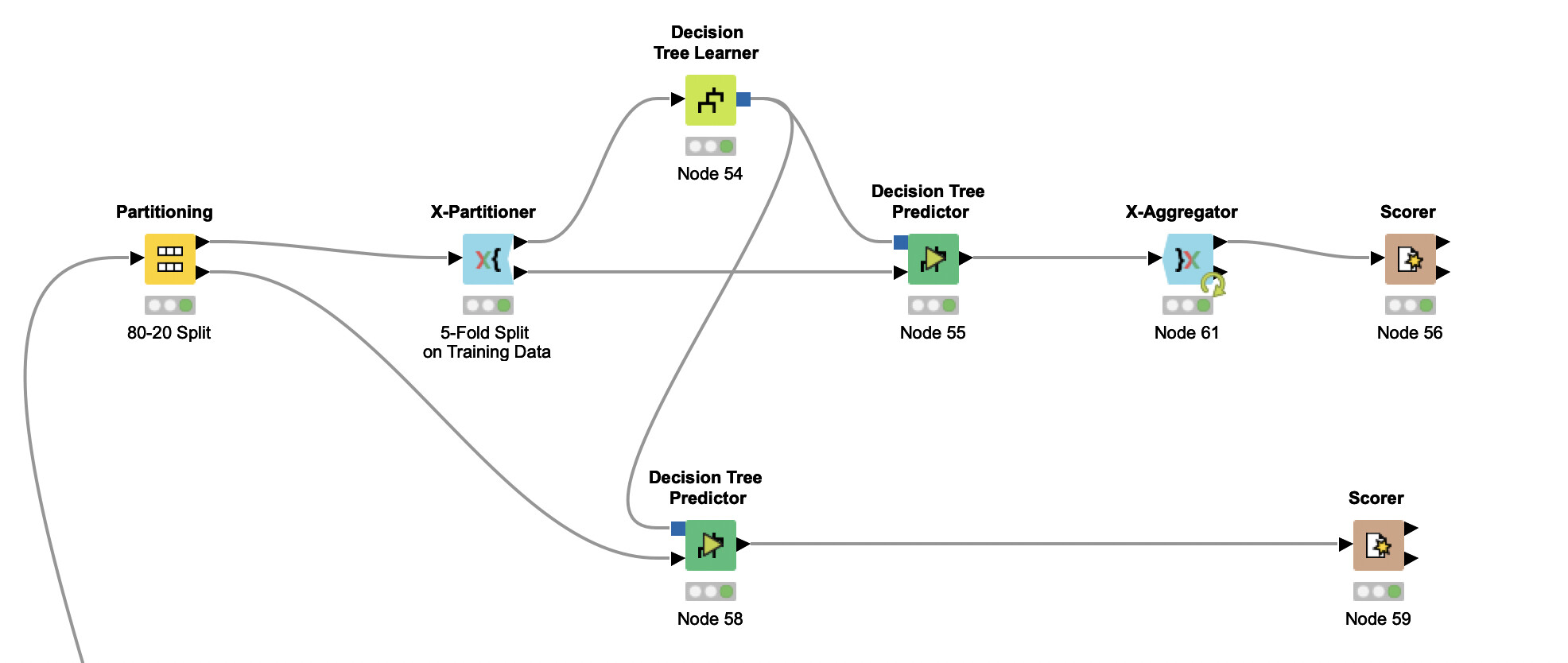
I am trying to develop and compare a Decision Tree Classification model with and without Cross-Validation. I have split the data into 80-20 training and testing. I have developed a normal Decision Tree Learner and Predictor on that data and got certain accuracy statistics.
Then, I used Cross-Validation (5-Fold) on 80% of the training data and developed a model as shown in the image. And then used that to test on the initial 20% of the data.
I had two doubts: 1. Is the workflow to check the model on the initial 20% Test data correct?
2. Is there any way to find out a score about what all variables are of importance to the model?
Hi,
normally CV does not require to use a separate testing dataset like in partitioning (train / test) as you would take the mean as your score. If you want to compare with the same test set it might make sense to do it on the same test split (as you have done i guess)
There is a node Decision Tree to rule set which should give you some info about the importance of a variable. The sooner it is used the higher the importance
hope that helps
edit: please take my word with a grain of salt. I am not a professional datascientist but rather a spare time neural network as a hobby guy
br