Hello everyone,
I created this workflow to extract data from the mess you see in the node monitor into what you see in the collected results window. My issue is that this table in the end comes from 6 different files (for which I need the list files and the loop) and each file starts counting the time from zero as you can see it at the beginning of the 2nd iteration. The time here should follow a continuous line as it does in reality, so the time in Row2#2 should be 1494.3467 + 0.01392 = 1494.36062 and so on. That means for each row in the time column the last time’s value from the previous iteration should be added starting from the 2nd iteration.
I was thinking if I could store that last time value in a flow variable at the end of the first iteration then, before ending the second loop, adding it to the whole time column, then replacing the flow variable with the new value from the end of the now summarized second iteratons last time value (should be around 3000 now).
I hope I was clear about my intentions, and thank you for any help in advance!
@BendegzHegedus as it happens we just had an example where an information from one loop has to be stored to be used in the new one via storing it in a temporary table. You might be able to adapt that:
Otherwise maybe you could provide use with sample data without spelling any secrets
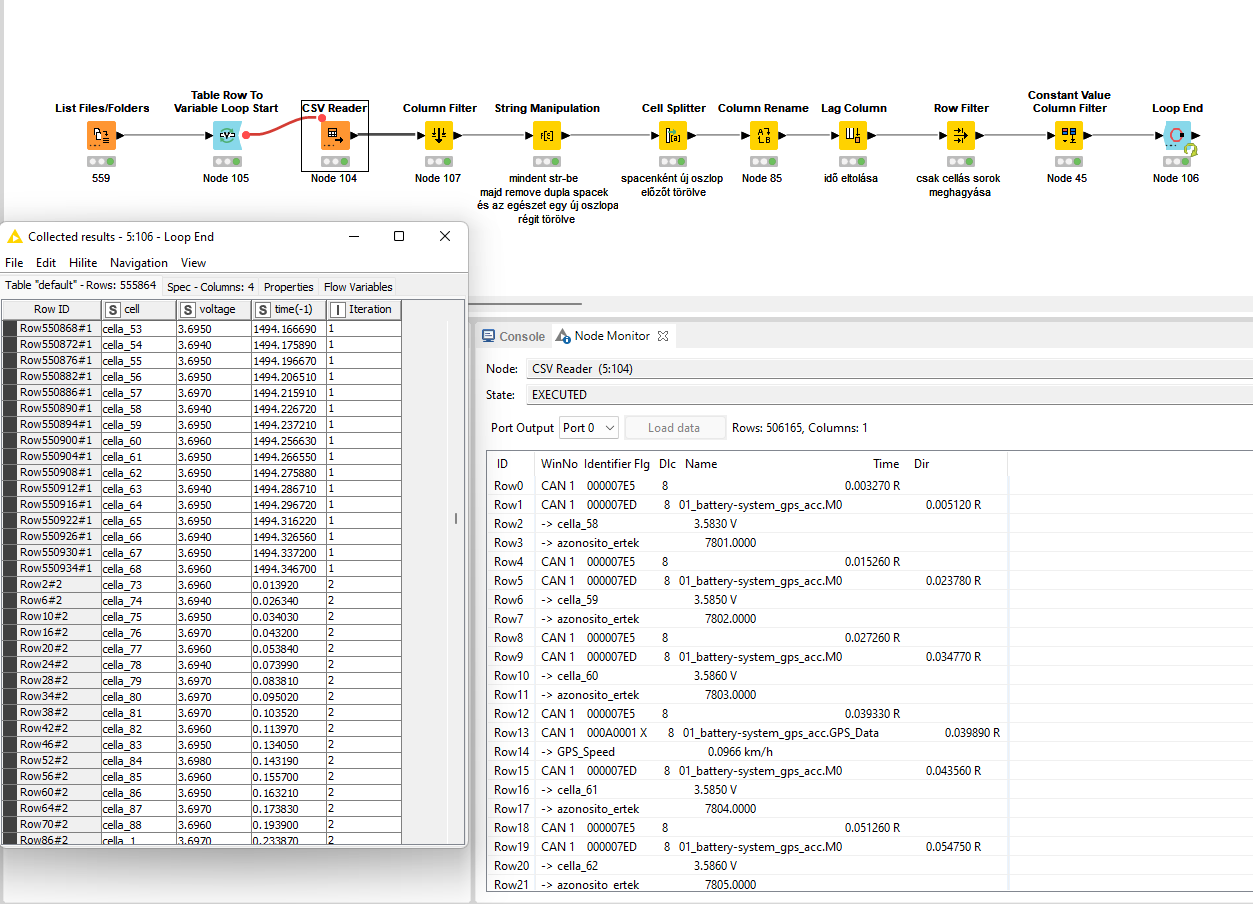
Hi @BendegzHegedus , you can definitely capture a value in a variable during an iteration that gets re-used in the next iteration. The Loop End node allows you to do that. You just need to use the “Propagate modified loop variables” option and the variables will keep their modified value for the next iteration:
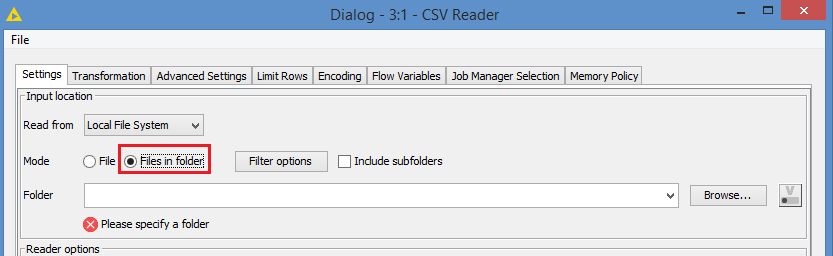
But the question that I have is why process these files 1 by 1 through a loop? If you open all 6 files at once, then you’ll get a big dataset, just like you would get at the end of the loop, except that it will be a continuous dataset, hence removing the problem you are facing.
You can open all 6 files as 1 dataset using the “Files in folder” option instead of the default “File” option:
It will also be faster without the loop.
Hi, thanks for the advice, I was trying with that idea for a while and i guess it could work but the solution from @bruno29a seems like it could bring the same outcome just simpler, isn’t it?
Hi,
thanks for the hint on propagate modified loop variables, I will check on that, but for the second one, if I open it all at once with files in folder, how could I modify the time values from each file? The idea is that after I read one file I store the last time value and add it for all the time values in the next file. If I instantly create a whole dataset, I will not be able to localize and store and add the value I need, and I could not know from which row should I add it to the next ones. Or maybe there is a way that I just don’t know? You think it would be possible?
That is always a possibility ![]() given my history with not getting the recursive loop construct. Maybe you could give it a try or provide us with an example so one could build a sample solution for your specific case.
given my history with not getting the recursive loop construct. Maybe you could give it a try or provide us with an example so one could build a sample solution for your specific case.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.