Dear All,
I am testing with Databricks community edition using the KNIME CreateDataBricks Env Node to connect. I managed to eliminate the experienced errors except the above mentioned following through KNIME the installation guide and the topic posted before titled “CreateDataBricks Env Node -Error”. KNIME manages to write the knime-manage-job-jar to Databricks cluster however it fails with unknown state error.
The detailed error messages is: “java.lang.RuntimeException: ManagedLibrarylnstallFailed : java.util.concurrent.ExecutionException: java.io.FileNotFoundException: /.knime-spark-staging-0328-072632-niter742/knime-spark-jobs-jar for library :JavaJarld(dbfs:///.knime-spark-staging-0328-072632-niter742/knime-spark-jobs-jar,NONE),isSharedLibrary-false”
I am using the the KNIME Databricks integration extension 4.3.2. The Databricks File System connector works and able to establish connection. I also created a new Databricks Community account as I read that a newly created cluster might solve the problem. However it is not the case for me.
I tried Databricks "6.4 (includes Apache Spark 2.4.5. Scala 2.11) and 8.0 (includes Apache Spark 3.1.1, Scala 2.12) versions.
It might be caused due to the concurrent execution of jobs but Databricks community edition does not have the capability to schedule jobs.
Could anybody advise how to solve the last bit to connect to Databricks? Thank you.
Andras
Looks like the Databricks file system in the cluster and the file system reachable from outside are not the same in the community edition. This makes it impossible to transfer files between KNIME and Databricks. I’m not sure if this is a bug in the Databricks Platform or a limitation of the community edition. Feel free to ask Databricks about that. If you upload some files to /tmp using the Databricks file system connector node in KNIME and afterwards create a python notebook in Databricks, the following does not show the uploaded files: %fs ls dbfs:///tmp/
Using the normal/payed version of Databricks works fine. You can run a trial version of the Databricks if you have an AWS, Azure or Google Cloud account.
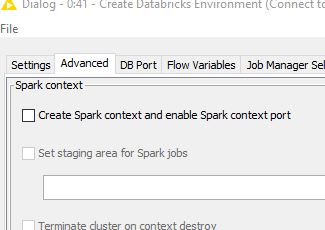
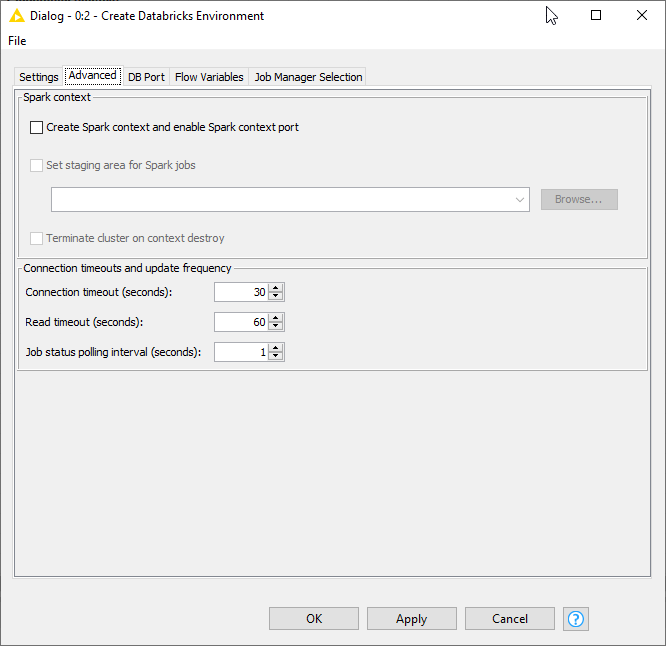
@akarman Could this be happening because of something to do with the spark jar creation? Try the Create Databricks Environment node with the create Spark context unselected/off no check mark. The default has option has it selected with a checkmark. The option for this is on the advanced tab pictured below - I have it unselected. After you remove the checkmark, reset the node and reconnect. Please report your results!
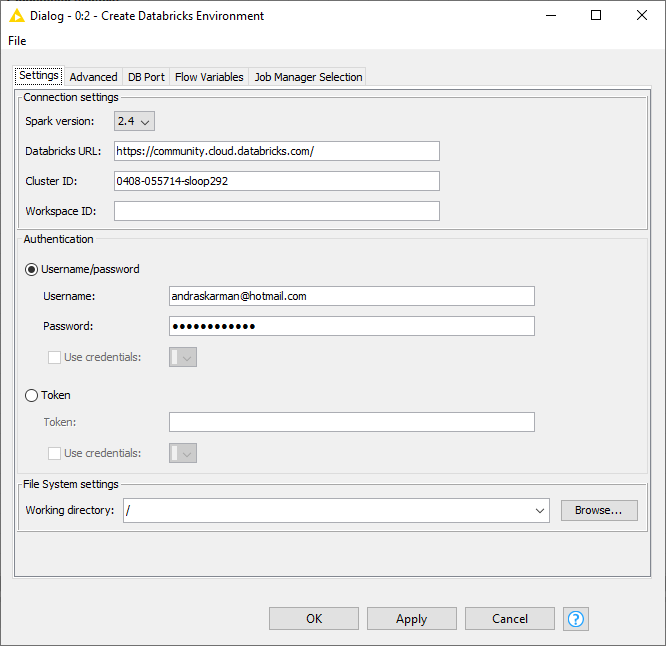
Make sure you enter the workspace ID. You can find them in the URL of your cluster: https://community.cloud.databricks.com/?o=57123456789181#setting/clusters/0408-12345-toots889/configuration
The Workspace ID is 57123456789181 in this example URL, the number behind the o=.
While testing this, some timeouts happens. Simply retry in this case. Note that the community edition is very limited and that the DB Loader might not work (DBFS seems to be broken in the community edition).
I have added the workspace ID but i still have the same error message:
java.lang.RuntimeException: ManagedLibraryInstallFailed: java.util.concurrent.ExecutionException: java.io.FileNotFoundException: /tmp/.knime-spark-staging-0409-092748-beep10/knime-spark-jobs-jar for library:JavaJarId(dbfs:///tmp/.knime-spark-staging-0409-092748-beep10/knime-spark-jobs-jar,NONE),isSharedLibrary=false
I have also asked the same on the Databricks forum but no answer as yet.
Thank you
Sorry for my short last post. There is no workaround on the Databricks File System problem and this means the Spark Context Port (Job Jar) and the DB Loader does not work on the Community Edition. That’s a Databricks problem that we can’t fix.
Great that you get the (limit) version running now