Hi @ivan_prigarin
We have a company hackathon coming up in May. With 20 cool projects submitted. Looking through the list, 4-5 of these ideas are interested in exploring AI for their business case.
Data is not allowed to leave the company network, unless the it has been scrutinized by Security. That’s why the OpenAI/DeepSeek nodes are banned, while there might be a way for the Azure nodes. This still requires a “scrutiny-round”. For a Hackathon and exploration phase, this is poison to the process.
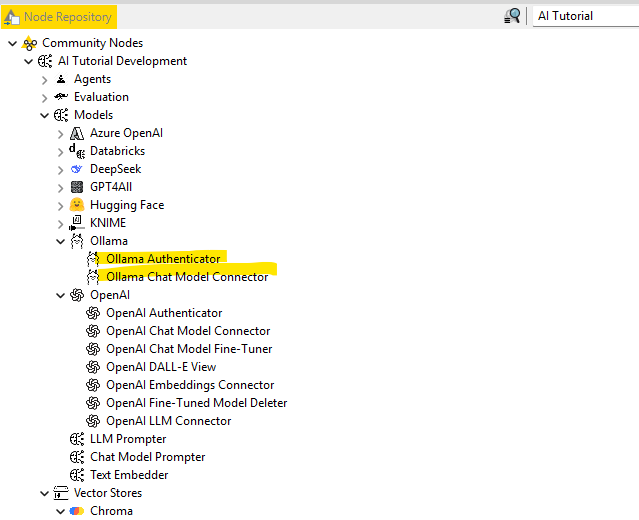
We have decent GPU server in R&D where we have Ollama loaded.
So for a Hackathon, to explore the business ideas, this would be ideal.
You can throw all the data you wan’t against it, without data leaving company network.
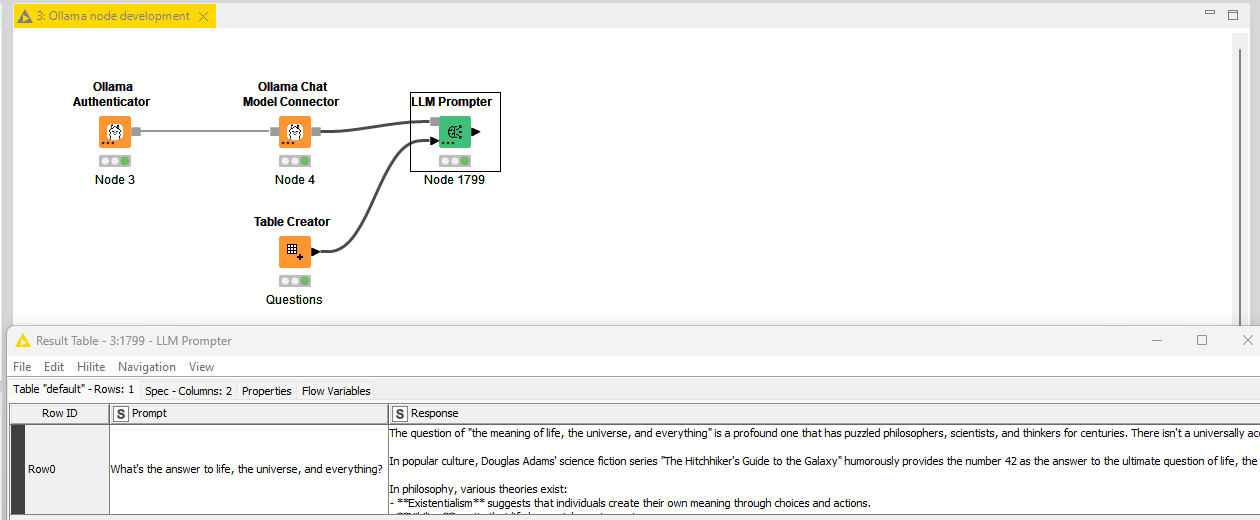
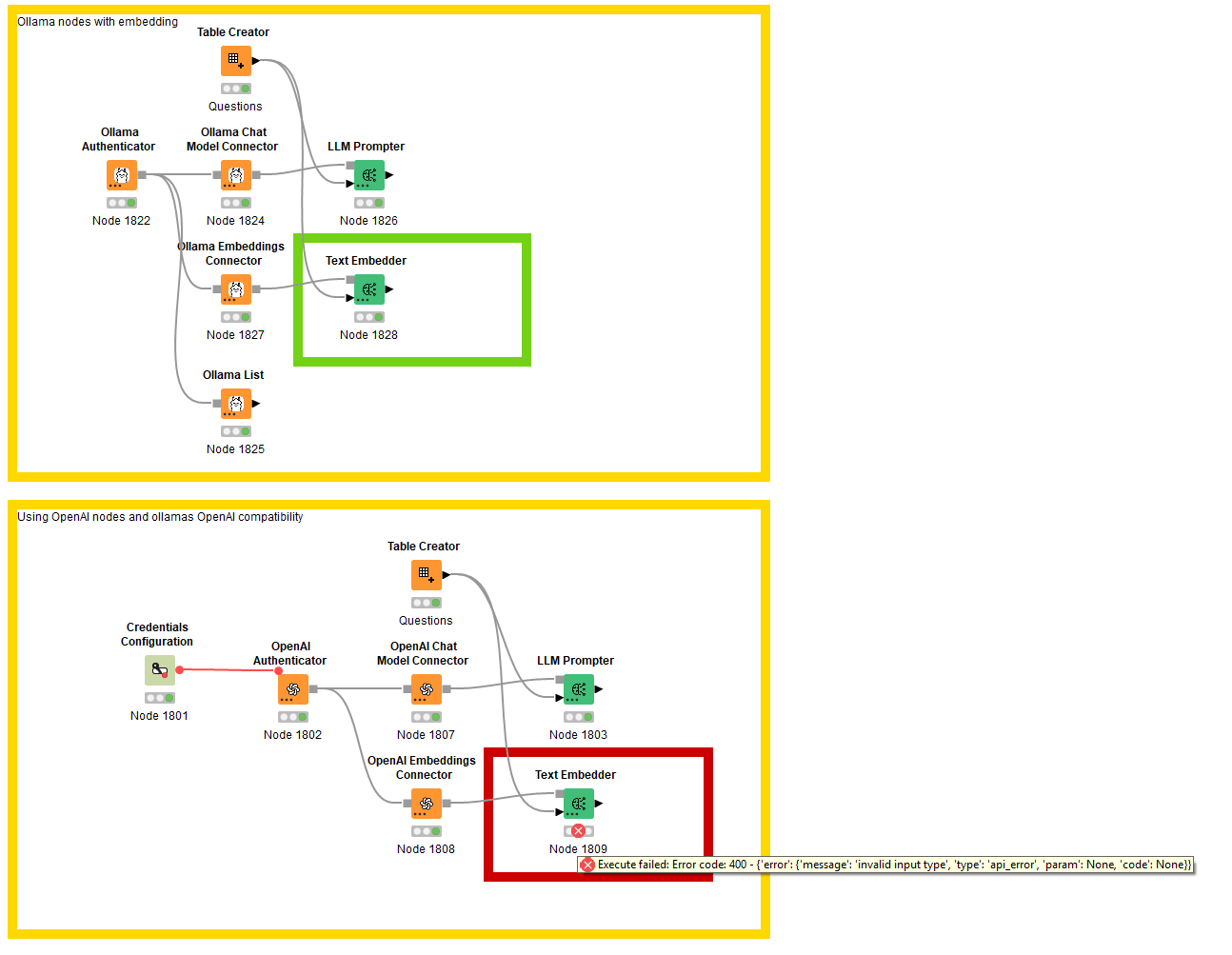
I know that Ollama has OpenAI compatibility, but
this only works with the Chat/LLM prompting nodes.
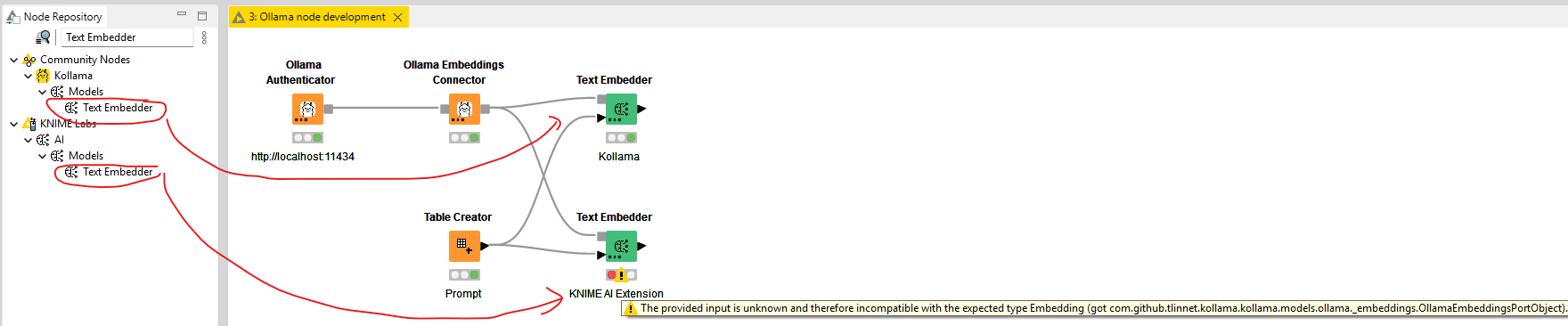
Not with the Embedding nodes.
And then the Vector stores seems to only work on local computer.
So, I would like to explore the options for a Snowflake / PostgreSQL database for vector storing.
I will look into these options.
Here is the code:
env.yml
name: llm_ollama_env
channels:
- conda-forge
- knime
dependencies:
- conda-forge::python=3.11
- conda-forge::pip=25.0.1
- knime::knime-python-base>=5.4
- knime::knime-extension>=5.4
- conda-forge::huggingface_hub=0.23.4
- conda-forge::chromadb=0.5.23
- conda-forge::faiss-cpu=1.7.4
- conda-forge::pydantic=2.10.2
- conda-forge::beautifulsoup4=4.12.3
- pip:
- langchain==0.3.14
- langchain-community==0.3.14
- langchain-openai==0.3.0
- langchain-ollama==0.3.1
- langchain-chroma==0.2.0
- gpt4all==2.8.2
- giskard==2.14.2
src\models\ollama
_auth.py
import knime.extension as knext
from ollama import Client
from base import AIPortObjectSpec
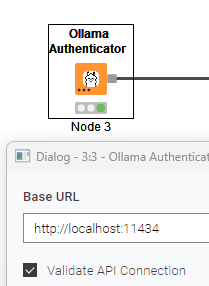
_default_ollama_api_base = "http://localhost:11434"
class OllamaAuthenticationPortObjectSpec(AIPortObjectSpec):
def __init__(
self, base_url: str = _default_ollama_api_base
) -> None:
super().__init__()
self._base_url = base_url
@property
def base_url(self) -> str:
return self._base_url
def validate_context(self, ctx: knext.ConfigurationContext):
if not self.base_url:
raise knext.InvalidParametersError("Please provide a base URL.")
def validate_api_connection(self, ctx: knext.ExecutionContext):
try:
self._get_models_from_api(ctx)
except Exception as e:
raise RuntimeError(f"Could not access Ollama API at {self.base_url}") from e
def _get_models_from_api(
self, ctx: knext.ConfigurationContext | knext.ExecutionContext
) -> list[str]:
ollama = Client(host=self.base_url, timeout=2)
models_response = ollama.list()
return [model["model"] for model in models_response["models"]]
def get_model_list(self, ctx: knext.ConfigurationContext) -> list[str]:
try:
return self._get_models_from_api(ctx)
except Exception:
return ["ollama-chat", "ollama-reasoner"]
def serialize(self) -> dict:
return {
"base_url": self._base_url,
}
@classmethod
def deserialize(cls, data: dict):
return cls(
data.get("base_url", _default_ollama_api_base)
)
class OllamaAuthenticationPortObject(knext.PortObject):
def __init__(self, spec: OllamaAuthenticationPortObjectSpec):
super().__init__(spec)
@property
def spec(self) -> OllamaAuthenticationPortObjectSpec:
return super().spec
def serialize(self) -> bytes:
return b""
@classmethod
def deserialize(cls, spec: OllamaAuthenticationPortObjectSpec, storage: bytes):
return cls(spec)
auth.py
import knime.extension as knext
# These import has to be relative. When using "src.models.ollama" the nodes disappear in the KNIME GUI.
from .base import ollama_icon, ollama_category
from ._auth import _default_ollama_api_base, OllamaAuthenticationPortObject, OllamaAuthenticationPortObjectSpec
ollama_auth_port_type = knext.port_type(
"Ollama Authentication",
OllamaAuthenticationPortObject,
OllamaAuthenticationPortObjectSpec,
)
@knext.node(
name="Ollama Authenticator",
node_type=knext.NodeType.SOURCE,
icon_path=ollama_icon,
category=ollama_category,
keywords=["Ollama", "GenAI"],
)
@knext.output_port(
"Ollama API Authentication",
"Authentication for the Ollama API",
ollama_auth_port_type,
)
class OllamaAuthenticator:
"""Authenticates with the Ollama API via API key.
**Note**: Default installation of Ollama has no API key.
"""
base_url = knext.StringParameter(
"Base URL",
"The base URL of the Ollama API.",
default_value=_default_ollama_api_base,
is_advanced=False,
)
validate_api_connection = knext.BoolParameter(
"Validate API Connection",
"If set, the API connection is validated during execution by fetching the available models.",
True,
is_advanced=False,
)
def configure(
self, ctx: knext.ConfigurationContext
) -> OllamaAuthenticationPortObjectSpec:
spec = self.create_spec()
spec.validate_context(ctx)
return spec
def execute(self, ctx: knext.ExecutionContext) -> OllamaAuthenticationPortObject:
spec = self.create_spec()
if self.validate_api_connection:
spec.validate_api_connection(ctx)
return OllamaAuthenticationPortObject(spec)
def create_spec(self) -> OllamaAuthenticationPortObjectSpec:
return OllamaAuthenticationPortObjectSpec(
base_url=self.base_url
)
_chat.py
import knime.extension as knext
from langchain_ollama import ChatOllama
# These import has to be relative. When using "src.models.x" the nodes disappear in the KNIME GUI.
from .._base import ChatModelPortObject, ChatModelPortObjectSpec, OutputFormatOptions
from ._auth import OllamaAuthenticationPortObjectSpec
class OllamaChatModelPortObjectSpec(ChatModelPortObjectSpec):
"""Spec of a Ollama Chat Model"""
def __init__(
self,
auth: OllamaAuthenticationPortObjectSpec,
model: str,
temperature: float,
num_predict: int,
n_requests=1,
):
super().__init__(n_requests)
self._auth = auth
self._model = model
self._temperature = temperature
self._num_predict = num_predict
@property
def model(self) -> str:
return self._model
@property
def temperature(self) -> float:
return self._temperature
@property
def num_predict(self) -> int:
return self._num_predict
@property
def auth(self) -> OllamaAuthenticationPortObjectSpec:
return self._auth
def validate_context(self, ctx):
self.auth.validate_context(ctx)
def serialize(self) -> dict:
return {
"auth": self._auth.serialize(),
"n_requests": self._n_requests,
"model": self._model,
"temperature": self._temperature,
"num_predict": self._num_predict,
}
@classmethod
def deserialize(cls, data: dict):
auth = OllamaAuthenticationPortObjectSpec.deserialize(data["auth"])
return cls(
auth=auth,
model=data["model"],
temperature=data["temperature"],
num_predict=data["num_predict"],
n_requests=data.get("n_requests", 1),
)
class OllamaChatModelPortObject(ChatModelPortObject):
@property
def spec(self) -> OllamaChatModelPortObjectSpec:
return super().spec
def create_model(
self,
ctx: knext.ExecutionContext,
output_format: OutputFormatOptions = OutputFormatOptions.Text,
):
if "reasoner" in self.spec.model:
return ChatOllama(
base_url=self.spec.auth.base_url,
model=self.spec.model,
temperature=1,
num_predict=self.spec.num_predict,
)
return ChatOllama(
base_url=self.spec.auth.base_url,
model=self.spec.model,
temperature=self.spec.temperature,
num_predict=self.spec.num_predict,
)
chat.py
import knime.extension as knext
# These import has to be relative. When using "src.models.ollama" the nodes disappear in the KNIME GUI.
from .base import ollama_icon, ollama_category
from .auth import ollama_auth_port_type
from ._auth import OllamaAuthenticationPortObject, OllamaAuthenticationPortObjectSpec
from ._chat import OllamaChatModelPortObject, OllamaChatModelPortObjectSpec
ollama_chat_model_port_type = knext.port_type(
"Ollama Chat Model", OllamaChatModelPortObject, OllamaChatModelPortObjectSpec
)
def _list_models(ctx: knext.ConfigurationContext):
if (specs := ctx.get_input_specs()) and (auth_spec := specs[0]):
return auth_spec.get_model_list(ctx)
return ["ollama-chat", "ollama-reasoner"]
@knext.node(
name="Ollama Chat Model Connector",
node_type=knext.NodeType.SOURCE,
icon_path=ollama_icon,
category=ollama_category,
keywords=["Ollama", "GenAI", "Reasoning"],
)
@knext.input_port(
"Ollama Authentication",
"The authentication for the Ollama API.",
ollama_auth_port_type,
)
@knext.output_port(
"Ollama Chat Model",
"The Ollama chat model which can be used in the LLM Prompter and Chat Model Prompter.",
ollama_chat_model_port_type,
)
class OllamaChatModelConnector:
"""Connects to a chat model provided by the Ollama API.
This node establishes a connection with a Ollama Chat Model. After successfully authenticating
using the **Ollama Authenticator** node, you can select a chat model from a predefined list.
**Note**: Default installation of Ollama has no API key.
"""
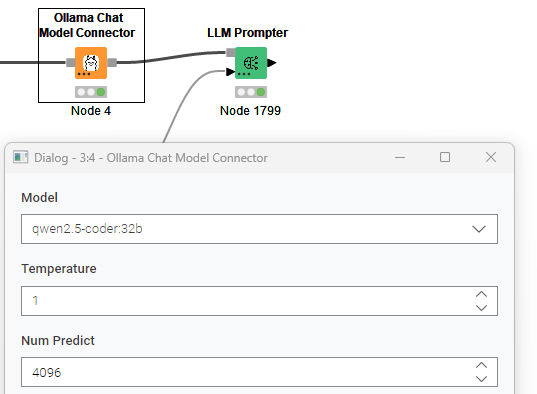
model = knext.StringParameter(
"Model",
description="The model to use. The available models are fetched from the Ollama API if possible.",
default_value="ollama-chat",
choices=_list_models,
)
temperature = knext.DoubleParameter(
"Temperature",
description="""
Sampling temperature to use, between 0.0 and 2.0.
Higher values will lead to less deterministic but more creative answers.
Recommended values for different tasks:
- Coding / math: 0.0
- Data cleaning / data analysis: 1.0
- General conversation: 1.3
- Translation: 1.3
- Creative writing: 1.5
""",
default_value=1,
)
num_predict = knext.IntParameter(
"Num Predict",
description="The maximum number of tokens to generate in the response",
default_value=4096,
)
def configure(
self,
ctx: knext.ConfigurationContext,
auth: OllamaAuthenticationPortObjectSpec,
) -> OllamaChatModelPortObjectSpec:
auth.validate_context(ctx)
return self.create_spec(auth)
def create_spec(
self, auth: OllamaAuthenticationPortObjectSpec
) -> OllamaChatModelPortObjectSpec:
return OllamaChatModelPortObjectSpec(
auth=auth,
model=self.model,
temperature=self.temperature,
num_predict=self.num_predict,
)
def execute(
self, ctx: knext.ExecutionContext, auth: OllamaAuthenticationPortObject
) -> OllamaChatModelPortObject:
return OllamaChatModelPortObject(self.create_spec(auth.spec))
base.py
import knime.extension as knext
from ..base import model_category
ollama_icon = "icons/ollama.png"
ollama_category = knext.category(
path=model_category,
name="Ollama",
level_id="ollama",
description="Ollama models",
icon=ollama_icon,
)
src\models_base.py
(moved from base.py to allow for testing)
import knime.extension as knext
from base import AIPortObjectSpec
class OutputFormatOptions(knext.EnumParameterOptions):
Text = (
"Text",
"Text output message generated by the model.",
)
JSON = (
"JSON",
"""
When JSON is selected, the model is constrained to only generate strings
that parse into valid JSON object. Make sure you include the string "JSON"
in your prompt or system message to instruct the model to output valid JSON
when this mode is selected.
For example: "Tell me a joke. Please only reply in valid JSON."
Please refer to the OpenAI [guide](https://platform.openai.com/docs/guides/structured-outputs/structured-outputs-vs-json-mode)
to see which models currently support JSON outputs.
""",
)
class LLMPortObjectSpec(AIPortObjectSpec):
"""Most generic spec of LLMs. Used to define the most generic LLM PortType"""
def __init__(
self,
n_requests: int = 1,
) -> None:
super().__init__()
self._n_requests = n_requests
@property
def n_requests(self) -> int:
return self._n_requests
@property
def supported_output_formats(self) -> list[OutputFormatOptions]:
return [OutputFormatOptions.Text]
class LLMPortObject(knext.PortObject):
def __init__(self, spec: LLMPortObjectSpec) -> None:
super().__init__(spec)
def serialize(self) -> bytes:
return b""
@classmethod
def deserialize(cls, spec: LLMPortObjectSpec, storage: bytes):
return cls(spec)
def create_model(self, ctx: knext.ExecutionContext):
raise NotImplementedError()
class ChatModelPortObjectSpec(LLMPortObjectSpec):
"""Most generic chat model spec. Used to define the most generic chat model PortType."""
class ChatModelPortObject(LLMPortObject):
def __init__(self, spec: ChatModelPortObjectSpec) -> None:
super().__init__(spec)
def serialize(self):
return b""
@classmethod
def deserialize(cls, spec, data: dict):
return cls(spec)
def create_model(self, ctx: knext.ExecutionContext):
raise NotImplementedError()
src\knime_llm.py
(No src\models\ollama\__init__.py, since this will interfere with testing)
from models.ollama.auth import OllamaAuthenticator
from models.ollama.chat import OllamaChatModelConnector
\tests\test__auth.py
import unittest
from unittest.mock import MagicMock, patch
from ollama._types import ResponseError, ListResponse, ModelDetails
import datetime
import pathlib
import sys
sys.path.append(str(pathlib.Path(__file__).parent.parent.joinpath('src')))
from src.models.ollama._auth import OllamaAuthenticationPortObjectSpec
class TestGetModelsFromAPI(unittest.TestCase):
def setUp(self):
# Set up a mock context and credentials
self.mock_ctx = MagicMock()
self.spec = OllamaAuthenticationPortObjectSpec(base_url="http://localhost:11434")
@patch("src.models.ollama._auth.Client")
def test_get_models_success(self, mock_ollama_client):
mock_response = MagicMock()
mock_response.list.return_value = ListResponse(models=[
ListResponse.Model(model='gemma3:12b', modified_at=datetime.datetime(2025, 3, 17), digest='6fd036cefda5093cc827b6c16be5e447f23857d4a472ce0bdba0720573d4dcd9', size=8149190199, details=ModelDetails(parent_model='', format='gguf', family='gemma3', families=['gemma3'], parameter_size='12.2B', quantization_level='Q4_K_M')),
ListResponse.Model(model='qwen2.5-coder:32b', modified_at=datetime.datetime(2025, 3, 8), digest='4bd6cbf2d094264457a17aab6bd6acd1ed7a72fb8f8be3cfb193f63c78dd56df', size=19851349856, details=ModelDetails(parent_model='', format='gguf', family='qwen2', families=['qwen2'], parameter_size='32.8B', quantization_level='Q4_K_M')),
ListResponse.Model(model='mxbai-embed-large:latest', modified_at=datetime.datetime(2025, 1, 27), digest='468836162de7f81e041c43663fedbbba921dcea9b9fefea135685a39b2d83dd8', size=669615493, details=ModelDetails(parent_model='', format='gguf', family='bert', families=['bert'], parameter_size='334M', quantization_level='F16')),
ListResponse.Model(model='nomic-embed-text:latest', modified_at=datetime.datetime(2025, 1, 27), digest='0a109f422b47e3a30ba2b10eca18548e944e8a23073ee3f3e947efcf3c45e59f', size=274302450, details=ModelDetails(parent_model='', format='gguf', family='nomic-bert', families=['nomic-bert'], parameter_size='137M', quantization_level='F16'))
])
mock_ollama_client.return_value = mock_response
# Call the method
models = self.spec._get_models_from_api(self.mock_ctx)
assert isinstance(models, list)
assert len(models) > 0
@patch("src.models.ollama._auth.Client")
def test_get_models_404_not_found(self, mock_ollama_client):
mock_response = MagicMock()
mock_response.list.side_effect = ResponseError("HTTP Error 404. The requested resource is not found")
mock_ollama_client.return_value = mock_response
# Call the method
self.spec._base_url = "http://localhost"
with self.assertRaises(ResponseError) as context:
self.spec._get_models_from_api(self.mock_ctx)
\tests\test__chat.py
import unittest
from unittest.mock import MagicMock, patch
import pathlib
import sys
sys.path.append(str(pathlib.Path(__file__).parent.parent.joinpath('src')))
from src.models.ollama._chat import OllamaChatModelPortObject
class TestCreateModel(unittest.TestCase):
def setUp(self):
# Set up a mock context and credentials
self.mock_ctx = MagicMock()
mock_spec = MagicMock()
self.portobj = OllamaChatModelPortObject(spec=mock_spec)
@patch("src.models.ollama._chat.ChatOllama")
def test_create_model_standard(self, mock_chat_openai):
# Setup mock spec
self.portobj.spec.model = "normal-model"
self.portobj.spec.auth.credentials = "test_creds"
self.portobj.spec.auth.base_url = "http://localhost:11434"
self.portobj.spec.temperature = 0.7
self.portobj.spec.num_predict = 1000
# Call method
self.portobj.create_model(self.mock_ctx)
# Verify ChatOllama was called with correct params
mock_chat_openai.assert_called_once_with(
base_url="http://localhost:11434",
model="normal-model",
temperature=0.7,
num_predict=1000
)
@patch("src.models.ollama._chat.ChatOllama")
def test_create_model_reasoner(self, mock_chat_openai):
# Setup mock spec
self.portobj.spec.model = "reasoner-model"
self.portobj.spec.auth.credentials = "test_creds"
self.portobj.spec.auth.base_url = "http://localhost:11434"
self.portobj.spec.num_predict = 1000
# Call method
self.portobj.create_model(self.mock_ctx)
# Verify ChatOllama was called with correct params for reasoner
mock_chat_openai.assert_called_once_with(
base_url="http://localhost:11434",
model="reasoner-model",
temperature=1,
num_predict=1000
)
Tests
conda activate llm_ollama_env
python -m unittest discover tests
# Or Test Single file / Class / Function
python -m unittest tests.test_utils
#
python -m unittest tests.test__auth
python -m unittest tests.test__auth.TestGetModelsFromAPI
python -m unittest tests.test__auth.TestGetModelsFromAPI.test_get_models_404_not_found
#
python -m unittest tests.test__chat
python -m unittest tests.test__chat.TestCreateModel