@MAAbdullah47 I have toyed around with your data and used some sample workflows and Jupyter notebooks I have recently provided in my machine learning space (mlauber71/Machine_Learning – ml_binary – KNIME Community Hub). Also I have compiled two reports with sweetviz and Pandas Profiler. As @aworker has said - your data might need more understanding and preparation as it stands and also maybe an inspection if the data provided can possibly contain the information you want.
Also if you want to learn more about machine-learning in gerenarl I have compiled a few ressources:
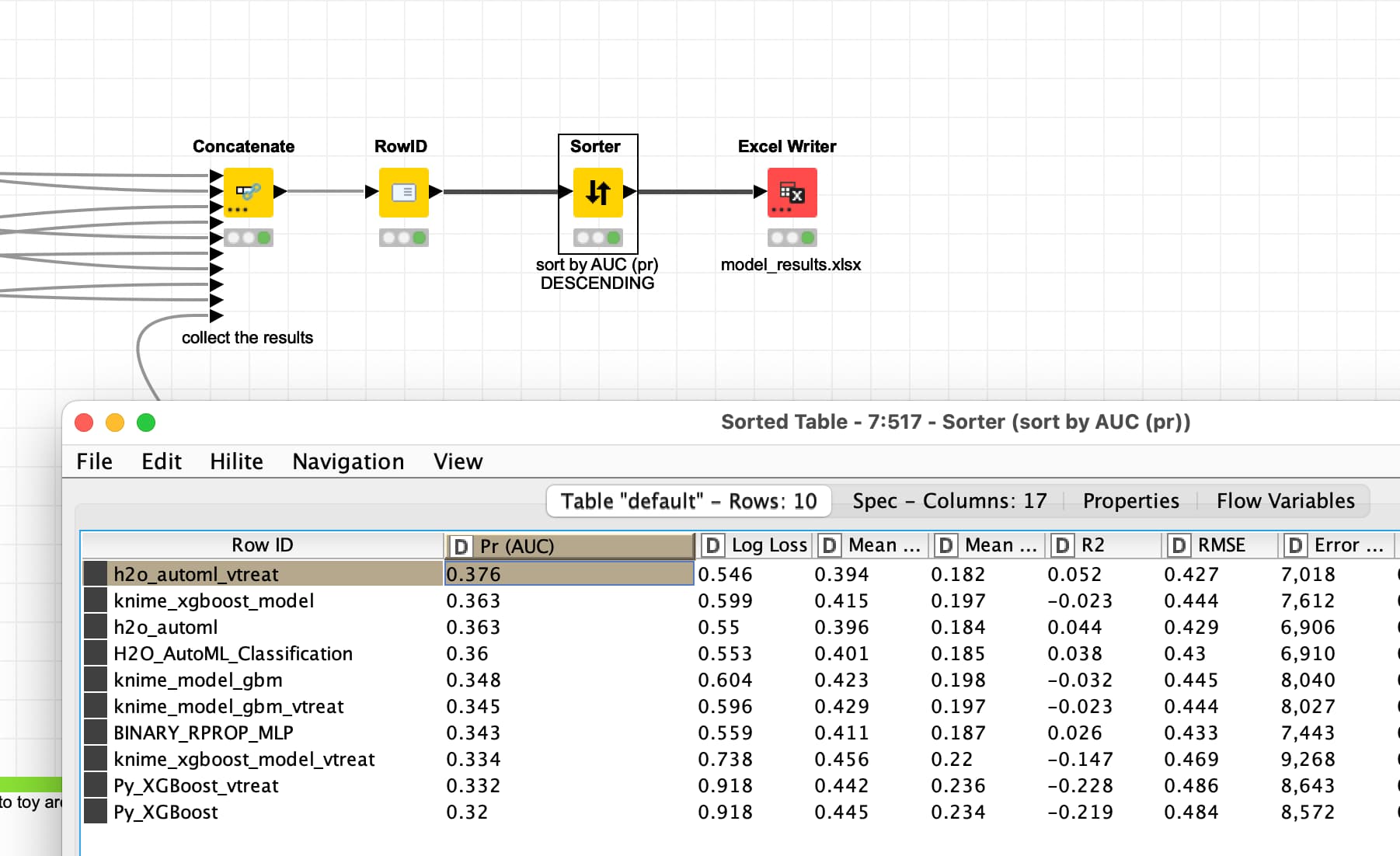
Then using the data provided these are the best outcome so far with using vtreat and H2O.ai AutoML combined. For a credit risk task they do not seem to be very good. Also you might clarify what the Target=1 would actually mean. Is this a default or just some risk? While being unbalance a 20%+ default rate on credit would seem very extreme for me:
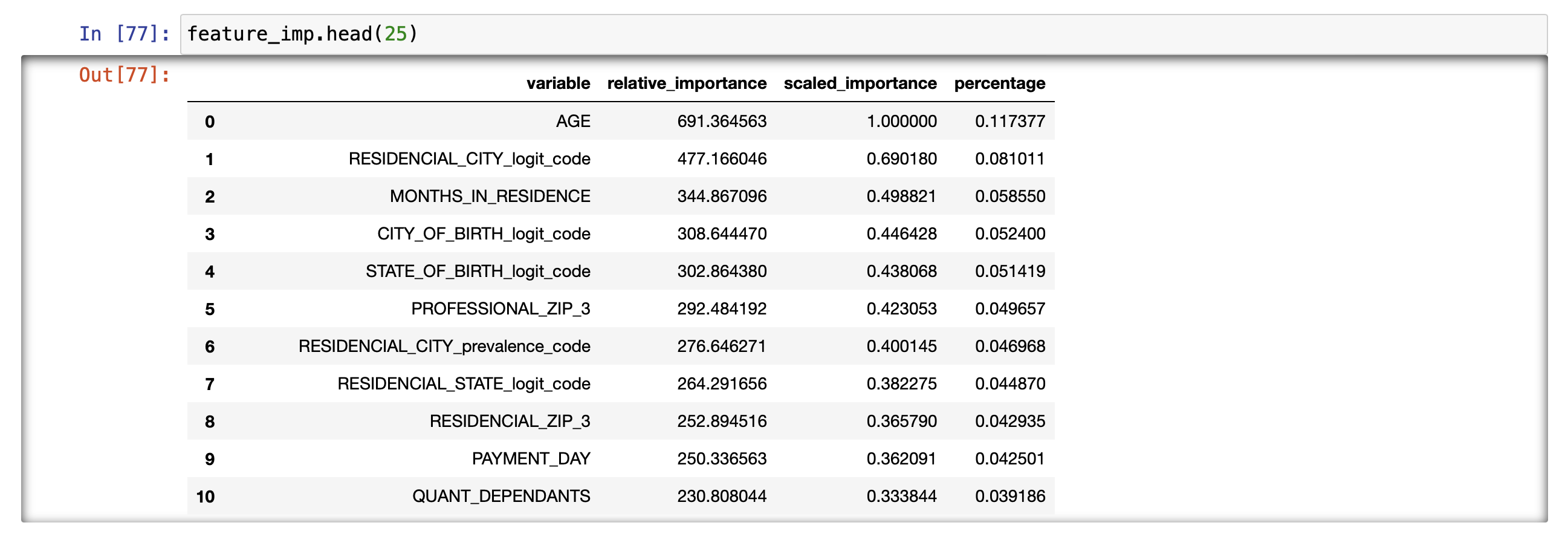
Age and regional variables seem to feature heavily wich might make sense.
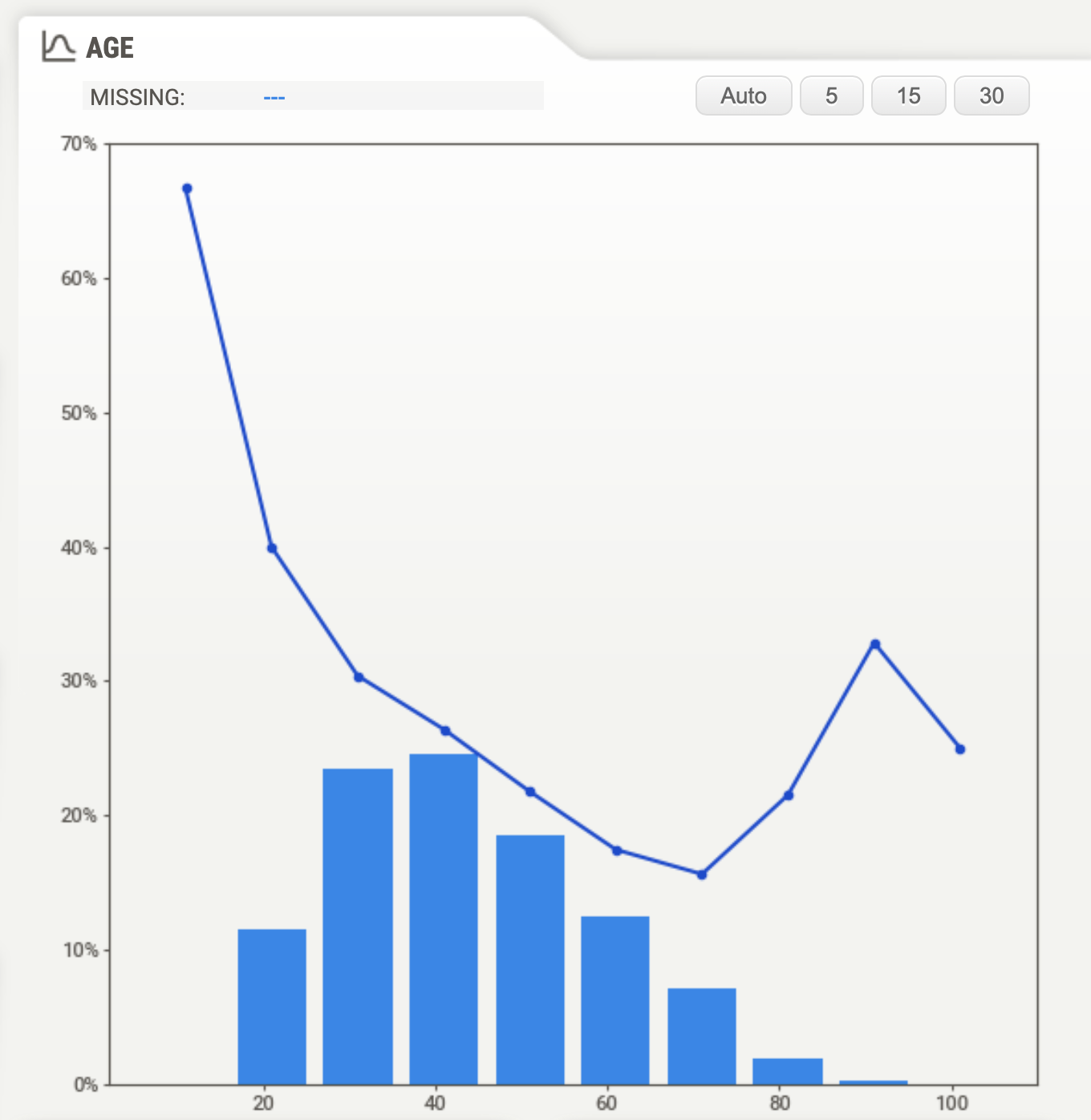
Age is shaped that very young and elderly people seem to be most at risk for credit default (which would make sense). The blue line in the sweetviz report representing the % of Target=1 per age group.
Also if you have a landline you run less risk of default.
I am not sure if employing SVM would make the model much better. The improvement thru using vtreat (Data preparation for Machine Learning with KNIME and the Python “vtreat” package | by Markus Lauber | Low Code for Data Science | Medium) might hint at the need to employ more data preparation, while the overall precision currently is not that good and the strong regional variables might need more attention if you would expect these patterns to hold or if you only have very small regional entities you might have to combine some. But here is the workflow I have adapted:
In the subfolder/data/notebooks/ there are more Jupyter notebooks to play around following ideas presented here: