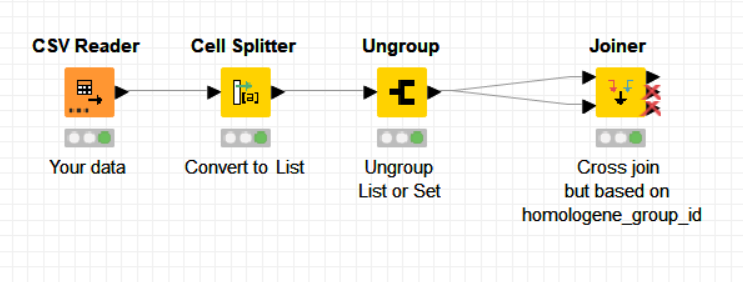
Is there a way to achieve this with built in nodes or do I have to write a Java snippet? Would also be great if someone could share a few ideas how to do that in a snippet.
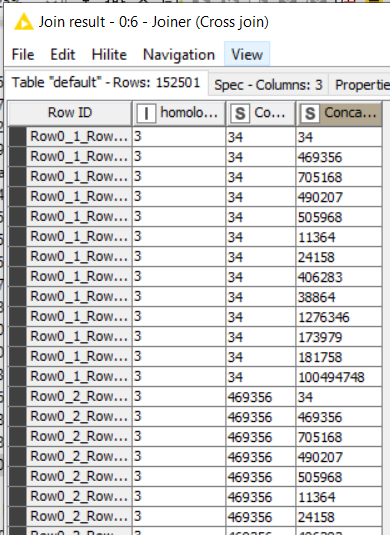
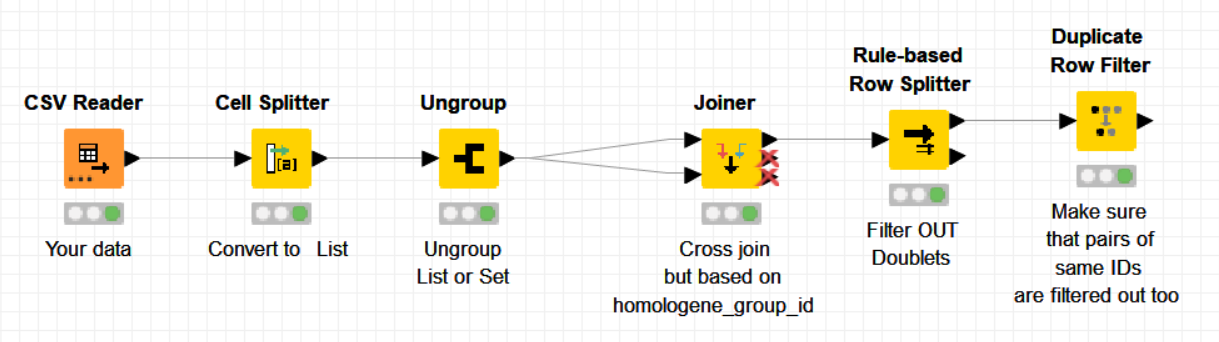
The trick here is to filter out pairs of “doublets” based on Alphabetic order. Since they are all duplicated, one of the two pairs is in alphabetical inverse order and hence, you can filter out the one that is alphabetically “bigger”, for instance:
11364 34 (is removed)
34 11364 (but this one is kept)
Then you need to make sure that only one instance of “self-pairs”, for instance 34 34 is kept too, because normally there should be two. This is done using the -Duplicate Row Filter- node.
Since you are working with gene sequence IDs, I guess your aim is to build a non-directed relational graph and for this you just need one edge between two related genes if the graph is not directed. But I’m just guessing or anticipating what maybe you want to eventually implement ?
Thanks for your kind comments and for having validated the answer !